




 本文探讨YOLOv5模型在OpenVINO上的优化,包括知识蒸馏和量化方法。通过知识蒸馏提升模型精度,使用Objectness scaled Distillation解决背景预测问题。在OpenVINO上进行量化,利用POT工具实现性能提升,量化后模型在CPU上推理速度提高2倍。
本文探讨YOLOv5模型在OpenVINO上的优化,包括知识蒸馏和量化方法。通过知识蒸馏提升模型精度,使用Objectness scaled Distillation解决背景预测问题。在OpenVINO上进行量化,利用POT工具实现性能提升,量化后模型在CPU上推理速度提高2倍。
基于强大的目标检测能力和较快的推理速度,YOLOv5 已经逐渐成为实时性目标检测任务中的首选模型。因此,YOLOv5 模型的优化和部署是落地任务中非常重要的部分。在 CPU 中部署 AI模型存在着大量的需求,Intel CPU 因其强劲的性能,丰富的软件生态,是我们在 CPU 上部署的首选硬件。本文主要研究了 YOLOv5 模型的知识蒸馏以及在 Intel CPU 上使用 OpenVINO 进行部署优化实践。通过采用知识蒸馏和量化的方法,在不损失精度的条件下,实现了 YOLOv5 模型在 OpenVINO 上 2 倍的推理速度提升。相关代码已开源在Adlik代码库中:https://github.com/Adlik/yolov5
1、知识蒸馏
现有的目标检测蒸馏方法主要对两阶段目标检测(如 RCNN 系列)较为有效,而这些蒸馏方法对于单阶段的目标检测器如 YOLOv5 模型精度几乎没有提升。因此,我们主要采用论文 《Object detection at 200 Frames Per Second》中对单阶段目标检测器的蒸馏方法。该论文研究了单阶段目标检测器使用普通知识蒸馏的问题和面临的挑战。
1.1 Objectness scaled Distillation
单级目标检测方法使用普通知识蒸馏的问题。单阶段目标检测器的预测是一个密集的候选集合。老师网络(YOLO 模型)预测图像背景区域中的边界框。在推理过程中,背景区域预测的边界框会被忽略。然而,标准的蒸馏方法会将这些背景检测转移到了学生模型学习中。它会影响边界框的训练 ,因为学生网络会从老师网络预测的背景区域中学习错误的边界框。两阶段的目标检测方法(如 RCNN)通过使用 RPN 网络来规避这个问题,因为 RPN 网络预测相对较少的候选区域。为了避免学习老师网络对背景区域的预测,论文中定义蒸馏损失为 objectness scaled function。其思想学生网络只学习老师网络预测的目标概率值较高的边界框位置和类别概率。
YOLO 目标损失函数由三部分组成:regression loss(回归损失函数), objectness loss (目标损失函数)和 classification loss(分类损失函数)。
目标损失函数部分不需要目标缩放,因为对于背景区域的预测的目标概率值比较低,因此,知识蒸馏的目标损失函数定义如下:
学生网络的目标缩放分类函数:
其中,上述损失函数的第一部分对应原始的目标分类损失函数,而第二部分是目标分类蒸馏损失部分。学生网络的目标缩放边界框位置损失函数:
402 Payment Required
老师网络将非常低的目标概率值作为大多数与背景相对应的预测框的权重。基于目标函数的缩放算法是一种用于单阶段目标检测器中蒸馏过滤器的缩放算法,因为该算法分配给背景预测框的权值很低。损失函数形式保持不变,但对于知识蒸馏损失函数,只是用老师网络的输出代替标签值。训练阶段总的损失函数为:
1.2 Feature Map-NMS
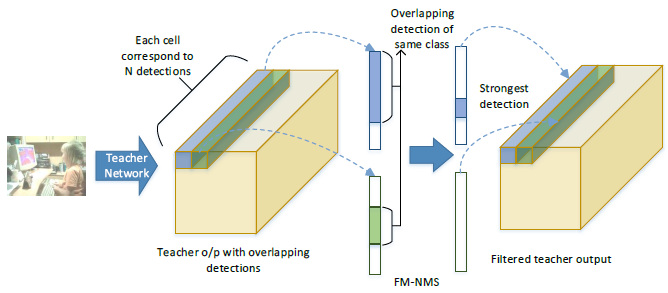
单级目标检测方法蒸馏时面临的挑战: 该网络经过训练,可以从一个单元的单个锚定框(anchor)预测一个框,但实际上,许多单元和锚定框最终会预测图像中的同一对象。因此,NMS 作为目标检测器中的后处理步骤是必不可少的。然而,NMS 步骤应用于端到端网络架构之外,高度重叠的预测仍然会在目标检测器的最后卷积层中表示。当这些预测从老师网络转移到学生网络时,会产生冗余信息。因此,上述蒸馏损失导致性能损失,因为老师网络最终传输高度重叠检测的信息损失
为了克服重叠检测带来的问题,论文提出了 Feature Map-NMS (FM-NMS)。该方法的思想是,如果 单元邻域中的多个候选框对应于同一类别,则它们很可能对应于图像中的相同目标。因此,我们只选择一个具有最高的目标概率值的候选框。我们检查最后一层特征图中对应于类别概率(是指 objectness 还是 class 的概率)的激活,将对应于同一类别的激活设置为零。
2、在 OpenVINO 上的量化
2.1 OpenVINO 量化工具介绍
从 OpenVINO 2020.1 发行版开始,所有量化模型使用所谓的 FakeQuantize 层来表示,这个层是一个具有表现力的原语,能够表示 Quantize、Dequantize、Requantize 等等运算。该运算在量化过程中被插入到模型中,旨在存储层的量化参数。为了执行这种“假量化”模型,OpenVINO 有一个低精度运行时,它是推理引擎的一部分,由一个将模型转换为实整数表示的通用组件和在相应硬件插件中实施的硬件特定部分组成。
OpenVINO 提
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











