




1.什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与生成式 AI的技术框架,核心目的是提升大语言模型(LLM)生成内容的准确性、可靠性和时效性。
2.为什么需要RAG?
传统大语言模型(如 GPT 系列)存在一些局限:
知识过时:训练数据截止到某个时间点,无法获取最新信息(如 2024 年后的新闻、企业内部更新的文档)。
易产生 “幻觉”:对不确定的内容可能生成错误信息(如编造不存在的事实、数据)。
难以处理专业领域知识:对企业内部文档、行业特定数据(如医疗手册、法律条文)的理解有限。
RAG 的出现正是为了弥补这些缺陷:通过 “先检索、再生成” 的逻辑,让模型基于外部可靠知识回答问题,而非仅依赖自身训练数据。
3.开始实战吧!
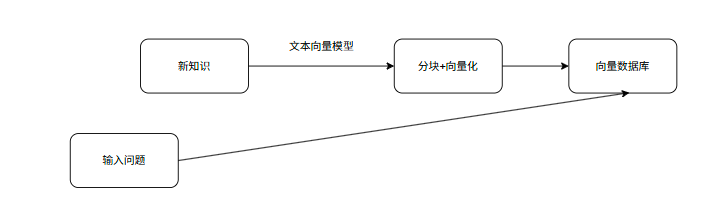
1.对于新知识(如txt文件),我们需要把它分段,然后变为向量喂给大模型。
先看我们txt文件长什么样子吧,如下(每个知识点中间空两个格):
【绿叶蔬菜(如菠菜、生菜)】
保存要点:叶片易萎蔫、发黄,切口易滋生细菌,吸水后腐烂快。
保存方法:先摘除黄叶,将根部浸入浅水杯(水位 1-2cm),套塑料袋扎口,放冰箱冷藏室(0-5℃),2-3 天换一次水。
【菌菇类(如香菇、平菇)】
保存要点:菌褶易藏水发霉,表皮薄易干裂,呼吸作用强加速变质。
保存方法:鲜菌菇不洗,用厨房纸吸干表面水,装入保鲜袋(留透气孔),放冰箱保鲜层(4-8℃),避免与有异味食材同放。
【葱姜蒜】
保存要点:姜易发芽腐烂,葱叶易枯焦,蒜遇湿易发霉,遇干易干瘪。
保存方法:姜切小块装密封盒 + 干燥剂,放冷冻室(-18℃);葱切段,厨房纸包裹后放保鲜袋,扎口放冷藏;蒜剥好装密封罐,放阴凉干燥处(15-20℃)。
【浆果类(如草莓、蓝莓)】
保存要点:表皮薄易磕碰腐烂,含糖量高易滋生霉菌,吸水后加速变质。
保存方法:不清洗,去除坏果,单层平铺保鲜盒(垫厨房纸吸潮),放冰箱冷藏(2-4℃),吃前再洗,避免堆叠挤压。
【肉类(鲜猪肉、牛肉)】
保存要点:肌红蛋白易氧化变色,细菌在 0-4℃仍缓慢繁殖,脂肪易酸败。
保存方法:分装成单次食用量,用保鲜膜紧密包裹,放冰箱冷冻室(-18℃以下),解冻时用冷水浸泡或微波炉解冻,避免反复冻融。
【海鲜(鲜鱼、虾)】
保存要点:鱼虾含酶类活跃,常温下 3 小时开始腐败,腥味重易串味。
保存方法:鲜鱼去内脏,鱼身抹盐 + 料酒,装保鲜袋抽气密封;鲜虾剪须,焯水至半熟(加姜片),过凉水沥干,装袋冻存,放冷冻室(-18℃)。然后是根据文本格式去分段:
# 读取文件内容
with open("knowledge/1.txt", encoding='utf-8',mode='r') as fp:
data = fp.read()
# 根据换行切割文件内容
chunk_list = data.split('\n\n')
chunk_list = [chunk for chunk in chunk_list if chunk]
print(len(chunk_list))
print(chunk_list[0])
2.使用文本向量模型进行分块向
文本向量模型使用nomic-embed-text
简单介绍下nomic-embed-text 是 Nomic AI 开发的 开源文本嵌入模型,专注为检索增强生成(RAG)、语义搜索等场景提供高效文本向量化能力。
可以通过ollama命令去下载
ollama pull nomic-embed-text 然后本地启动服务
ollama serve实验一下是否能把文字变为向量
import requests
text = "我要当太空人"
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text
}
)
embedding_list = res.json()['embedding']
print(text)
print(len(embedding_list), embedding_list)run~
![]()
文本可以变成向量了
3.集成
既然已经实现了文本切割和文本的向量化,我们开始将切割的文本分别向量化并集成起来。
import requests
import functools
def file_chunk_list():
"""读取知识文件,按空行分割为多个知识片段"""
with open("knowledge/1.txt", encoding='utf-8') as fp:
data = fp.read()
chunk_list = data.split("\n\n")
return [chunk.strip() for chunk in chunk_list if chunk.strip()]
def ollama_embedding_by_api(text):
"""调用 Ollama 的 embeddings API 生成文本嵌入"""
try:
res = requests.post(
url="http://127.0.0.1:11434/api/embeddings",
json={
"model": "nomic-embed-text",
"prompt": text # 使用包裹后的文本
}
)
res.raise_for_status()
embedding = res.json()["embedding"]
return embedding
except Exception as e:
print(f"嵌入失败:{e}")
return None
def run():
"""主流程:处理所有知识片段,生成嵌入"""
chunk_list = file_chunk_list()
print(f"共加载 {len(chunk_list)} 个知识片段")
for idx, chunk in enumerate(chunk_list, 1):
print(f"\n=== 处理第 {idx} 个片段 ===")
print(f"内容预览:{chunk[:80]}...")
embedding = ollama_embedding_by_api(chunk)
if embedding:
print(f"嵌入维度:{len(embedding)}")
# TODO:存储 embedding 和原始文本到向量数据库
print("\n所有知识片段处理完成!")
if __name__ == "__main__":
run()run~
共加载 6 个知识片段
=== 处理第 1 个片段 ===
内容预览:【绿叶蔬菜(如菠菜、生菜)】
保存要点:叶片易萎蔫、发黄,切口易滋生细菌,吸水后腐烂快。
保存方法:先摘除黄叶,将根部浸入浅水杯(水位 1-2cm),套塑料袋扎...
嵌入维度:768
=== 处理第 2 个片段 ===
内容预览:【菌菇类(如香菇、平菇)】
保存要点:菌褶易藏水发霉,表皮薄易干裂,呼吸作用强加速变质。
保存方法:鲜菌菇不洗,用厨房纸吸干表面水,装入保鲜袋(留透气孔),放冰...
嵌入维度:768
=== 处理第 3 个片段 ===
内容预览:【葱姜蒜】
保存要点:姜易发芽腐烂,葱叶易枯焦,蒜遇湿易发霉,遇干易干瘪。
保存方法:姜切小块装密封盒 + 干燥剂,放冷冻室(-18℃);葱切段,厨房纸包裹后放...
嵌入维度:768
=== 处理第 4 个片段 ===
内容预览:【浆果类(如草莓、蓝莓)】
保存要点:表皮薄易磕碰腐烂,含糖量高易滋生霉菌,吸水后加速变质。
保存方法:不清洗,去除坏果,单层平铺保鲜盒(垫厨房纸吸潮),放冰箱...
嵌入维度:768
=== 处理第 5 个片段 ===
内容预览:【肉类(鲜猪肉、牛肉)】
保存要点:肌红蛋白易氧化变色,细菌在 0-4℃仍缓慢繁殖,脂肪易酸败。
保存方法:分装成单次食用量,用保鲜膜紧密包裹,放冰箱冷冻室(-...
嵌入维度:768
=== 处理第 6 个片段 ===
内容预览:【海鲜(鲜鱼、虾)】
保存要点:鱼虾含酶类活跃,常温下 3 小时开始腐败,腥味重易串味。
保存方法:鲜鱼去内脏,鱼身抹盐 + 料酒,装保鲜袋抽气密封;鲜虾剪须,...
嵌入维度:768
所有知识片段处理完成!目前结构如下:

4.向量数据库
下一步我们需要将向量化的数据存储到向量数据库。

4.1使用chromadb搭建向量数据库
import uuid
import chromadb
import requests
from 集成分割与向量化 import file_chunk_list, ollama_embedding_by_api
# 1. 初始化 Chroma 数据库(持久化存储到本地目录)
client = chromadb.PersistentClient(path="db/chroma_demo") # 数据存到 ./db/chroma_demo 文件夹
collection = client.get_or_create_collection(name="collection_v1") # 类似“表格”,自动创建不存在的集合
documents = []
embeddings = []
chunk_list = file_chunk_list()
for chunk in chunk_list:
documents.append(chunk)
embedding = ollama_embedding_by_api(chunk)
embeddings.append(embedding)
ids = [str(uuid.uuid4()) for _ in documents]
# 2. 插入数据到 Chroma 集合
collection.add(
ids=ids, # 每个文档的唯一标识
documents=documents, # 原始文本内容
embeddings=embeddings # 文本对应的向量(需提前生成)
)
看着很多,其实也就是上边三个模块的整合
run~下就好了
到此向量数据库搭建好啦。
5.查询下看看
向量数据库搭建完成后,我们尝试给出一些词,看他是否能找到?
import chromadb
from 集成分割与向量化 import ollama_embedding_by_api
db_path = "db/chroma_demo"
collection_name = "collection_v1"
client = chromadb.PersistentClient(path=db_path)
collection = client.get_collection(name=collection_name)
qs = '蔬菜'
qs_embedding = ollama_embedding_by_api(qs)
res = collection.query(query_embeddings=[qs_embedding],n_results=2)
print(res['documents'][0][0])
print(res['documents'][0][1])
我们输入蔬菜,返回两个结果,就会打印出信息如下:

6.交给大模型处理
上述我们输入蔬菜,但是返回的两个结果中菌菇这个关键词会出现在蔬菜前边,如何去解决这个问题?那我们就尝试把提问的问题和返回的结果放入大模型进行筛选,选出最合适的结果并润色输出。(这里由于资源有限使用本地部署的deepseek-r1:1.5b)。
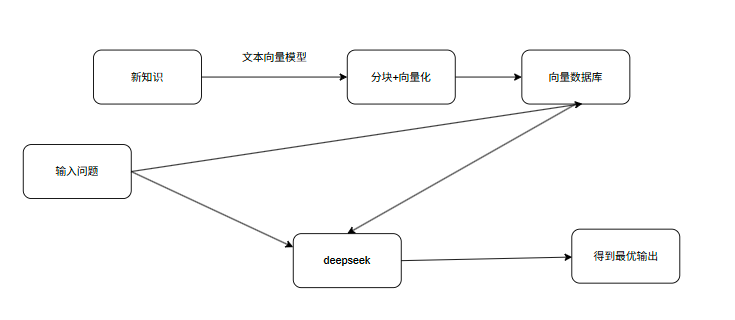
先看我们的提示词
prompt = f"你是一个健康饮食专家,任务是根据参考信息回答用户问题,如果参考信息不足以回答用户问题,请回复不知道,不要去杜撰任何信息,请用中文回答。参考信息:{context},来回答问题:{qs}"再看我们的代码
import chromadb
from 集成分割与向量化 import ollama_embedding_by_api
import requests
db_path = "db/chroma_demo"
collection_name = "collection_v1"
client = chromadb.PersistentClient(path=db_path)
collection = client.get_collection(name=collection_name)
qs = '草莓怎么保存'
qs_embedding = ollama_embedding_by_api(qs)
res = collection.query(query_embeddings=[qs_embedding],n_results=2)
print(res['documents'][0][0])
print(res['documents'][0][1])
context = res['documents']
prompt = f"你是一个健康饮食专家,任务是根据参考信息回答用户问题,如果参考信息不足以回答用户问题,请回复不知道,不要去杜撰任何信息,请用中文回答。参考信息:{context},来回答问题:{qs}"
response = requests.post(
url="http://127.0.0.1:11434/api/generate",
json={
"model": "deepseek-r1:1.5b",
"prompt": prompt,
"stream": False
}
)
res = response.json()['response']
print(res)分析:
问题:草莓怎么保存
首先从 向量库中找到两个返回结果
【浆果类(如草莓、蓝莓)】
保存要点:表皮薄易磕碰腐烂,含糖量高易滋生霉菌,吸水后加速变质。
保存方法:不清洗,去除坏果,单层平铺保鲜盒(垫厨房纸吸潮),放冰箱冷藏(2-4℃),吃前再洗,避免堆叠挤压。
【肉类(鲜猪肉、牛肉)】
保存要点:肌红蛋白易氧化变色,细菌在 0-4℃仍缓慢繁殖,脂肪易酸败。
保存方法:分装成单次食用量,用保鲜膜紧密包裹,放冰箱冷冻室(-18℃以下),解冻时用冷水浸泡或微波炉解冻,避免反复冻融。再把问题和结果通过提示词放入deepseek中,得到返回结果:
<think>
好吧,用户问的是草莓怎么保存。首先看参考信息里的第一个条目,里面有关于浆果类的保存方法。里面提到草莓是浆果类,表皮薄容易磕碰腐烂,糖分高容易霉菌滋生。保存的方法是不清洗,去除坏果,单层平铺保鲜盒,放在冰箱冷藏2-4度,吃前再洗,避免堆叠挤压。
那我需要整理一下这些信息来回答用户的问题。首先明确草莓的类型,浆果类。然后保存要点包括表皮薄易腐烂、糖分高变质的风险。接着保存方法,不清洗,去除坏果,单层平铺,放在冰箱冷藏,吃前洗,避免堆叠。
还要注意注意事项,不要堆叠或挤压,保持干燥。这样回答用户的问题就涵盖了保存的关键点和步骤。
</think>
草莓的保存方法如下:
1. **表皮薄、易腐烂**:直接放置于冷空气中,避免在温暖环境中长时间暴露。
2. **糖分高变质**:用无菌水轻轻擦拭表面,避免细菌侵入。
3. **保存方法**:
- 不清洗,仅去除坏果。
- 单层平铺保鲜盒或塑料袋,防止挤压或碰撞导致腐烂。
- 放在冰箱冷藏室(2-4℃),以减少水分蒸发和微生物生长。
4. **吃前处理**:立即洗去多余的油脂、分泌物等杂质,并确保新鲜度。
5. **注意事项**:避免堆叠或挤压,保持表面干燥。结果还不错。
ps:代码在这里。


















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









