




随着人工智能技术的飞速发展,视觉-语言(Vision-Language, VL)多模态模型已成为AI领域的新热点。然而,传统的多模态模型训练往往面临算力需求大、技术门槛高、环境配置复杂等挑战。
通过创新的"拼接微调"技术以及SwanLab 的实验追踪与可视化助力,将SmolVLM2的视觉模块与Qwen3-0.6B模型进行对齐微调,让学习者能够亲手构建具备视觉理解能力的多模态模型,并通过借助 SwanLab 记录微调过程中的关键指标与效果变化,直观感受多模态模型的构建与优化轨迹。
实操背景介绍
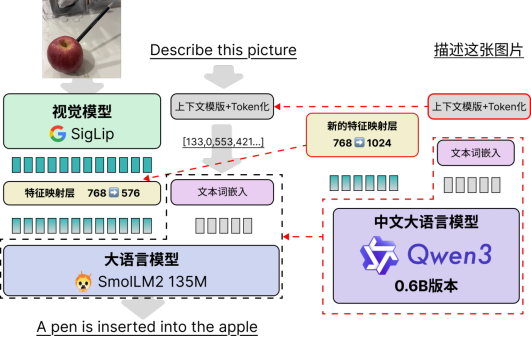
SmolVLM2是一个超小多模态模型,具有极强的视觉文本理解能力。为了让模型也能理解中文,SwanLab团队提出一种模型拼接的思路,将SmolVLM2的视觉模块(0.09B)与Qwen3最小的模型(0.6B)进行对齐微调,最终使得Qwen模型具备一定的视觉理解能力。
模型拼接的思路其实非常直接,可以概括为三步:
① 调整SmolVLM2的“上下文控制格式”,使得其与Qwen3兼容。
② 将模型的文本部分直接从SmolLM2换成Qwen3-0.6B,包括其文本tokenizer和词嵌入、文本模型、以及模型最后输出的语言模型头(LM Head)。
③ 需要重新初始化特征映射层的MLP,从768->576的单层神经网络改成768->1024的单层神经网络即可。
整体架构和对图文对前后处理依旧保持SmolVLM2的流程不变,具体改动见下图:
快速体验
说了这么多,不如直接上干货!在Lab4AI大模型实验室上跑通 Qwen3-VL 训练只需5步,全程可视化,成就感拉满~
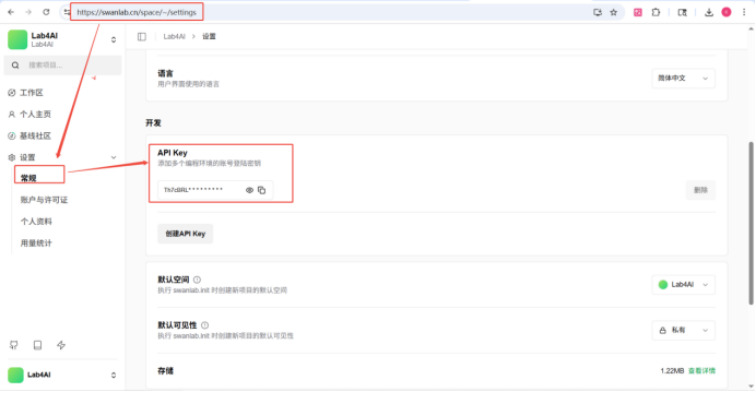
Step1:前置准备
本次实验的相关代码、数据、环境均已内置在Lab4A大模型实验室,可直接使用。使用前,请确保您已拥有SwanLab账号,并在https://swanlab.cn/settings页面获取您的 API Key。
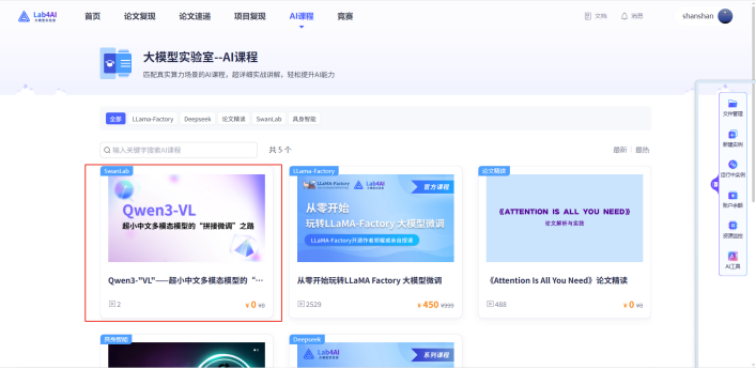
Step2:学习课程
登录Lab4AI大模型实验室(https://www.lab4ai.cn/course/detail?utm_source=swanlab2&id=5b15f2313d2c472e866d66279bd1d914 ),找到【Qwen3-"VL"——超小中文多模态模型的“拼接微调”之路】课程。
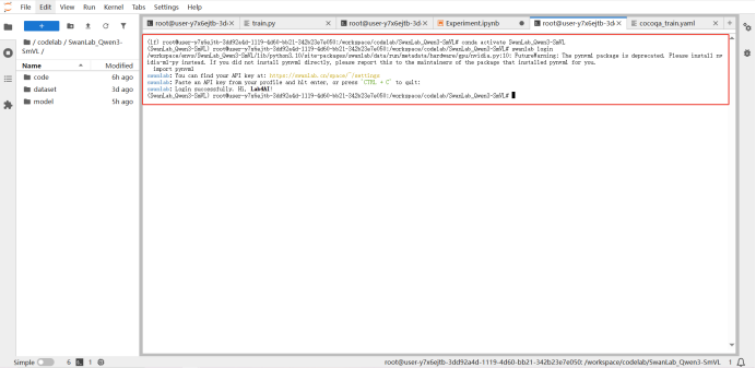
Step3:配置SwanLab监控
执行 conda activate SwanLab_Qwen3-SmVL 激活虚拟环境后,运行 swanlab login 以配置SwanLab监控。
Step4:小批量微调训练
您需要在terminal中执行 python train.py ./cocoqa_train.yaml 运行小规模训练实验。
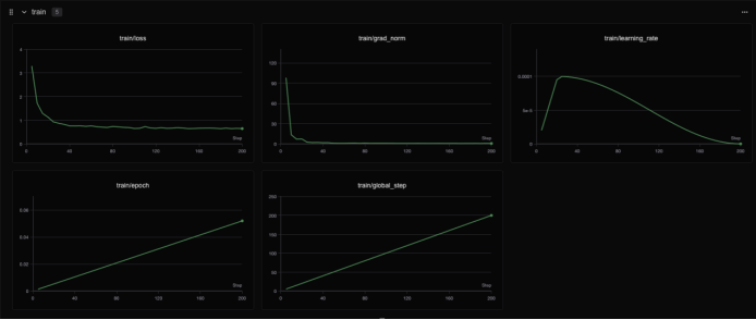
实验完成后,您可在SwanLab中可视化查看训练情况,在单张H800上进行训练,预期耗时7-8分钟。Lab4AI大模型实验室公开了在SwanLab上的训练结果,
(链接直达:https://swanlab.cn/@Lab4AI/Qwen3-SmVL/overview)
感兴趣的读者可以自己查看。
Step5:完整微调训练
如果您想体验完整微调训练,您可以使用accelerate运行多卡分布式训练,完整训练大致需要30分钟。
通过Lab4AI大模型实验室平台,我们成功实现了Qwen3-"VL"多模态模型的拼接微调训练,突破了传统多模态模型训练的技术壁垒。Lab4AI大模型实验室则通过“算力 + 工具 + 社区”的深度融合,将原本高门槛的 VLM 训练变得触手可及。



















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









