




参考李沐深度学习视频
例如一台机器有4张显卡。
在训练和预测时,可以将一个小批量切分到这4个显卡上来达到加速的目的。
切分方案有:数据并行、模型并行、通道并行(数据+模型并行)
数据并行
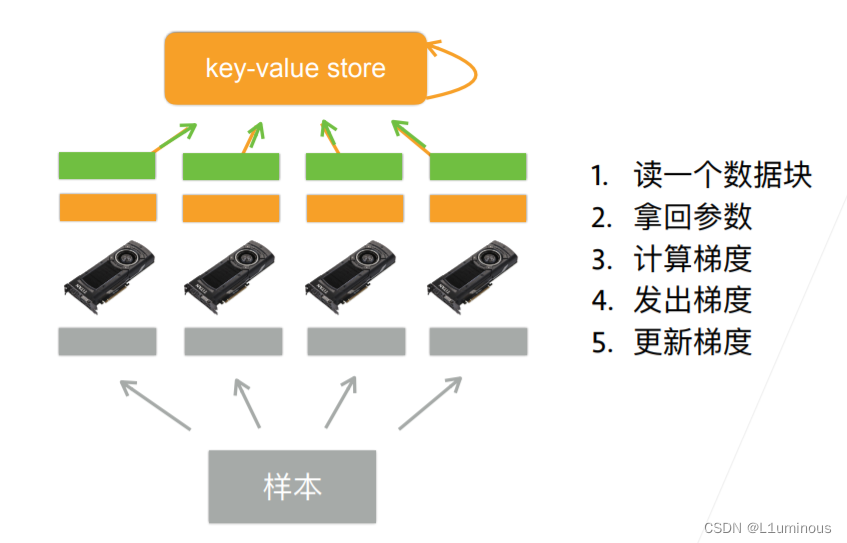
比如说在训练和预测时,批量大小设置的为128,那么这个批量被切分成4块,每块的大小为32
每个GPU拿到完整的模型参数后,这4块小批量分别给这4个GPU进行梯度的计算
将梯度计算完后,4个GPU计算的梯度进行加和,然后传给key-value store
然后在key-value store中更新模型的梯度。如图
李沐视频中提到,数据并行会很大的提高模型收敛和性能,为什么?就比如说,在一张单卡GPU上进行训练,我理解的,batch_size=1与batch_size=64是不一样的,当batch_size=1时,每次计算梯度时,因为样本数量很小,所以训练这个w时会更加贴合这个样本,模型收敛的会很快,当然这样也会导致训练很慢。当batch_size=64时,因为样本数量变大了,里面各种各样的数据变多了,也就是增加了数据的多样性,训练时这个w贴合的就是这些样本而不是batch_size=1时的单个样本,训练时,模型的收敛速度变慢,但同时我理解的是模型的泛化能力也增强了。
模型并行
模型并行就是将模型进行切分,这种情况通常适合模型太大,一个GPU放不下,然后切分一下,把一个模型切成块分别放到不同的GPU上(我就是一个学生,我肯定没有用到过这么大的模型)。
就如李沐提到的,一个100层的ResNet,切成4块,每块25层,然后分别放到4个GPU上。
我听完李沐的课理解的是,他的数据是串行的,但整个训练过程在一定程度上可以做到并行。比如,第一块的25层计算完之后,将结果传给第二块,只有第二块有了第一块的结果作为输入,第二块才能进行计算,以此类推,直到第四块,第四块完了后在进行反向传播计算梯度。那为什么训练过程在一定程度上可以做到并行呢,就想视频中弹幕提到的流水线,第一块计算完之后将结果传给第二块,然后第二块进行计算,但这里,第二块进行计算时不代表第一块他就歇了,他可以继续接受数据进行计算,但这里我有一个问题,如果说按流水线,4块卡里都有了数据,那么第四块卡计算完成后进行反向传播更新梯度时,第三块卡还在进行第二批数据的前向传播,此时更新的话,这里有影响吗?会产生什么样的影响?
以上就是我理解的,以及我的疑惑的地方。希望有大佬能够纠正我理解有误的地方,也希望有大佬能够为我解惑。


















 3万+
3万+




 到【灌水乐园】发言
到【灌水乐园】发言







