




 本文详细介绍了Java中的Comparable和Comparator接口的区别,Comparable用于对象的内部排序,Comparator则提供外部排序功能。此外,文章讨论了Java的浅拷贝和深拷贝概念,以及序列化和反序列化的意义和应用场景。还涵盖了String、StringBuilder与StringBuffer的差异,以及Object类的重要方法。最后,讲解了Java异常处理机制,包括Exception和Error的分类,以及BIO、NIO、AIO三种I/O模型。
本文详细介绍了Java中的Comparable和Comparator接口的区别,Comparable用于对象的内部排序,Comparator则提供外部排序功能。此外,文章讨论了Java的浅拷贝和深拷贝概念,以及序列化和反序列化的意义和应用场景。还涵盖了String、StringBuilder与StringBuffer的差异,以及Object类的重要方法。最后,讲解了Java异常处理机制,包括Exception和Error的分类,以及BIO、NIO、AIO三种I/O模型。
语法
8.Comparable和Comparator的区别:
public interface Comparable<T>{//内部比较器,比较属性,静态绑定
public int compareTo(T o);
}
public interface Comparator<T>{//外部比较器,比较器,动态绑定
int compare(T o1,T o2);
boolean equals(Object obj);
}
(1)关于Comparable
Comparable对实现它的类的对象(可排序)进行整体排序,需要类本身去重写它的接口方法compareTo();
(2)关于Comparator
如果一个类已经没法修改,可以采用外部比较器Comparator。
具体可以参考,我的博客浅谈java自定义排序(多维排序)(数组,列表,set,map).
Java方法中参数传递机制(都是传递副本)
Java编程语言只有值传递。
- 如果参数类型是基本数据类型,那么传过来的就是这个参数值的副本,也就是这个原始参数的值,如果在函数中改变了副本的值不会改变原始的值。
- 如果参数类型是引用类型(对象的引用),那么传过来的就是这个引用参数的副本,这个副本存放的是参数的地址。如果在函数中没有改变这个副本的地址,而是改变了地址中的值,那么在函数内的改变会影响到传入的参数(比如:传入对象的引用,如果函数内对对象的属性进行修改,那么传入的对象属性发生改变)如果在函数中改变了副本的地址,如果new一个,那么副本就指向了一个新的地址,此时传入的参数还是指向原来的地址,所以会改变参数的值。
- 总之,不管传递什么类型的参数,都是传递的副本,原始类型就传递值的副本,引用类型就是传递地址的副本。
详情请看[为什么说java只有值传递](https://blog.youkuaiyun.com/qq_26542493/article/details/103898866).
9. Java中的浅拷贝和深拷贝。
区别:
浅拷贝:在拷贝对象时,只对基本数据类型进行拷贝,或对于引用数据类型的只是进行了引用地址的传递,而没有真实的在创建一个新的对象。
深拷贝:在对引用类型进行拷贝时,创建了一个新的对象,并且复制其内部的成员对象。
方法:
- 浅克隆:clone():只能克隆对象的基本数据类型(包括基本数据类型的包装类)和String类型的属性,引用类型仍然实在传递引用。
- 深克隆: 继续利用clone()方法:除了对当前对象的克隆,对其内的引用类型变量再进行一次克隆(即克隆对象持有的引用类型的class也实现Cloneable接口)。序列化这个对象,在反序列化回来,就可以得到一个新的对象,但是序列化规则需要我们写。
- 实现Cloneable接口的方式,坐浅度克隆还可以,但要做深度克隆的话,需要手动地将对象的引用类型进行单独克隆,维护起来比较麻烦,不适合实际当中使用。
10.什么是序列化和反序列化?
序列化:将对象写入到I/O流中,反序列化:从IO流中恢复对象。
意义:
序列化机制允许将实现序列化的Java对象转化为字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
使用场景:
所有可在网络上传输的对象都必须是可序列化的(引申:RPC机制),比如RMI(remote method invoke,即远程方法调用)、RPC调用,传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的Java对象都必须是可序列化的。
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的JavaBean都实现Serializable接口。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。如果想让某个变量不被序列化,使用transient修饰。
- 序列化对象的引用类型成员变量,也必须是可序列化,否则,会报错。反序列化时必须有序列化对象的class文件。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID版本号,方便项目升级。(如果反序列化使用的class的版本号与序列化时使用的不一致,反序列化会报InvalidClassException异常)
13.String和StringBuilder、StringBuffer的区别
String是不可变字符串对象(final的char数组),StringBuilder和StringBuffer(线程安全,是因为synchronized修饰了方法)是可变字符串对象(其内部的char数组长度可变)。(底层区别在是否是final修饰的char数组,推荐看下源码)
当字符串相加操作或者改动较少的情况下,建议使用String str=“hello”这种形式;
当字符串相加操作较多的情况下(2个以上),建议使用StringBuilder,如果采用了多线程,则使用StringBuffer(内部的方法是利用synchronized修饰的)。
具体可以参考:String、StringBuffer、StringBuilder源码解析
14.object类有哪些方法?
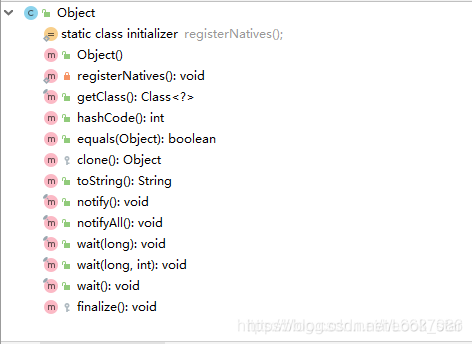
1.getClass()
final,native方法,获得运行时类型。
2.hashCode()
hashCode()方法主要用于hash表,比如HashMap,当集合要添加元素时,大致按如下步骤:
- 先调用该元素的hashCode()方法获取hashCode,hashCode对数组取模定位到它应该放置的物理位置
- 如果这个位置上没有元素,就直接存储在这个位置上
- 如果这个位置上已经有元素,就调用equals()方法进行比较,相同的话就更新,不相同的话放到链表后面
所以重写equals()方法时,也必须重写hashCode()方法。如果不这样做,就会违反Object.hashCode()的规范,导致无法结合所有基于hash的集合一起正常运作,这样的集合包括HashMap、HashSet和Hashtable
那为什么不直接使用equals()进行操作呢?如果只使用equals(),意味着需要迭代整个集合进行比较操作,如果集合中有1万个元素,就需要进行1万次比较,这明显不可行
3.equals(obj)
该方法是非常重要的一个方法。一般equals和==是不一样的,但是在Object中两者是一样的。子类一般都要重写这个方法。
4.clone()
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
5.toString()
该方法用得比较多,一般子类都有覆盖。
6.notify()
该方法唤醒在该对象上等待的某个线程。
7.notifyAll()
该方法唤醒在该对象上等待的所有线程。
8.wait()
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
- 其他线程调用了该对象的notify方法。
- 其他线程调用了该对象的notifyAll方法。
- 其他线程调用了interrupt中断该线程。
- 时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常
9.wait(long)
wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
10.wait(long, int)
在纳秒级别进行更精细的等待控制,一般用不到。
11.finalize()
该方法用于释放资源。因为无法确定该方法什么时候被调用。如果你想使用这个方法,百度一下相关的内容,然后不要使用它
wait,notify,notifyAll就是线程之间用来通信的工具
16. java异常体系
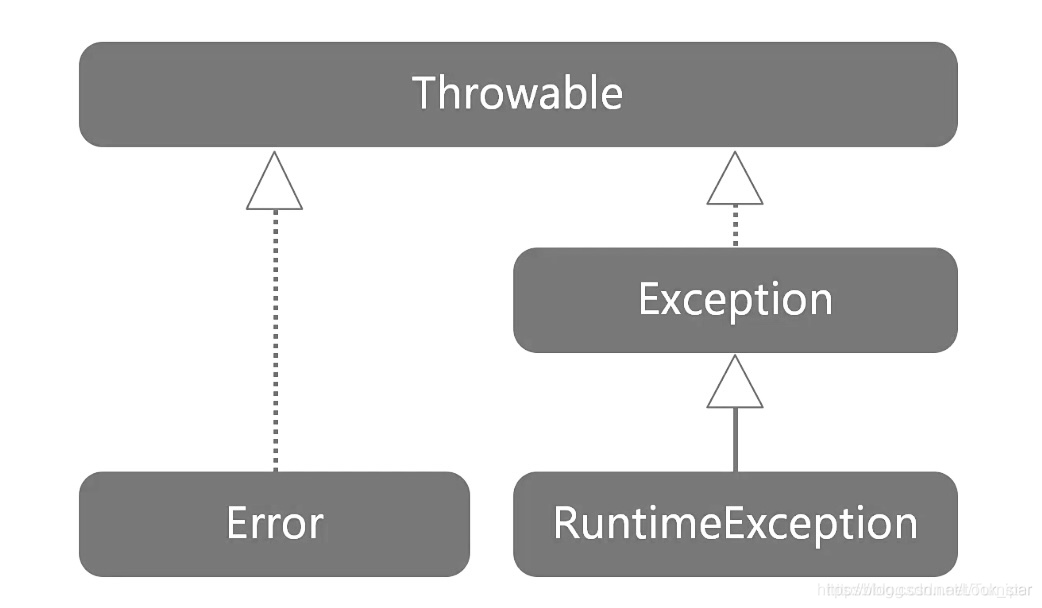
Java中的异常分为Exception和Error。
Error
Java中的定义不可控制,无法预期的错误出现。比如说在系统中出现了内存溢出,系统崩溃,虚拟机错误,方法调用栈溢出等等。这里的错误通常都会导致程序的中断,同时仅仅靠程序本身它是无法恢复和预防的。也就是说Error这个级别,是在我们应用程序之上,通常是操作系统级别的,所以对于Error来说,通常的做法就是中断程序的运行。
Exception
异常
所谓异常通常是指可以被我们捕捉到的这部分错误。 例如:除法中出现了分母为0,我们就可以用try/catch进行捕捉和处理。同时对于异常来说,它通常都是可以被恢复的(也就是说对于程序是可控的)如果出现了异常我们可以对它进行补救。这便是异常和错误之间的区别。
Exception分为RuntimeException(运行时异常)和编译异常。
两者区别:
运行时异常:RuntimeException及其子类表示JVM在运行期间可能出现的错误。比如试图使用空值对象的引用(NullPointerException)、数组下标越界(ArrayIndexOutBoundException)。此类异常属于不可查异常,一般是程序逻辑错误引起的,在程序中可以选择捕获处理,也可以不处理。
编译异常:RuntimeException之外的异常,如果程序出现此类异常,比如说IO异常,必须对该异常进行处理(try catch ,throw),否则编译不通过。


















 847
847




 到【灌水乐园】发言
到【灌水乐园】发言







