








本文确定了GFM的三个关键理想属性:自监督预训练、任务中 的流动性和图感知。为了考虑这些特性,本文将传统的语言建模扩展到 图领域,提出了一种新的生成图语言模型GOFA 来解决该问题。该模型将 随机初始化的GNN层交织到冻结的预训练LLM中,以便将语义和结构建 模能力有机结合。GOFA 对新提出的图级下一个单词预测、问答和结构任 务进行了预训练,以获得上述GFM属性。预训练模型在下游任务上进一 步微调,以获得任务解决能力。在各种下游任务上对微调模型进行了评 估,显示了在零样本场景中解决结构和上下文问题的强大能力。
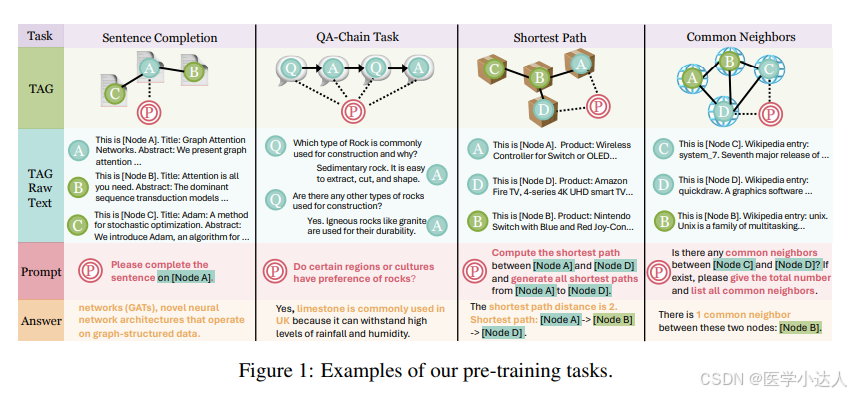


大规模自监督训练,流式任务,图结构理解
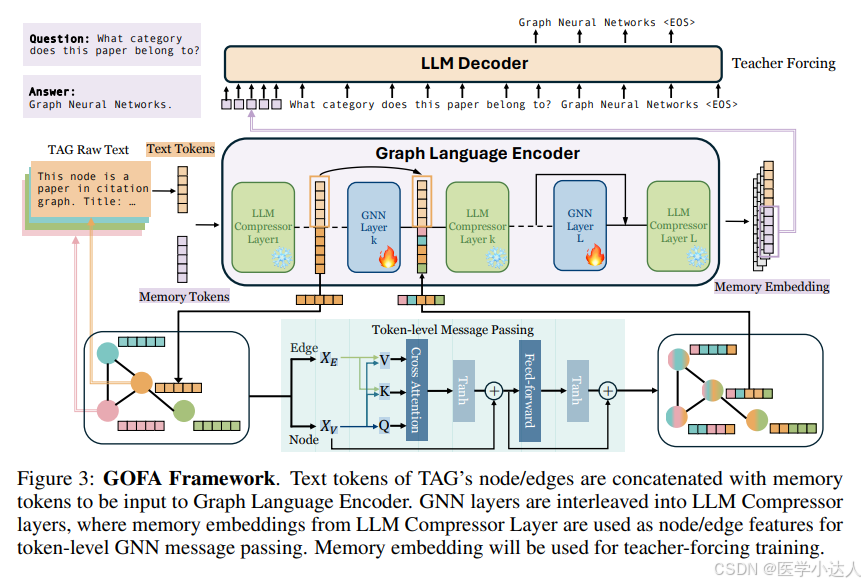
本文模型分为三部分:
LLM压缩层:将文本和graph压缩为固定长度的向量表示,其实是压缩的文本然后拼接的图嵌入;
Token-level的GNN层:其实就是RGAT,将带有边信息的x输入到模型里面,经过GAT层,得到的输出继续拼接上层LLM的输出,所谓下一层的输入;
LLM解码层:将graph language encoder的输出输入到LLMs的decoder,进行sft。




训练规模:
句子补全:将TAG中的文本进行截断,后面的作为标签,去训练句子补全任务;
图结构理解任务:依据图结构,进行最短路径以及邻居节点的相关推理任务;
图问答任务:基于图信息,用问答数据集进行问答的sft。


相关工作:
图prompt的学习;LLM作为增强器;LLM作为预测器

模型代码 model.py
from collections import namedtuple, OrderedDict
import torch
import numpy as np
from gp.nn.models.GNN import MultiLayerMessagePassing
from gp.nn.layer.pyg import RGCNEdgeConv
from gp.nn.layer.pyg import TransformerConv as MConv
from .helper import GOFALlamaHelper, GOFAMistralHelper, LlamaHelper
LLM_DIM_DICT = {"ST": 768, "BERT": 768, "e5": 1024, "llama2_7b": 4096, "llama2_13b": 5120, "mamba": 768, "icae": 4096,
"icae_mem": 4096}
def print_fixed_length(text, line_width=120):
t_pointer = 0
while t_pointer < len(text):
t_pointer += line_width
t_cur_text = text[t_pointer - line_width:t_pointer]
print(t_cur_text)
def print_text_side_by_side(text_1, text_2, line_width=120, space=10):
t1_len = len(text_1)
t2_len = len(text_2)
seg_width = int((line_width-space)/2)
t1_pointer = 0
t2_pointer = 0
text_1 = text_1.replace('\n', ' ').replace('\r', ' ')
text_2 = text_2.replace('\n', ' ').replace('\r', ' ')
while t1_pointer<t1_len or t2_pointer<t2_len:
t1_pointer += seg_width
t2_pointer += seg_width
t1_cur_text = text_1[t1_pointer-seg_width:t1_pointer]
t2_cur_text = text_2[t2_pointer-seg_width:t2_pointer]
t1_cur_text = t1_cur_text + " "*(seg_width-len(t1_cur_text))
t2_cur_text = t2_cur_text + " "*(seg_width-len(t2_cur_text))
full_text = t1_cur_text + " "*space + t2_cur_text
print(full_text)
class GOFA(torch.nn.Module):
def __init__(self, transformer_args, mode="autoencoder", base_llm="llama7b", save_dir=""):
super().__init__()
self.mode = mode
self.save_dir = save_dir
if base_llm == 'llama7b':
self.llm_model = GOFALlamaHelper(transformer_args)
elif base_llm == 'mistral7b':
self.llm_model = GOFAMistralHelper(transformer_args)
elif base_llm == 'llama7blora' or 'mistral7blora':
self.llm_model = LlamaHelper(transformer_args)
else:
raise NotImplementedError(base_llm + " is not supported. Please choose from: llama7b, mistral7b,")
if mode == "autoencoder":
self.encode = self.auto_encode
self.decode = self.auto_decode
elif mode == "autoencodergen":
self.encode = self.auto_encode
self.decode = self.generate
elif mode == "direct":
self.encode = self.direct_decode
self.decode = lambda x: x
elif mode == "nograph":
self.encode = self.llm_decode
self.decode = lambda x: x
elif mode == "nographgen":
self.encode = self.llm_gen
self.decode = lambda x: x
else:
# TODO: not implemented
raise NotImplementedError(mode + " mode not implemented")
def llm_decode(self, g):
text_inputs = g.x[g.node_map.cpu().numpy()][g.question_index.cpu().numpy()].tolist()
com_text_inputs = []
for i in range(len(text_inputs)):
t = text_inputs[i] + g.question[i]
com_text_inputs.append(t)
answer_texts = g.answer[g.answer_map.cpu().numpy()].tolist()
answer_logits, answer_id, masks = self.llm_model(answer_texts, com_text_inputs)
GNNLMOutput = namedtuple("GNNLMOutput", ["logits", "answer_id", "pred_text", "answer"])
return GNNLMOutput(logits=answer_logits[masks], pred_text=self.logit_to_text(answer_logits, masks),
answer_id=answer_id, answer=answer_texts)
def llm_gen(self, g):
text_inputs = g.x[g.node_map.cpu().numpy()][g.question_index.cpu().numpy()].tolist()
com_text_inputs = []
for i in range(len(g.question)):
# t = '[INST]\n' + g.question[i] + '\n[/INST]\n\n'
if len(text_inputs) == len(g.question):
t = '[INST]\n' + text_inputs[i] + g.question[i] + 'Please only answer the category name, no other information or explanation. \n[/INST]\n\n'
elif len(text_inputs) == len(g.question) * 2:
t = '[INST]\n' + text_inputs[2*i] + text_inputs[2*i+1] + g.question[
i] + 'Please only answer the category name, no other information or explanation. \n[/INST]\n\n'
elif len(text_inputs) > len(g.question):
t = '[INST]\n' + g.question[i] + 'Please only answer the category name, no other information or explanation. \n[/INST]\n\n'
else:
raise ValueError('Text_input length did not match question length.')
com_text_inputs.append(t)
answer_texts = g.answer[g.answer_map.cpu().numpy()].tolist()
generated_text = self.llm_model.generate(com_text_inputs)
for i, txt in enumerate(generated_text):
print_fixed_length(f"question: {com_text_inputs}")
print("-" * 120)
print_text_side_by_side("target: " + answer_texts[i], "gen: " + generated_text[i])
print("=" * 120)
GNNLMOutput = namedtuple("GNNLMOutput", ["logits", "answer_id", "pred_text", "answer"])
return GNNLMOutput(logits=torch.randn([1, 32132]), pred_text=generated_text, answer_id=torch.tensor([1]),
answer=answer_texts)
def auto_encode(self, g):
g.num_node_feat = g.x.shape[0]
if g.edge_attr is not None:
text_inputs = np.concatenate([g.x, g.edge_attr], axis=0)
else:
text_inputs = g.x
llm_output = self.llm_model.encode(text_inputs.tolist(), graph=g, partial_grad=True)
g.x = llm_output[:g.node_map.size(-1)]
return g
def auto_decode(self, g):
emb = g.x
answer_texts = g.answer[g.answer_map.cpu().numpy()].tolist()
prompt_texts = g.question[g.question_map.cpu().numpy()].tolist()
emb = emb[g.question_index]
answer_logits, answer_id, masks = self.llm_model.decode(answer_texts, emb, prompt=prompt_texts)
GNNLMOutput = namedtuple("GNNLMOutput", ["logits", "answer_id", "pred_text", "answer"])
return GNNLMOutput(logits=answer_logits[masks], pred_text=self.logit_to_text(answer_logits, masks),
answer_id=answer_id, answer=answer_texts)
def generate(self, g):
emb = g.x
answer_texts = g.answer[g.answer_map.cpu().numpy()].tolist()
prompt_texts = g.question[g.question_map.cpu().numpy()].tolist()
emb = emb[g.question_index]
generated_text = self.llm_model.generate(emb, prompt=prompt_texts)
for i, txt in enumerate(generated_text):
print_fixed_length("question: " + prompt_texts[i])
print("-"*120)
print_text_side_by_side("target: "+answer_texts[i], "gen: "+generated_text[i])
print("="*120)
GNNLMOutput = namedtuple("GNNLMOutput", ["logits", "answer_id", "pred_text", "answer"])
return GNNLMOutput(logits=torch.randn([1, 32132]).to(emb.device), pred_text=generated_text, answer_id=torch.tensor([1]).to(emb.device),
answer=answer_texts)
def forward(self, g):
g = self.encode(g)
return self.decode(g)
def direct_decode(self, g):
num_node_feat = g.x.shape[0]
g.num_node_feat = num_node_feat
g.x = g.x[g.node_map.cpu().numpy()]
answer_texts = g.answer.tolist()
answer_logits, answer_id, masks = self.llm_model(g.x.tolist(), answer_texts, g.edge_attr.tolist(), graph=g,
partial_grad=True)
GNNLMOutput = namedtuple("GNNLMOutput", ["logits", "answer_id", "pred_text", "answer"])
return GNNLMOutput(logits=answer_logits[masks], pred_text=self.logit_to_text(answer_logits, masks),
answer_id=answer_id, answer=answer_texts)
def save_partial(self, save_dir):
state_dict = self.llm_model.model.icae.model.model.g_layers.state_dict()
full_state_dict = self.state_dict()
for k in full_state_dict:
if "default" in k:
state_dict[k] = full_state_dict[k]
torch.save(state_dict, save_dir)
def load_partial(self, load_dir=None, state_dict=None):
if load_dir is not None and state_dict is not None:
raise RuntimeError("You should only specify either load_dict or load_dir")
if load_dir is None and state_dict is None:
print("No state dict loaded")
return
if load_dir is not None:
state_dict = torch.load(load_dir)
new_state_dict = OrderedDict()
for name in state_dict:
if "decadapt" in name:
new_state_dict[name.replace("decadapt", "default")] = state_dict[name]
else:
new_state_dict[name] = state_dict[name]
self.llm_model.model.icae.model.model.g_layers.load_state_dict(new_state_dict, strict=False)
self.load_state_dict(new_state_dict, strict=False)
def logit_to_text(self, logits, masks):
tokenizer = self.llm_model.get_tokenizer()
if len(logits.size()) == 2:
logits = logits.unsqueeze(0)
decoded_texts = []
for i in range(logits.size(0)):
sample_logit = logits[i]
sample_mask = masks[i]
sample_logit = sample_logit[sample_mask]
token_ids = sample_logit[:, :32000].argmax(dim=-1).unsqueeze(0)
token_ids[token_ids >= 32000] = 1
sample_text = tokenizer.batch_decode(token_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
decoded_texts.extend(sample_text)
return decoded_texts
class PyGRGCNEdge(MultiLayerMessagePassing):
def __init__(self, num_layers: int, num_rels: int, inp_dim: int, out_dim: int, drop_ratio=0, JK="last",
batch_norm=True, ):
super().__init__(num_layers, inp_dim, out_dim, drop_ratio, JK, batch_norm)
self.num_rels = num_rels
self.build_layers()
def build_input_layer(self):
return RGCNEdgeConv(self.inp_dim, self.out_dim, self.num_rels)
def build_hidden_layer(self):
return RGCNEdgeConv(self.inp_dim, self.out_dim, self.num_rels)
def build_message_from_input(self, g):
return {"g": g.edge_index, "h": g.x, "e": g.edge_type, "he": g.edge_attr, }
def build_message_from_output(self, g, h):
return {"g": g.edge_index, "h": h, "e": g.edge_type, "he": g.edge_attr}
def layer_forward(self, layer, message):
return self.conv[layer](message["h"], message["he"], message["g"], message["e"])
class PyGRGATCN(MultiLayerMessagePassing):
def __init__(self, num_layers: int, t_layer: int, inp_dim: int, out_dim: int, drop_ratio=0.0, JK="last",
batch_norm=True, ):
super().__init__(num_layers, inp_dim, out_dim, 0, JK, batch_norm)
self.t_layer = t_layer
self.layer_dropout = drop_ratio
self.build_layers()
def build_input_layer(self):
# return GATConv(self.inp_dim*self.t_layer, self.inp_dim*self.t_layer)
# return TransformerConv(self.inp_dim*self.t_layer, self.inp_dim*self.t_layer)
return MConv(self.inp_dim, self.t_layer, 8, add_self_loops=True, dropout=self.layer_dropout,
layer_idx=len(self.conv))
def build_hidden_layer(self):
# return GATConv(self.inp_dim * self.t_layer, self.inp_dim * self.t_layer)
# return TransformerConv(self.inp_dim*self.t_layer, self.inp_dim*self.t_layer)
return MConv(self.inp_dim, self.t_layer, 8, add_self_loops=True, dropout=self.layer_dropout,
layer_idx=len(self.conv))
def build_message_from_input(self, g):
return {"g": g.edge_index, "h": g.x, "e": g.edge_type, "he": g.edge_attr, }
def build_message_from_output(self, g, h):
return {"g": g.edge_index, "h": h, "e": g.edge_type, "he": g.edge_attr}
def layer_forward(self, layer, message):
return self.conv[layer](message["h"], message["g"], message["he"])
helper.py
# example code for running inference with fine-tuned checkpoint
import numpy as np
import torch
from modules.gofa_icae_llama_modeling import LlamaICAE
from modules.gofa_icae_mistral_modeling import MistralICAE
from modules.llama_modeling import LlamaLora
from collections import OrderedDict
from safetensors.torch import load_file
class GOFALlamaHelper(torch.nn.Module):
def __init__(self, transformer_args):
super().__init__()
model_args, training_args, gofa_args = transformer_args
model = LlamaICAE(model_args, training_args, gofa_args) # restored llama2-7b-chat model
state_dict = torch.load(
"./cache_data/model/llama-2-7b-chat-finetuned-icae_zeroweight_llama2.pt") # change the path for your model
new_state_dict = OrderedDict()
for layer_name, weight in state_dict.items():
if isinstance(weight, torch.Tensor) or weight != 0.0:
new_state_dict[layer_name.replace("default", "encadapt")] = weight
model.load_state_dict(new_state_dict, strict=False)
# model.merge_lora()
self.dec_lora = model_args.dec_lora
self.mem_tokens = list(range(model.vocab_size, model.vocab_size + model_args.mem_size))
self.mem_size = model_args.mem_size
self.model = model
self.model.tokenizer.pad_token = self.model.tokenizer.eos_token
self.model.left_tokenizer.pad_token = self.model.left_tokenizer.bos_token
for param in self.model.icae.parameters():
param.requires_grad = False
for param in self.model.icae.get_base_model().model.g_layers.parameters():
param.requires_grad = True
if self.dec_lora:
for name, param in self.model.icae.named_parameters():
if "default" in name:
param.requires_grad = True
def get_tokenizer(self):
return self.model.tokenizer
def train_mode(self):
# for param in self.model.dec.parameters():
# param.requires_grad = False
self.model.icae.set_adapter("encadapt")
for param in self.model.icae.parameters():
param.requires_grad = False
def forward(self, data, answer, edge_data, prompt=None, graph=None, partial_grad=None):
cur_device = self.model.memory_token_embed.weight.device
batch_size = len(data)
if prompt is None:
prompt = [""] * len(data)
text_input = self.model.tokenizer(data, truncation=True, max_length=self.model.training_args.model_max_length,
padding=False, return_attention_mask=False)["input_ids"]
text_target = \
self.model.tokenizer(answer, truncation=True, max_length=self.model.training_args.model_max_length,
padding=False, return_attention_mask=False)["input_ids"]
edge_input = \
self.model.tokenizer(edge_data, truncation=True, max_length=self.model.training_args.model_max_length,
padding=False, return_attention_mask=False)["input_ids"] if len(edge_data) > 0 else []
text_target = [p + [self.model.tokenizer.eos_token_id] for p in text_target]
target_ids = torch.cat([torch.tensor(p, dtype=torch.long) for p in text_target], dim=-1).to(cur_device)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
prompt_input = [[self.model.ft_token_id] + a + [self.model.ft_token_id] if len(a) > 0 else a for a in
prompt_input]
text_ids = [a + self.mem_tokens + b + c for a, b, c in zip(text_input, prompt_input, text_target)]
target_mask = [[False] * (len(a) + self.mem_size + len(b) - 1) + [True] * (len(c)) + [False] for a, b, c in
zip(text_input, prompt_input, text_target)]
edge_text_ids = [a + self.mem_tokens for a in edge_input]
graph.num_node_feat = len(text_ids)
input_ids = text_ids + edge_text_ids
target_mask = target_mask + [[False] * len(a) for a in edge_text_ids]
text_output = {"input_ids": input_ids, "attention_mask": target_mask}
text_output = self.model.tokenizer.pad(text_output, padding=True, return_tensors="pt")
input_ids = text_output["input_ids"].to(device=cur_device)
target_mask = text_output["attention_mask"].to(torch.bool)
mem_mask = torch.logical_and(input_ids >= self.model.vocab_size,
input_ids < self.model.vocab_size + self.mem_size)
mem_mask = mem_mask.to(cur_device)
autoencoder_input_embedding = self.model.icae.get_base_model().model.embed_tokens(input_ids)
autoencoder_input_embedding[mem_mask] = self.model.memory_token_embed(
input_ids[mem_mask] - self.model.vocab_size).to(autoencoder_input_embedding)
self.model.icae.enable_adapter_layers()
compress_outputs = self.model.icae(inputs_embeds=autoencoder_input_embedding, output_hidden_states=True,
graph=graph, mem_mask=mem_mask, partial_grad=partial_grad, map_node=False)
self.model.icae.disable_adapter_layers()
compress_outputs = compress_outputs.logits
return compress_outputs, target_ids, target_mask
def encode(self, data, graph=None, partial_grad=None):
batch_size = len(data)
text_output = \
self.model.tokenizer(data, truncation=True, max_length=self.model.training_args.model_max_length, padding=False,
return_attention_mask=False)["input_ids"]
text_output = [t + self.mem_tokens for t in text_output]
text_output = {"input_ids": text_output}
text_output = self.model.tokenizer.pad(text_output, padding=True, return_tensors="pt")["input_ids"].to(
self.model.memory_token_embed.weight.device)
mem_mask = text_output >= self.model.vocab_size
mem_mask = mem_mask.to(self.model.memory_token_embed.weight.device)
autoencoder_input_embedding = self.model.icae.get_base_model().model.embed_tokens(text_output)
autoencoder_input_embedding[mem_mask] = self.model.memory_token_embed(
text_output[mem_mask] - self.model.vocab_size).to(autoencoder_input_embedding)
self.model.icae.set_adapter("encadapt")
self.model.icae.enable_adapter_layers()
for name, param in self.model.icae.named_parameters():
if "encadapt" in name:
param.requires_grad = False
compress_outputs = self.model.icae(inputs_embeds=autoencoder_input_embedding, output_hidden_states=True,
graph=graph, mem_mask=mem_mask, partial_grad=partial_grad, map_node=True)
self.model.icae.disable_adapter_layers()
compress_outputs = compress_outputs.hidden_states[-1]
if graph is not None:
node_emb = compress_outputs[:len(graph.node_map)]
map_mem_mask = mem_mask[:graph.num_node_feat][graph.node_map]
memory_embedding = node_emb[map_mem_mask].view(len(node_emb), self.mem_size, -1)
else:
memory_embedding = compress_outputs[mem_mask].view(batch_size, self.mem_size, -1)
return memory_embedding
def llm_output(self, data, input, prompt=None):
self.model.icae.disable_adapter_layers()
cur_device = self.model.memory_token_embed.weight.device
prompt_output = self.model.tokenizer(data, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
input_tokens = self.model.tokenizer(input, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
prompt_output = [p + [self.model.tokenizer.eos_token_id] for p in prompt_output]
if prompt is None:
prompt = [""] * len(data)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
prompt_input = [[self.model.ft_token_id] + a + [self.model.ft_token_id] if len(a) > 0 else a for a in
prompt_input]
prompt_ids = [a + b + c for a, b, c in zip(input_tokens, prompt_input, prompt_output)]
prompt_mask = [[False] * (len(a) + len(b) - 1) + [True] * (len(c)) + [False] for a, b, c in
zip(input_tokens, prompt_input, prompt_output)]
answer_prompt = torch.cat([torch.tensor(p, dtype=torch.long) for p in prompt_output], dim=-1).to(cur_device)
prompt_output = {"input_ids": prompt_ids, "attention_mask": prompt_mask}
prompt_output = self.model.tokenizer.pad(prompt_output, padding=True, return_tensors="pt")
prompt_answer_ids = prompt_output["input_ids"].to(cur_device)
target_mask = prompt_output["attention_mask"].to(cur_device).to(torch.bool)
prompt_answer_embs = self.model.icae.get_base_model().model.embed_tokens(prompt_answer_ids)
output_emb = self.model.dec(inputs_embeds=prompt_answer_embs).logits
return output_emb, answer_prompt, target_mask
def decode(self, data, mem_embs, graph=None, prompt=None):
prompt_output = self.model.tokenizer(data, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
prompt_output = [p + [self.model.tokenizer.eos_token_id] for p in prompt_output]
if prompt is None:
prompt = [""] * len(data)
prompt_input = self.model.left_tokenizer(prompt, add_special_tokens=False, padding=False, truncation=True, max_length=512)["input_ids"]
# print(self.model.left_tokenizer.batch_decode(prompt_input))
prompt_input = [[self.model.ft_token_id] + a + [self.model.ft_token_id] if len(a) > 0 else a for a in
prompt_input]
prompt_ids = [a + b for a, b in zip(prompt_input, prompt_output)]
prompt_mask = [[False] * len(a) + [True] * (len(b)) + [False] for a, b in zip(prompt_input, prompt_output)]
mem_mask = torch.tensor([[False] * (self.mem_size - 1) for _ in prompt_output], dtype=torch.long).to(mem_embs.device)
answer_prompt = torch.cat([torch.tensor(p, dtype=torch.long) for p in prompt_output], dim=-1).to(
mem_embs.device)
prompt_output = {"input_ids": prompt_ids, "attention_mask": prompt_mask}
prompt_output = self.model.tokenizer.pad(prompt_output, padding=True, return_tensors="pt")
prompt_answer_ids = prompt_output["input_ids"].to(mem_embs.device)
special_prompt = prompt_answer_ids >= self.model.vocab_size
target_mask = torch.cat([mem_mask, prompt_output["attention_mask"].to(mem_mask)], dim=-1).to(torch.bool)
prompt_answer_embs = self.model.icae.get_base_model().model.embed_tokens(prompt_answer_ids)
prompt_answer_embs[special_prompt] = self.model.memory_token_embed(
prompt_answer_ids[special_prompt] - self.model.vocab_size).to(prompt_answer_embs)
decode_embed = torch.cat([mem_embs.to(prompt_answer_embs), prompt_answer_embs], dim=1)
if self.dec_lora:
self.model.icae.set_adapter("default")
self.model.icae.enable_adapter_layers()
else:
self.model.icae.disable_adapter_layers()
output_emb = self.model.icae(inputs_embeds=decode_embed).logits
return output_emb, answer_prompt, target_mask
def generate(self, mem_embs, graph=None, prompt=None):
if prompt is None:
prompt = [""] * len(mem_embs)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
prompt_ids = [[self.model.ft_token_id] + a + [self.model.ft_token_id] if len(a) > 0 else a for a in
prompt_input]
mem_mask = [[True] * self.mem_size + [False] * len(a) for a in prompt_ids]
att_mask = [[True] * (self.mem_size + len(a)) for a in prompt_ids]
prompt_ids = [[self.model.tokenizer.pad_token_id] * self.mem_size + a for a in prompt_ids]
input_prompt_ids = self.model.left_tokenizer.pad({"input_ids": prompt_ids, "attention_mask": mem_mask},
padding=True, return_tensors="pt")
mem_mask = input_prompt_ids["attention_mask"].to(device=mem_embs.device, dtype=torch.bool)
input_prompt_ids = self.model.left_tokenizer.pad({"input_ids": prompt_ids, "attention_mask": att_mask},
padding=True, return_tensors="pt")
prompt_ids = input_prompt_ids["input_ids"]
att_mask = input_prompt_ids["attention_mask"].to(device=mem_embs.device)
prompt_answer_ids = prompt_ids.to(device=mem_embs.device, dtype=torch.long)
special_prompt = prompt_answer_ids >= self.model.vocab_size
prompt_answer_embs = self.model.icae.get_base_model().model.embed_tokens(prompt_answer_ids)
prompt_answer_embs[special_prompt] = self.model.memory_token_embed(
prompt_answer_ids[special_prompt] - self.model.vocab_size).to(prompt_answer_embs)
prompt_answer_embs[mem_mask] = mem_embs.view(-1, mem_embs.size()[-1])
# decode_embed = torch.cat([mem_embs.to(prompt_answer_embs), prompt_answer_embs], dim=1)
decode_embed = prompt_answer_embs
output = decode_embed.clone()
generate_text = []
eos_reached = torch.zeros(len(output), dtype=torch.bool).to(output.device)
past_key_values = None
if self.dec_lora:
self.model.icae.set_adapter("default")
self.model.icae.enable_adapter_layers()
else:
self.model.icae.disable_adapter_layers()
for i in range(128):
out = self.model.icae(inputs_embeds=output, attention_mask=att_mask, past_key_values=past_key_values,
use_cache=True)
logits = out.logits[:, -1]
past_key_values = out.past_key_values
next_token_id = torch.argmax(logits, dim=-1, keepdim=True)
eos_reached = torch.logical_or(eos_reached, (next_token_id == self.model.tokenizer.eos_token_id).view(-1))
eos_reached = torch.logical_or(eos_reached, (next_token_id == self.model.tokenizer.bos_token_id).view(-1))
eos_reached = torch.logical_or(eos_reached, (next_token_id >= 32000).view(-1))
generate_text.append(next_token_id.view(-1, 1))
if torch.all(eos_reached):
break
output = self.model.icae.get_base_model().model.embed_tokens(next_token_id).to(mem_embs.device)
att_mask = torch.cat(
[att_mask, torch.ones((len(att_mask), 1), dtype=att_mask.dtype, device=att_mask.device)], dim=-1)
generate_text = torch.cat(generate_text, dim=-1)
generate_text[generate_text >= 32000] = 1
generated_text = self.model.tokenizer.batch_decode(generate_text)
return generated_text
class GOFAMistralHelper(torch.nn.Module):
def __init__(self, transformer_args):
super().__init__()
model_args, training_args, gofa_args = transformer_args
model = MistralICAE(model_args, training_args, gofa_args) # restored llama2-7b-chat model
state_dict = load_file("./cache_data/model/mistral_7b_ft_icae.safetensors") # change the path for your model
new_state_dict = OrderedDict()
for layer_name, weight in state_dict.items():
new_state_dict[layer_name.replace("default", "encadapt")] = weight
model.load_state_dict(new_state_dict, strict=False)
# model.merge_lora()
self.dec_lora = model_args.dec_lora
self.mem_tokens = list(range(model.vocab_size, model.vocab_size + model_args.mem_size))
self.mem_size = model_args.mem_size
self.model = model
self.model.tokenizer.pad_token = self.model.tokenizer.eos_token
self.model.left_tokenizer.pad_token = self.model.left_tokenizer.bos_token
for param in self.model.icae.parameters():
param.requires_grad = False
for param in self.model.icae.get_base_model().model.g_layers.parameters():
param.requires_grad = True
if self.dec_lora:
for name, param in self.model.icae.named_parameters():
if "default" in name:
param.requires_grad = True
def get_tokenizer(self):
return self.model.tokenizer
def train_mode(self):
self.model.icae.set_adapter("encadapt")
for param in self.model.icae.parameters():
param.requires_grad = False
def forward(self, data, answer, edge_data, prompt=None, graph=None, partial_grad=None):
cur_device = self.model.memory_token_embed.weight.device
batch_size = len(data)
if prompt is None:
prompt = [""] * len(data)
text_input = \
self.model.tokenizer(data, truncation=True, max_length=5120, padding=False, return_attention_mask=False)[
"input_ids"]
text_target = \
self.model.tokenizer(answer, truncation=True, max_length=self.model.training_args.model_max_length,
padding=False, return_attention_mask=False)["input_ids"]
edge_input = \
self.model.tokenizer(edge_data, truncation=True, max_length=self.model.training_args.model_max_length,
padding=False, return_attention_mask=False)["input_ids"] if len(edge_data) > 0 else []
text_target = [p + [self.model.tokenizer.eos_token_id] for p in text_target]
target_ids = torch.cat([torch.tensor(p, dtype=torch.long) for p in text_target], dim=-1).to(cur_device)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
prompt_left_ids = [[1, 733, 16289, 28793]]
prompt_right_ids = [[self.model.ft_token_id] + a + [733, 28748, 16289, 28793] if len(a) > 0 else a for a in
prompt_input]
prompt_right_ids = torch.LongTensor([prompt_right_ids]).to(cur_device)
text_ids = [a + b + self.mem_tokens + c + d for a, b, c, d in
zip(text_input, prompt_left_ids, prompt_input, text_target)]
print(text_ids)
target_mask = [[False] * (len(a) + self.mem_size + len(b) + len(c) - 1) + [True] * (len(d)) + [False] for
a, b, c, d in zip(text_input, prompt_left_ids, prompt_input, text_target)]
edge_text_ids = [a + self.mem_tokens for a in edge_input]
graph.num_node_feat = len(text_ids)
print(graph.num_node_feat)
input_ids = text_ids + edge_text_ids
target_mask = target_mask + [[False] * len(a) for a in edge_text_ids]
text_output = {"input_ids": input_ids, "attention_mask": target_mask}
text_output = self.model.tokenizer.pad(text_output, padding=True, return_tensors="pt")
input_ids = text_output["input_ids"].to(device=cur_device)
target_mask = text_output["attention_mask"].to(torch.bool)
mem_mask = torch.logical_and(input_ids >= self.model.vocab_size,
input_ids < self.model.vocab_size + self.mem_size)
mem_mask = mem_mask.to(cur_device)
autoencoder_input_embedding = self.model.icae.get_base_model().model.embed_tokens(input_ids)
autoencoder_input_embedding[mem_mask] = self.model.memory_token_embed(
input_ids[mem_mask] - self.model.vocab_size).to(autoencoder_input_embedding)
self.model.icae.enable_adapter_layers()
print(autoencoder_input_embedding.shape)
print('---' * 30)
compress_outputs = self.model.icae(inputs_embeds=autoencoder_input_embedding, output_hidden_states=True,
graph=graph, mem_mask=mem_mask, partial_grad=partial_grad, map_node=False)
self.model.icae.disable_adapter_layers()
compress_outputs = compress_outputs.logits
return compress_outputs[target_mask], target_ids
def encode(self, data, graph=None, partial_grad=None):
cur_device = self.model.memory_token_embed.weight.device
batch_size = len(data)
text_output = \
self.model.tokenizer(data, truncation=True, max_length=self.model.training_args.model_max_length, padding=False,
return_attention_mask=False)["input_ids"]
text_output = [t + self.mem_tokens for t in text_output]
text_output = {"input_ids": text_output}
text_output = self.model.tokenizer.pad(text_output, padding=True, return_tensors="pt")["input_ids"].to(
cur_device)
mem_mask = text_output >= self.model.vocab_size
mem_mask = mem_mask.to(cur_device)
autoencoder_input_embedding = self.model.tokens_to_embeddings(text_output)
self.model.icae.set_adapter("encadapt")
self.model.icae.enable_adapter_layers()
for name, param in self.model.icae.named_parameters():
if "encadapt" in name:
param.requires_grad = False
compress_outputs = self.model.icae(inputs_embeds=autoencoder_input_embedding, output_hidden_states=True,
graph=graph, mem_mask=mem_mask, partial_grad=partial_grad, map_node=True)
self.model.icae.disable_adapter_layers()
compress_outputs = compress_outputs.hidden_states[-1]
if graph is not None:
node_emb = compress_outputs[:len(graph.node_map)]
map_mem_mask = mem_mask[:graph.num_node_feat][graph.node_map]
memory_embedding = node_emb[map_mem_mask].view(len(node_emb), self.mem_size, -1)
else:
memory_embedding = compress_outputs[mem_mask].view(batch_size, self.mem_size, -1)
return memory_embedding
def decode(self, data, mem_embs, graph=None, prompt=None):
prompt_output = self.model.tokenizer(data, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
prompt_output = [p + [self.model.tokenizer.eos_token_id] for p in prompt_output]
original_prompt_output = prompt_output
if prompt is None:
prompt = [""] * len(data)
prompt_input = self.model.left_tokenizer(prompt, add_special_tokens=False, padding=False, truncation=True, max_length=512)["input_ids"]
batch_size = len(prompt_input)
# For Mistral, decode contains: prefix, memory slots and suffix
prompt_left_ids = [[1, 733, 16289, 28793] if len(a) > 0 else [] for a in prompt_input]
prompt_right_ids = [[self.model.ft_token_id] + a + [733, 28748, 16289, 28793] if len(a) > 0 else a for a in
prompt_input]
prompt_ids = [a + [self.model.tokenizer.pad_token_id] * self.mem_size + b + c for a, b, c in
zip(prompt_left_ids, prompt_right_ids, prompt_output)]
prompt_mask = [
[False] * (len(prompt_left_ids[i]) + self.mem_size - 1 + len(prompt_right_ids[i])) + [True] * len(
prompt_output[i]) + [False] for i in range(batch_size)]
answer_prompt = torch.cat([torch.tensor(p, dtype=torch.long) for p in prompt_output], dim=-1).to(
mem_embs.device)
prompt_output = {"input_ids": prompt_ids, "attention_mask": prompt_mask}
prompt_output = self.model.tokenizer.pad(prompt_output, padding=True, return_tensors="pt")
prompt_answer_ids = prompt_output["input_ids"].to(mem_embs.device)
prompt_answer_embs = self.model.tokens_to_embeddings(prompt_answer_ids)
mem_mask = [[False] * len(prompt_left_ids[i]) + [True] * self.mem_size + [False] * (
len(prompt_output["input_ids"][i]) - len(prompt_left_ids[i]) - self.mem_size) for i in
range(batch_size)]
prompt_mask = [
[False] * (len(prompt_left_ids[i]) + self.mem_size - 1 + len(prompt_right_ids[i])) + [True] * len(
original_prompt_output[i]) + [False] * (1 + len(prompt_output["input_ids"][i]) - len(prompt_ids[i])) for
i in range(batch_size)]
prompt_answer_embs[torch.tensor(mem_mask)] = mem_embs.view(-1, mem_embs.size()[-1])
target_mask = torch.tensor(prompt_mask, dtype=torch.long, device=mem_embs.device).to(torch.bool)
if self.dec_lora:
self.model.icae.set_adapter("default")
self.model.icae.enable_adapter_layers()
else:
self.model.icae.disable_adapter_layers()
output_emb = self.model.icae(inputs_embeds=prompt_answer_embs).logits
return output_emb, answer_prompt, target_mask
def generate(self, mem_embs, graph=None, prompt=None):
cur_device = self.model.memory_token_embed.weight.device
if prompt is None:
prompt = [""] * len(mem_embs)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
batch_size = len(prompt_input)
prompt_left_ids = [[1, 733, 16289, 28793] if len(a) > 0 else [] for a in prompt_input]
prompt_right_ids = [[self.model.ft_token_id] + a + [733, 28748, 16289, 28793] if len(a) > 0 else a for a in
prompt_input]
mem_mask = [[False] * len(prompt_left_ids[i]) + [True] * self.mem_size + [False] * len(prompt_right_ids[i]) for
i in range(batch_size)]
att_mask = [[True] * (len(prompt_left_ids[i]) + self.mem_size + len(prompt_right_ids[i])) for i in
range(batch_size)]
prompt_ids = [prompt_left_ids[i] + [self.model.tokenizer.pad_token_id] * self.mem_size + prompt_right_ids[i] for
i in range(batch_size)]
input_prompt_ids = self.model.left_tokenizer.pad({"input_ids": prompt_ids, "attention_mask": mem_mask},
padding=True, return_tensors="pt")
mem_mask = input_prompt_ids["attention_mask"].to(device=mem_embs.device, dtype=torch.bool)
input_prompt_ids = self.model.left_tokenizer.pad({"input_ids": prompt_ids, "attention_mask": att_mask},
padding=True, return_tensors="pt")
prompt_ids = input_prompt_ids["input_ids"]
att_mask = input_prompt_ids["attention_mask"].to(device=mem_embs.device)
prompt_answer_ids = prompt_ids.to(device=mem_embs.device, dtype=torch.long)
prompt_answer_embs = self.model.tokens_to_embeddings(prompt_answer_ids)
prompt_answer_embs[mem_mask] = mem_embs.view(-1, mem_embs.size()[-1])
decode_embed = prompt_answer_embs
output = decode_embed.clone()
generate_text = []
eos_reached = torch.zeros(len(output), dtype=torch.bool).to(output.device)
past_key_values = None
if self.dec_lora:
self.model.icae.set_adapter("default")
self.model.icae.enable_adapter_layers()
else:
self.model.icae.disable_adapter_layers()
for i in range(128):
out = self.model.icae(inputs_embeds=output, attention_mask=att_mask, past_key_values=past_key_values,
use_cache=True)
logits = out.logits[:, -1, :self.model.vocab_size - 1]
past_key_values = out.past_key_values
next_token_id = torch.argmax(logits, dim=-1, keepdim=True)
eos_reached = torch.logical_or(eos_reached, (next_token_id == self.model.tokenizer.eos_token_id).view(-1))
# eos_reached = torch.logical_or(eos_reached, (next_token_id==self.model.tokenizer.bos_token_id).view(-1))
# eos_reached = torch.logical_or(eos_reached, (next_token_id>=32000).view(-1))
output = self.model.icae.get_base_model().model.embed_tokens(next_token_id).to(mem_embs.device)
generate_text.append(next_token_id.view(-1, 1))
att_mask = torch.cat(
[att_mask, torch.ones((len(att_mask), 1), dtype=att_mask.dtype, device=att_mask.device)], dim=-1)
if torch.all(eos_reached):
break
generate_text = torch.cat(generate_text, dim=-1)
generate_text[generate_text >= 32000] = 1
generated_text = self.model.tokenizer.batch_decode(generate_text)
return generated_text
class LlamaHelper(torch.nn.Module):
def __init__(self, transformer_args):
super().__init__()
model_args, training_args, gofa_args = transformer_args
model = LlamaLora(model_args, training_args, gofa_args) # restored llama2-7b-chat model
self.model = model
self.model.tokenizer.pad_token = self.model.tokenizer.eos_token
self.model.left_tokenizer.pad_token = self.model.left_tokenizer.bos_token
def get_tokenizer(self):
return self.model.tokenizer
def train_mode(self):
# for param in self.model.dec.parameters():
# param.requires_grad = False
pass
def forward(self, data, input, prompt=None):
cur_device = self.model.icae.get_base_model().model.embed_tokens.weight.device
prompt_output = self.model.tokenizer(data, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
input_tokens = self.model.tokenizer(input, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
prompt_output = [p + [self.model.tokenizer.eos_token_id] for p in prompt_output]
if prompt is None:
prompt = [""] * len(data)
prompt_input = self.model.tokenizer(prompt, add_special_tokens=False, padding=False)["input_ids"]
prompt_ids = [a + b + c for a, b, c in zip(input_tokens, prompt_input, prompt_output)]
prompt_mask = [[False] * (len(a) + len(b) - 1) + [True] * (len(c)) + [False] for a, b, c in
zip(input_tokens, prompt_input, prompt_output)]
answer_prompt = torch.cat([torch.tensor(p, dtype=torch.long) for p in prompt_output], dim=-1).to(cur_device)
prompt_output = {"input_ids": prompt_ids, "attention_mask": prompt_mask}
prompt_output = self.model.tokenizer.pad(prompt_output, padding=True, return_tensors="pt")
prompt_answer_ids = prompt_output["input_ids"].to(cur_device)
target_mask = prompt_output["attention_mask"].to(cur_device).to(torch.bool)
prompt_answer_embs = self.model.icae.get_base_model().model.embed_tokens(prompt_answer_ids)
output_emb = self.model.icae(inputs_embeds=prompt_answer_embs).logits
# for name, p in self.model.named_parameters():
# if "default" in name:
# print(p.abs().sum())
# break
return output_emb, answer_prompt, target_mask
def encode(self, data, input, prompt=None):
raise NotImplementedError("no encdoe for llama")
def decode(self, data, input, prompt=None):
return self(data, input, prompt)
def generate(self, input, prompt=None):
cur_device = self.model.icae.get_base_model().model.embed_tokens.weight.device
if prompt is None:
prompt = [""] * len(input)
prompt_ids = self.model.tokenizer(input, add_special_tokens=False, padding=False, truncation=True,
max_length=self.model.training_args.model_max_length)["input_ids"]
att_mask = [[True] * (len(a)) for a in prompt_ids]
input_prompt_ids = self.model.tokenizer.pad({"input_ids": prompt_ids, "attention_mask": att_mask},
padding=True, return_tensors="pt")
prompt_ids = input_prompt_ids["input_ids"]
att_mask = input_prompt_ids["attention_mask"].to(device=cur_device)
prompt_answer_ids = prompt_ids.to(device=cur_device, dtype=torch.long)
with torch.no_grad():
outputs = self.model.icae.generate(prompt_answer_ids, max_length=1024, num_return_sequences=1, pad_token_id = self.model.eos_id)
generated_text = [self.model.tokenizer.decode(output, skip_special_tokens=True) for output in outputs]
generated_text = [self.extract_content_after_inst(t) for t in generated_text]
return generated_text
def extract_content_after_inst(self, generated_text):
# Find the index of the closing tag [/INST]
closing_tag = "[/INST]"
start_index = generated_text.find(closing_tag)
if start_index == -1:
# If the closing tag is not found, return the entire text
return generated_text
# Extract the content after the closing tag
content_after_inst = generated_text[start_index + len(closing_tag):].strip()
return content_after_inst



















 8461
8461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











