



从帧到世界:面向世界模型的长视频生成
世界模型是一种能够“看懂”现实世界规则并“预测”其动态变化的生成式AI,例如理解“抛球会落地”或“太阳东升西落”等常识。其技术本质是通过大量数据学习物理规律、因果关系和时空逻辑,形成兼具“认知”与“预测”能力的模型框架。
视频生成不只是拼接现有素材,而是由AI从文本、图像或语音等输入出发,自主生成连续且连贯的视频帧序列,核心在于保证画面在时间和空间上的一致性与连续性。
当视频生成技术面向世界模型时,其目标就不再是单纯地制造画面,而是要求生成的内容必须契合世界模型对现实世界的认知逻辑。这意味着生成的视频需要具备高度的物理合理性、时空连贯性以及长程可预测性,以支撑世界模型进行更深入的推理与交互。
为了实现这一目标,Macro-from-Micro Planning(MMPL) 作为一种有效的生成策略被提出。它通俗地理解为一种先微观后宏观的规划方法:即先从微观细节(如单帧或短片段)中学习基本规律,再上升到对宏观(整个长视频)的时空逻辑进行整体规划,旨在有效避免局部细节与整体逻辑之间出现脱节。
视频生成的两大核心挑战
从世界模型的角度来看,视频生成必须满足一个核心要求:生成的内容要符合现实世界的逻辑。这就带来了两个关键挑战。
第一个是空间一致性
简单说,就是视频里物体的样子、位置和大小得始终对得上。比如一个人在走路,不能前一秒头在左边,下一秒突然跑到右边;一个杯子也不能一会儿大一会儿小。但传统方法常常控制不好这一点,容易出现物体乱飘或者场景突变的问题,这显然不符合我们对真实世界的认知。
第二个是长程依赖,也就是视频的整个故事或过程要有连贯的逻辑
举个例子,如果AI要生成一段“煮面条”的视频,就得按顺序来:先加水、再点火、下面条、等煮熟、最后捞出来,不能跳过步骤,更不能前半段还在厨房烧水,后半段突然人就出现在户外了。然而,传统模型很难同时记住并协调几百甚至上千帧之间的关系,导致视频中途断片或逻辑混乱。这两个问题,正是当前视频生成技术必须攻克的硬骨头。
Lab4AI.cn提供实验平台,提供一站式科研工具链!
👉一键直达
为何需要新范式
传统视频生成方法,尤其是“自回归”方式,存在两个根本性问题,让它们很难满足世界模型对真实性和效率的要求。
第一个问题是“时域漂移”——意思是视频越往后生成,内容就越容易跑偏。比如你让它生成“小狗追蝴蝶”,开头几十帧还挺正常,但再往后,小狗可能莫名其妙变成了小猫,或者蝴蝶直接消失了。这是因为自回归模型是一帧接一帧、按顺序生成的,每一步都依赖上一步的结果,而微小的误差会像滚雪球一样不断累积,最后导致整个视频偏离最初的设定,违背了世界模型所要求的稳定、一致的认知逻辑。
第二个问题是“串行推理瓶颈”——由于必须等前一帧完全生成后才能开始下一帧,整个过程没法并行加速,导致生成一段1分钟的视频可能要花上几个小时。这种线性、缓慢的方式,根本无法支持世界模型所需要的快速预测和实时交互,比如想让AI立刻模拟出“接下来10秒物体怎么动”,传统方法就力不从心了。正因如此,才迫切需要一种全新的技术范式来突破这些限制。
MMPL 方法与新架构的核心逻辑
南京大学范琦团队提出的 Macro-from-Micro Planning (MMPL),是一种全新的长视频生成方案,专门为了解决传统AI生成视频时“时间长就内容跑偏”和“生成速度太慢”这两个核心痛点。

论文名称:Macro-from-Micro Planning for High-Quality and Parallelized Autoregressive Long Video Generation
它把整个过程分成两个阶段:先规划,后填充。
首先,在每个短视频片段里预测几个关键帧(比如动作的起点和终点),这叫“微观规划”;然后,用一条连贯的故事线把这些片段的关键帧串起来,确保整段视频从头到尾逻辑一致,这叫“宏观规划”。有了这些规划好的关键帧,系统就可以同时、并行地生成所有中间画面,不再需要傻等前一帧完成,大大提升了速度。
这项技术有几个关键创新:
通过“全局+局部”双层规划,既保证了长视频的整体连贯性,又避免了内容慢慢跑偏;利用多块GPU并行工作,生成速度比原来快了80%以上,4块GPU下推理时间甚至缩短到原来的三分之一;还巧妙结合了自回归模型的时间连贯性和扩散模型的画面精细度,让视频既流畅又高清。
实测结果显示,MMPL 在多个权威指标上都做到了最好——比如角色不会突然变形(主体一致性达0.980)、动作丝滑自然(运动平滑度0.992),人类评测也认为它在内容对得上文字、前后不矛盾、颜色稳定等方面全面领先。更重要的是,它能稳定生成30秒以上的高质量视频,彻底解决了传统模型“开头惊艳、后面崩坏”的问题。
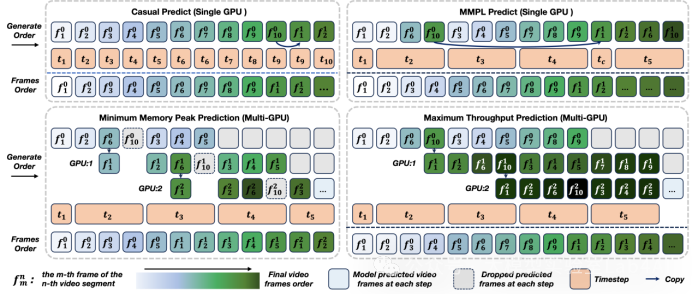
而这一切,不只是为了做出更好看的视频——MMPL 实际上是为世界模型量身打造的。世界模型要理解并预测现实世界,就需要大量符合物理规律、逻辑连贯的长视频作为“训练素材”或“模拟环境”。MMPL 正好提供了这种能力:它的宏观规划机制能模拟世界状态如何随时间演变,生成的视频既能反映真实的时空逻辑,又能支撑世界模型进行更准确的推理和交互。换句话说,MMPL 不只是视频生成工具,更是构建下一代智能体“认知世界”的关键基础设施。


















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









