




 本文探讨了在多个GPU上训练大型模型的方法,包括数据并行、模型并行、混合专家等策略,还介绍了混合精度计算、梯度累积等节省内存的设计。同时分析了英伟达禁令对中国AI计算行业的影响,并提出用好买家身份、以云代卡、推动国产AI算力成长等应对方案。
本文探讨了在多个GPU上训练大型模型的方法,包括数据并行、模型并行、混合专家等策略,还介绍了混合精度计算、梯度累积等节省内存的设计。同时分析了英伟达禁令对中国AI计算行业的影响,并提出用好买家身份、以云代卡、推动国产AI算力成长等应对方案。
★大模型、人工智能;数据并行;模型并行;流水线并行;混合精度训练、梯度累积;模型卸载CPU;重算;模型压缩;内存优化版优化器;Nvidia;A100;H100;A800;H800;L40s;混合专家;910B;HGX H20;L20 PCIe;L2 PCIe
在人工智能领域,大型模型因其强大的预测能力和泛化性能而备受瞩目。然而,随着模型规模的不断扩大,计算资源和训练时间成为制约其发展的重大挑战。特别是在英伟达禁令之后,中国AI计算行业面临前所未有的困境。为了解决这个问题,英伟达将针对中国市场推出新的AI芯片,以应对美国出口限制。本文将探讨如何在多个GPU上训练大型模型,并分析英伟达禁令对中国AI计算行业的影响。
如何在多个 GPU 上训练大型模型?
神经网络的训练是一个反复迭代的过程。在每次迭代中,数据首先向前传播,通过模型的各层,为每个训练样本计算输出。然后,梯度向后传播,计算每个参数对最终输出的影响程度。这些参数的平均梯度和优化状态被传递给优化算法,如Adam,用于计算下一次迭代的参数和新的优化状态。随着训练的进行,模型逐渐发展以产生更准确的输出。
然而,随着大模型的到来,单机难以完成训练。并行技术应运而生,基于数据并行性、管道并行性、张量并行性和混合专家等策略,将训练过程划分为不同的维度。此外,由于机器和内存资源的限制,还出现了混合精度训练、梯度累积、模型卸载CPU、重算、模型压缩和内存优化版优化器等策略。
为进一步加速训练过程,可以从数据和模型两个角度同时进行并行处理。一种常见的方式是将数据切分,并将相同的模型复制到多个设备上,处理不同数据分片,这种方法也被称为数据并行。另外一种方法是模型并行即将模型中的算子划分到多个设备上分别完成(包括流水线并行和张量并行)。当训练超大规模语言模型时,需要对数据和模型同时进行切分,以实现更高级别的并行,这种方法通常被称为混合并行。通过这些并行策略,可以显著提高神经网络的训练速度和效率。
一、数据并行
在数据并行系统中,每个计算设备都有完整的神经网络模型副本,在进行迭代时,每个设备仅负责处理一批数据子集并基于该子集进行前向计算。假设一批次的训练样本数为N,使用M个设备并行计算,每个设备将处理N/M个样本。完成前向计算后,每个设备将根据本地样本计算误差梯度Gi(i为加速卡编号)并进行广播。所有设备需要聚合其他加速卡提供的梯度值,然后使用平均梯度(ΣN i=1Gi)/N来更新模型,完成该批次训练。
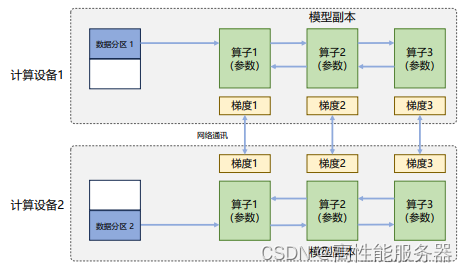
数据并行训练系统通过增加计算设备,可以显著提高整体训练吞吐量和每秒全局批次数。与单计算设备训练相比,最主要的区别在于反向计算中梯度需要在所有计算设备中进行同步,以确保每个计算设备上最终得到所有进程上梯度平均值。
二、模型并行
模型并行可以从计算图的角度出发,采用流水线并行和张量并行两种方式进行切分。
![]()
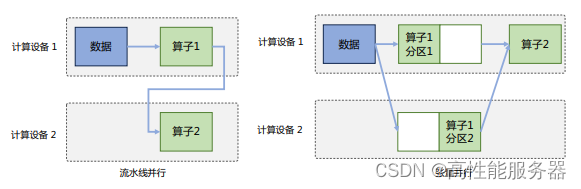
1、流水线并行
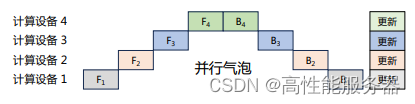
流水线并行(Pipeline Parallelism,PP)是一种计算策略,将模型的各层划分为多个阶段,并在不同计算设备上进行处理,实现前后阶段的连续工作。PP广泛应用于大规模模型的并行系统,以解决单个设备内存不足问题。下图展示了由四个计算设备组成的PP系统,包括前向计算和后向计算。其中F1、F2、F3、F4代表四个前向路径,位于不同设备上;B4、B3、B2、B1代表逆序后向路径,位于四个不同设备上。然而,下游设备需要等待上游设备计算完成才能开始计算任务,导致设备平均使用率降低,形成模型并行气泡或流水线气泡。
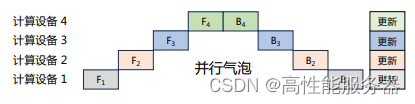
朴素流水线策略会导致并行气泡,使系统无法充分利用计算资源,降低整体计算效率。为减少并行气泡,可以将小批次进一步划分为更小的微批次,并利用流水线并行方案处理每个微批次数据。在完成当前阶段计算并得到结果后,将该微批次的结果发送给下游设备,同时开始处理下一微批次的数据,在一定程度上减少并行气泡。如下图所示,前向F1计算被拆解为F11、F12、F13、F14,在计算设备1中完成F11计算后,会在计算设备2中开始进行F21计算,同时计算设备1中并行开始F12的计算。与原始流水线并行方法相比,有效降低并行气泡。
![]()
2、张量并行
张量并行需要针对模型结构和算子类型处理参数如何在不同设备上进行切分,并确保切分后的数学一致性。大语言模型以Transformer结构为基础,包含三种算子:嵌入表示、矩阵乘和交叉熵损失计算。这三种算子具有较大差异,因此需要设计相应的张量并行策略,以便将参数分配到不同设备上。对于嵌入表示层参数,可按照词维度进行划分,每个计算设备只存储部分词向量,然后通过汇总各个设备上的部分词向量来获得完整的词向量。
![]()
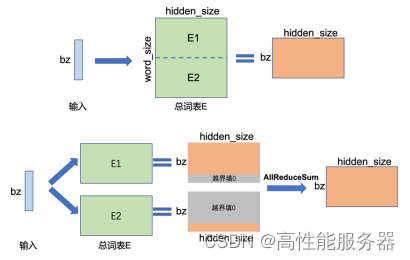
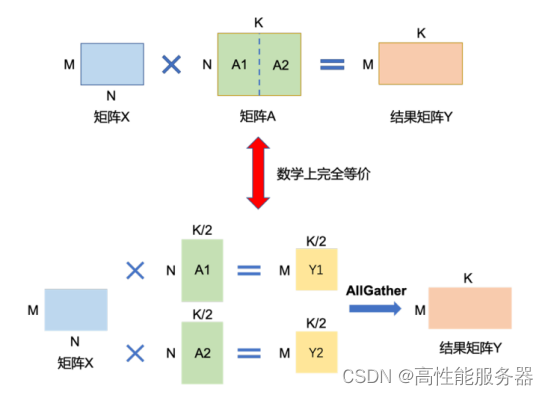
矩阵乘的张量并行可以利用矩阵分块乘法原理来优化计算。以矩阵乘法Y = X × A为例,其中X是M × N维的输入矩阵,A是N × K维的参数矩阵,Y是M × K维的结果矩阵。当参数矩阵A过大超出单张卡的显存容量时,可以将A切分到多张卡上,并通过集合通信汇集结果,确保最终结果的数学计算等价于单计算设备的计算结果。参数矩阵A有两种切分方式:
1)按列切分
将矩阵A按列切成A1和A2,分别放置在两个计算设备上。两个计算设备分别计算Y1 = X × A1和Y2 = X × A2。计算完成后,多计算设备间进行通信,拼接得到最终结果矩阵Y,其数学计算与单计算设备结果等价。
![]()
2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1776
1776










 到【灌水乐园】发言
到【灌水乐园】发言







