



首先声明,我也就是草寮的随便写写,有不对的地方,骂轻点
Lora回顾:
在模型训练时,经主要训练的大参数层进行平替并行性训练,如图
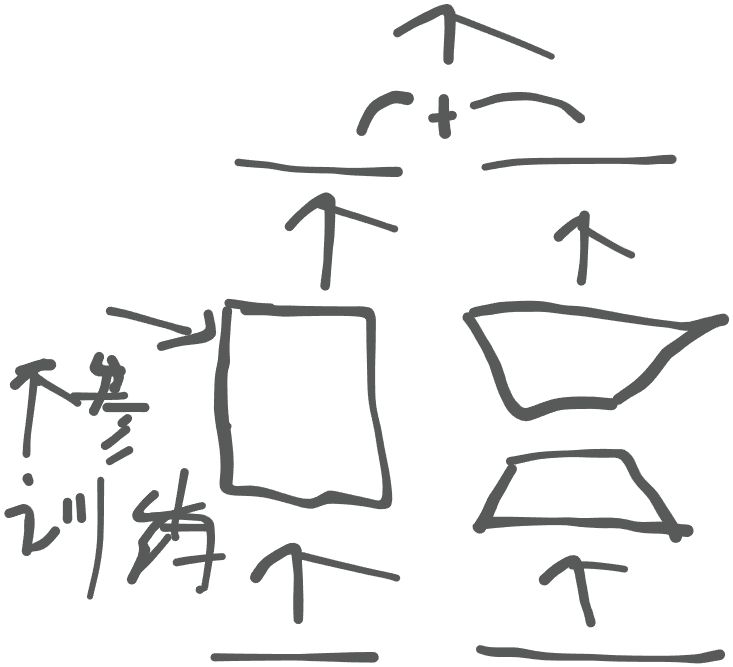
这个过程是怎样的呢?
在训练时,就相当于外挂一个参数层,这个参数层里面的参数来自原来的对应的层,
不过这个外挂的参数相对于之前的比如20000x768变成了两个低秩矩阵
20000x8和8x768
这个外挂的层就相当于将原来的参数量进行了一个缩减
那么在训练时,两个层是并行同时输入的,只不过原来的层不参与训练,外挂的层参与训练,
输入经过两个层输出之后再进行相加,得出这两个层共同的结果,然后只有外挂的层进行梯度的反向传播
我觉得原层目的是辅助外挂的层进行训练,只是我觉得奥~
训练完后,外挂的层再覆盖原来层对应的参数,实现一个合并,得到最终的训练的模型
综上所述,Lora只是在训练的时候依赖外挂低秩矩阵这一技术,只是训练了部分参数,加快了训练,但是训练完成后由于参数合并的操作,最终模型的大小是不改变的。
那么QLoRa呢?
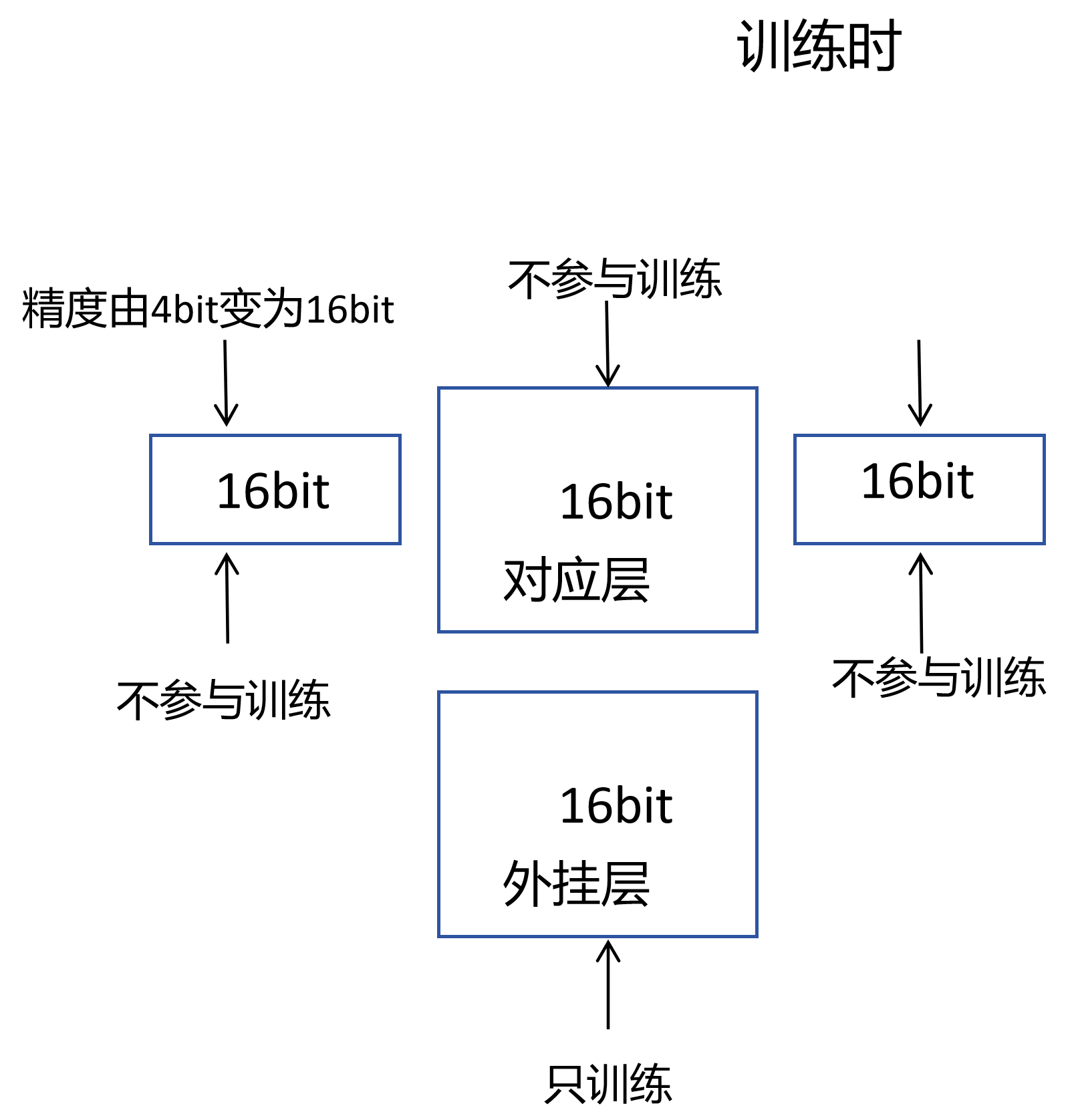
QLoRa是在Lora基础上,对于我们外挂层对应的层以外的其它的层,在训练的时候进行一个量化训练的操作,什么意思呢?
也就是原模型由16bit变为4bit
因为输入是16bit的,所以必须模型参数同样是16bit才能计算,那么在训练时,不参与训练的对应层的其它部分层在与输入做计算时变成16bit,他这部分负责完成后,他这部分变成4bit,意思就是计算时变回来
就是在训练模型对应需要训练的层的时候这部分参数采由4bit变16bit,但他们不参与训练,真正参与训练的是对应层的外挂层,最后保存的时候,这些不参与训练的层的参数仍然保存原来的精度。这就在一定程度上降低显存的使用,
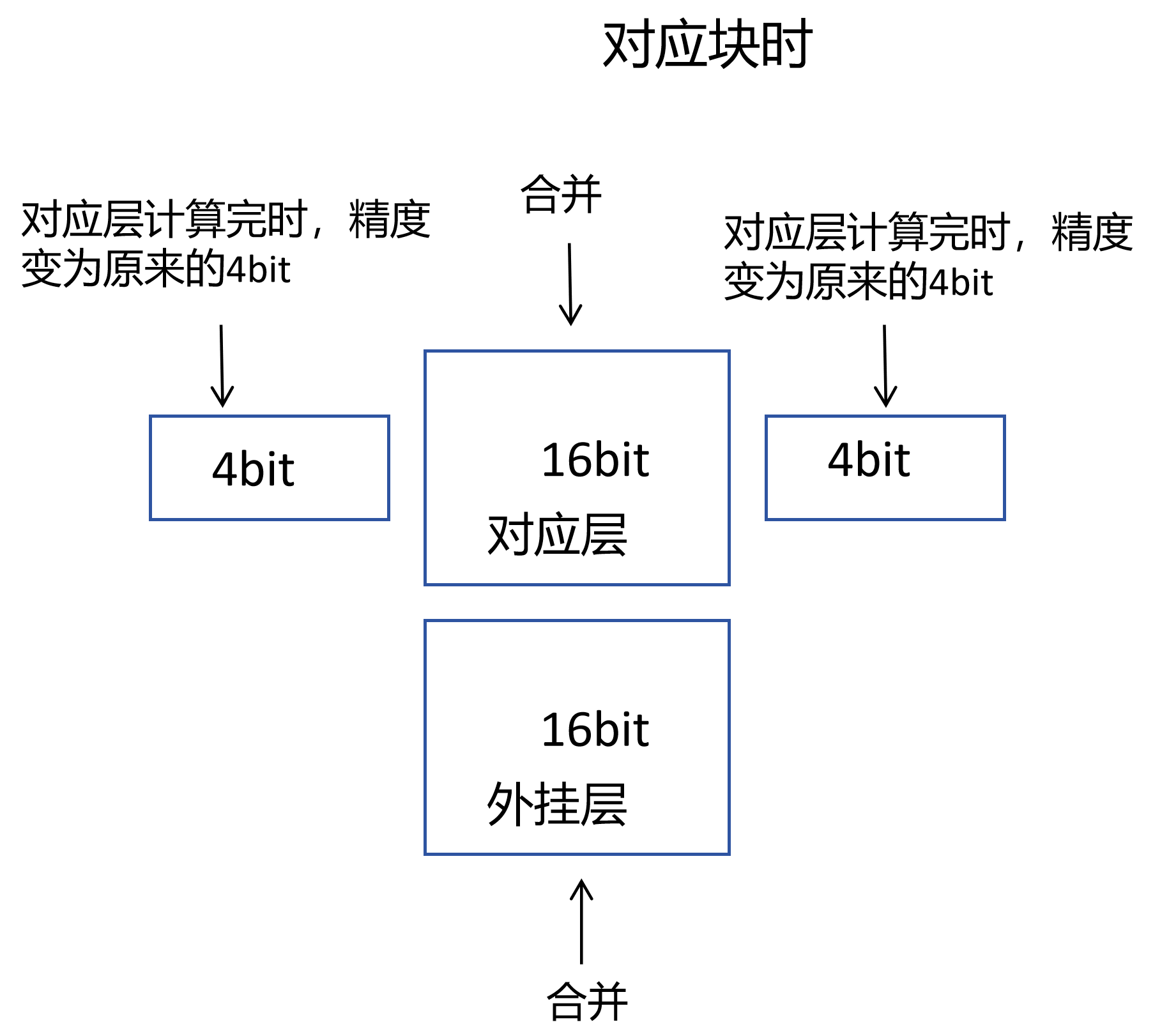
如图
这个图画的有点不对劲,他是第一个块该他计算了,他由4bit变成16bit,他计算完了就又变成4bit,也就是一层一层变,一层一层计算,一层一层变回4bit

















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









