




论文名称:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
论文链接:https://arxiv.org/abs/2503.09516v2
机构:伊利诺伊大学厄巴纳-香槟分校 + 马萨诸塞大学阿默斯特分校
Github代码链接:https://github.com/PeterGriffinJin/Search-R1
简介
这篇论文提出 Search-R1,通过强化学习让 LLMs 在逐步推理过程中自主生成搜索查询并实时检索,在七个问答数据集上比强基线模型性能显著提升。整体思路与R1-Searcher非常相似,因此只介绍一些核心项。
一阶段RL
-
梯度方法:PPO&GRPO。
-
外部检索结果:不参与loss计算,与R1-Searcher设置一致。
-
多轮:考虑到了多步Rollouts的情况。
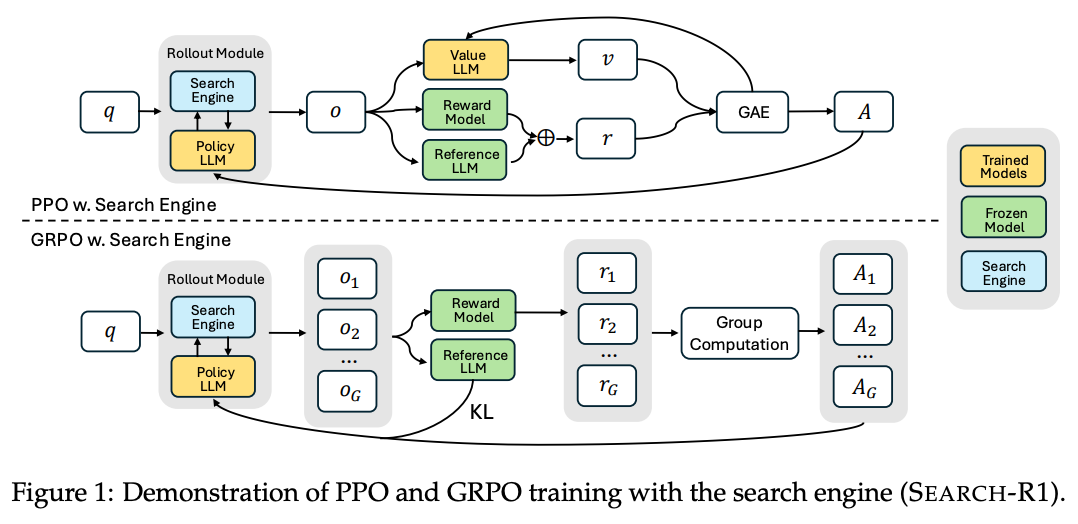

- Reward Design:采用的是精确匹配。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











