




目录
1. LangGraph底层原理介绍
LangChain发展至现在,仍然是构建大语言模型应用程序的前沿框架之一。特别是在最新发布的v0.3版本中,已经基本完成了由传统类到表达式语言(LCEL)的重要过渡,给开发者带来的直接利好就是定义和执行分步操作序列(也称为链)更加简单。用更专业的术语来说,使用LangChain 构建的是 DAG(有向无环图)。而之所以会出现LangGraph框架,根本原因是在于随着AI应用(特别是AI Agent)的发展,对于大语言模型的使用不仅仅是作为执行工具,而更多作为推理引擎的需求在日益增长。这种转变带来的是更多的重复(循环)和复杂条件的交互需求,这就导致基于LCEL的线性序列构建方式在构建更复杂、更智能的系统时显示出了明显的局限性。如下所示的代码就是在LangChain中通过LECL表达式语言构建Chain的一种最简单的方式:
import getpass
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
llm = ChatOpenAI(model="gpt-4o")
prompt = ChatPromptTemplate.from_messages(
[
("system","You are a helpful assistant that translates {input_language} to {output_language}."),
("human", "{input}"),
]
)
chain = prompt | llm
chain.invoke(
{
"input_language": "English",
"output_language": "Chinese",
"input": "I love programming.",
}
)
AIMessage(content='我爱编程。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 5, 'prompt_tokens': 26, 'total_tokens': 31, 'prompt_tokens_details': {'cached_tokens': 0}, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_6b68a8204b', 'finish_reason': 'stop', 'logprobs': None}, id='run-8ba80a92-49ea-46d9-a049-256ff2b590a8-0', usage_metadata={'input_tokens': 26, 'output_tokens': 5, 'total_tokens': 31, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}})
反观LangGraph,顾名思义,LangGraph 在图这个概念上有很大的侧重,它的出现就是要解决线性序列的局限性问题,而解决的方法就是循环图。在LangGraph框架中,用图取代了LangChain的AgentExecutor(代理执行器),用来管理代理的生命周期并在其状态内将暂存器作为消息进行跟踪,增加了以循环方式跨各种计算步骤协调多个链或参与者的功能。这就与 LangChain 将代理视为可以附加工具和插入某些提示的对象不同,对于图来说,意味着我们可以从任何可运行的功能或代理或链作为一个程序的起点。上面过于专业描述可能理解起来比较困难,所以这里我们通过一个简单直观的场景来详细解释。
在以图构建的框架中,任何可执行的功能都可以作为对话、代理或程序的启动点。这个启动点可以是大模型的 API 接口、基于大模型构建的 AI Agent,通过 LangChain 或其他技术建立的线性序列等等,即下图中的 "Start" 圆圈所示。无论哪种形式,它都首先处理用户的输入,并决定接下来要做什么。下图展示了在 LangGraph 概念下,最基本的一种代理模型:
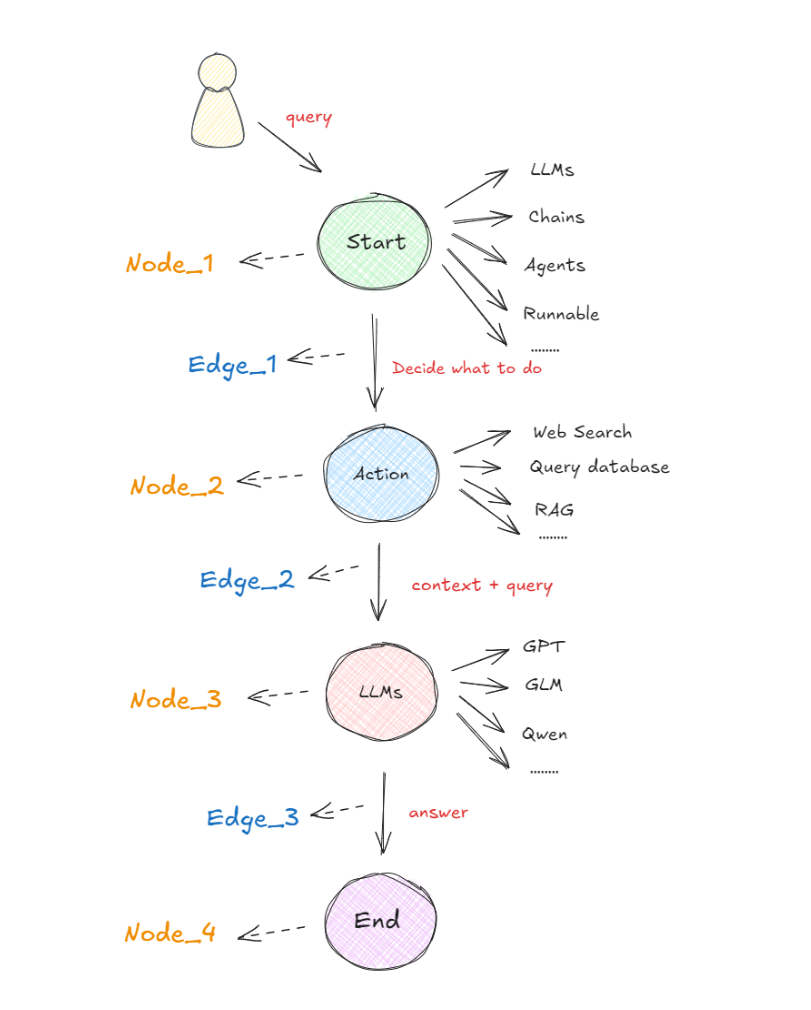
在启动点定义的可运行功能会根据收到的输入决定是否进行检索以及如何响应。比如在执行过程中,如果需要检索信息,则可以利用搜索工具来实现,比如Web Search(网络搜索)、Query Database(查询数据库)、RAG等获取必要的信息(图中的 "Action" 圆圈)。接下来,再使用一个大语言模型(LLM)处理工具提供的信息,结合用户最初传入的初始查询,生成最终的响应(图中的 "LLMs" 圆圈)。最终,这个响应被传递至终点节点(图中的 "End" 圆圈)。
上图所示的流程就是在LangGraph概念中一个非常简单的代理构成形式。关键且必须清楚的概念是:在这里,每个圆圈代表一个“节点”(Nodes),每个箭头表示一条“边”(Edges)。因此,在 LangGraph 中,无论代理的构建是简单还是复杂,它最终都是由节点和边通过特定的组合形成的图。这样的构建形式形成的工作流原理就是:当每个节点完成工作后,通过边告诉下一步该做什么,所以也就得出了:LangGraph的底层图算法就是在使用消息传递来定义通用程序。当节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。然后,这些接收节点执行其功能,将结果消息传递给下一组节点,然后该过程继续。如此循环往复。
这就是
LangGraph底层架构设计中图算法的根本思想。
接下来,我们再看一个更现实的复杂例子。
在这个示例中,我们将AI Agent定义为应用程序的起点。构建AI Agent代理通常涉及配置一个或多个工具,否则构建它就没有太大的意义,因为如果仅仅是针对用户的问题直接做响应,即使问题很复杂,我们也可以直接通过提示词来引导大模型进行推理。那么当AI Agent包含一些工具时,它是通过函数调用功能使用这些工具,而不是直接执行这些工具。所以当用户输入的原始问题经过AI Agent处理的时候,一般会出现以下两种情况:
- 如果不需要调用任何工具,
AI Agent会直接提供一个针对用户问题的自然语言响应。例如:- 用户:你好,请你介绍一下你自己。
- AI Agent:你好,我是一个人工智能助手,可以帮助你解决问题。
- 如果需要调用工具,则输出将是一个特定格式的 JSON 输出,指示进行特定的函数调用。例如:
- 输出示例:function': {'arguments': '{"query":"什么是快乐星球?"}','name': 'web_search'},'type': 'function'}
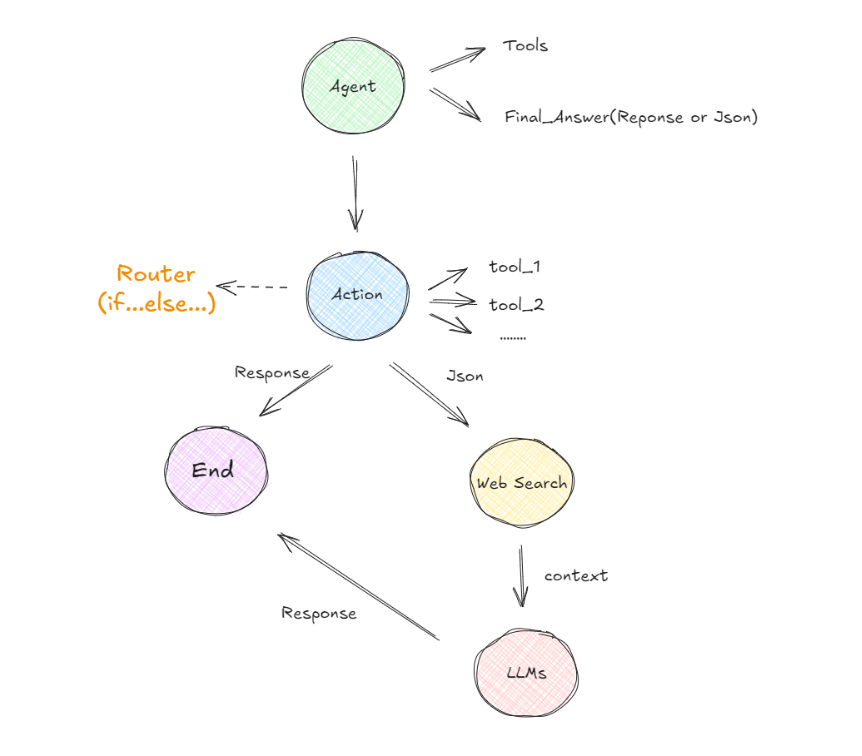
经过第一个节点后(Agent),如果AI Agent认为需要调用某个函数,它会确定使用哪个工具以及传递哪些参数。假设有多个工具可选的情况下,Action 节点将呈现多条可能的路径供选择。如何选择呢?这时候,LangGraph 引入了一个称为“条件边”的组件。条件边根据是否满足特定条件来决定走哪条路径,例如,代理可能需要决定是使用搜索工具还是直接生成最终答案。为了管理这些决策,则使用了一个类似于 if-else 语句的结构,称为Router。基于Router的决策,代理可能会导向“搜索节点”以执行搜索操作并返回原始文本,或者直接前往“最终答案节点”以获取格式化后的自然语言响应。如果选择了搜索路径,获取的答案文本还需通过另一个大语言模型进行处理,以生成用户可以理解的响应;若选择了直接回答,则可以使用一个专门的工具来格式化输出。
在 LangGraph 框架中,Rout
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









