




目录
1 概述
浪潮信息KOS是浪潮信息基于Linux Kernel、OpenAnolis等开源技术自主研发的一款服务器操作系统,支持x86、ARM等主流架构处理器,性能和稳定性居于行业领先地位,具备成熟的 CentOS 迁移和替换能力,可满足云计算、大数据、分布式存储、人工智能、边缘计算等应用场景需求。详细介绍见官网链接https://www.ieisystem.com/kos/product-kos-xq.thtml?id=12126
2 Ext4的延迟分配风险与防范
2.1 Ext4的延迟分配机制
Ext4文件系统在应用程序调用write的时候并不为缓存页面分配对应的物理磁盘块,当文件的缓存页面真正要被刷新至磁盘中时,ext4会为所有未分配物理磁盘块的页面缓存分配尽量连续的磁盘块。
Ext4文件系统结构示意图:
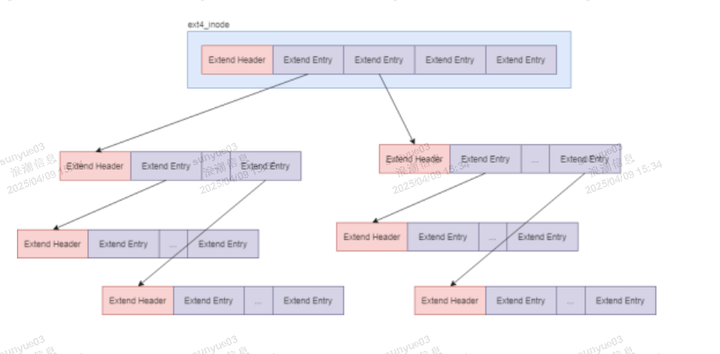
Linux文件系统Vfs层总是将应用程序的写入请求分割成页面(默认大小4KB)为单位,对于每个页面,VFS会检查其是否已经为其创建了buffer_head结构,如果没有创建,则为其创建buffer_head,否则检查每个buffer_head的状态,如该buffer_head是否已经与物理磁盘块建立映射等,这些功能是由write_begin()函数实现的,该函数是由VFS提供的一个接口,具体文件系统负责实现该接口,如ext3文件系统的ext3_write_begin()。而ext4如果采用了delay allocation特性的话,其实现的函数为ext4_da_write_begin()。
ext4_da_write_begin()会检查页面所有的buffer_head的状态,如buffer_head是否已经建立映射等,对于没有建立映射的buffer_head,需要将其与物理磁盘块建立映射关系,调用的函数是ext4_da_get_block_prep(),该函数又调用了ext4_map_blocks()来建立逻辑块和物理磁盘块的映射关系,如果启用extent特性的话,那么该函数又调用了ext4_ext_map_blocks(handle, inode, map, 0)来建立这种映射关系,之所以列举该函数的参数是要特别注意其最后一个参数0,这是一个标志位,调用者ext4_map_blocks()将该标志位设置为0,告诉被调用者,如果没有建立映射关系,那么此刻无需真正地分配物理磁盘块。这在ext4_ext_map_blocks函数中可以看到会有对该标志位的判断。就不再详细列举代码了。因为在ext4_map_blocks()中并没有建立映射关系,因此其向ext4_da_get_block_prep()返回0,表示没有映射,在ext4_da_get_block_prep()函数中判断如果返回值为0,那么为当前block设置标志位BH_New,BH_Mapped,BH_Delay(表示该块在写入的时候再进行延迟分配)。

以上我们确认了在ext4中延迟分配的前半部分,即应用程序将数据写入文件时只是简单地将数据以页面为单位写入页面缓存中,而并不真正地为其分配物理磁盘块。接下来我们要弄明白的是,ext4何时会为缓存中未分配物理磁盘块的缓存分配磁盘空间。
当刷新线程开始将脏的缓存页面写回至物理磁盘时,根据我们之前的描述,回写线程会以文件为单位进行回写,即对脏inode链表上的所有脏inode依次回写。对于每个脏inode(也即每个脏的文件),回写线程会将inode上的所有脏页面进行回写,这时候就需要判断每个脏页面的状态了。
回写线程中实现的时候将一个文件的脏页面分多次进行回写,每个回写一部分脏页面。关于回写机制可参考Linux的“脏页面回写机制”。回写脏页面最终调用到函数writepages,与writebegin一样,它也是VFS提供的一个虚拟接口,由具体文件系统负责相应的实现。对于采用延迟分配的ext4文件系统来说,该函数的具体实现是ext4_da_writepages()。该函数中实现的时候有三个要点:
要将逻辑上连续的脏且尚未建立磁盘块映射到物理页面形成一个extent,以便可采用ext4的mblock分配策略提升文件连续性,这也是我们后面要介绍的内容;
对1中连续页面形成的extent,为其进行磁盘块分配,分配采用了ext4的mblock allocation策略。
提交2中的extent至bio层完成脏页面的写入,此时已经为尚未映射的缓存页面分配了物理磁盘块。

上图描述了延迟分配的核心思想:等到刷新脏缓存页面时再建立脏页面与物理磁盘块之间的联系,而且,分配之前将逻辑上连续的文件块映射至物理上连续的磁盘块。在ext4_da_writepages()函数中调用了三个非常重要的函数来完成上述功能:write_cache_pages_da()负责将逻辑上连续的文件块合并成一个extent;mpage_da_map_blocks()负责为合并后的extent建立映射关系;mpage_da_submit_io()负责提交上面映射的extent。
2.2 Ext4延迟分配带来的风险
Ext4的延迟分配存在一些风险,风险如下:
| 数据丢失风险 | 如果系统在数据被写入磁盘前崩溃或断电,那么这部分延迟分配的数据可能会丢失。 |
|---|---|
| 性能问题 | 虽然延迟分配可以提高小文件写入的性能,但在某些情况下(如大量小文件写入或频繁的文件系统元数据更新),可能会导致性能下降,因为需要额外的处理来管理内存中的缓冲区。 |
| 磁盘空间管理 | 延迟分配可能导致磁盘空间的管理变得更加复杂,特别是在文件系统接近满时,因为实际的磁盘空间使用情况可能并不反映实际的文件大小。 |
2.3 Ext4延迟分配风险如何防范
上一章节罗列了Ext4延迟分配存在的风险,这一章节我们来说明一下如何防范,防范措施如下:
| 定期同步 | 定期运行 sync 命令或调用 fsync() 来强制将内存中的数据写入磁盘。这可以通过编写脚本定期执行或使用系统监控工具(如 cron)来实现。对于数据库或关键应用,应在每次事务结束后调用 fsync() 来确保数据的一致性和完整性。 |
|---|---|
| 使用电池备份的 UPS | 在关键服务器上使用带电池备份的 UPS 可以减少因突然断电导致的数据丢失风险。UPS 可以在电源故障时提供短时间的电力支持,确保系统可以安全关闭。 |
| 监控和日志 | 监控文件系统的健康状态和性能指标,如使用 iostat、vmstat 等工具监控磁盘 I/O 和内存使用情况。定期检查和分析日志文件,如 /var/log/messages 或通过 dmesg 命令查看内核消息,以识别任何可能影响文件系统完整性的问题。 |
| 定期备份 | 定期备份重要数据到另一个存储介质,确保在发生数据丢失时可以从备份中恢复。使用如 rsync 的工具进行增量备份,可以减少备份窗口并提高效率。 |
| 更新和维护 | 确保操作系统和文件系统的更新和补丁是最新的,以利用最新的功能和安全修复。定期检查和优化文件系统,如使用 e2fsck(对于 ext3/ext4)来检查和修复文件系统错误。 |
3 XFS的B+树结构优势分析
3.1 XFS文件系统设计背景
诞生背景与技术定位
1994年,硅谷图形公司(SGI)为应对影视渲染行业对大规模文件存储(TB级文件)和高并发访问的严苛需求,推出了革命性的XFS文件系统。其核心设计目标聚焦于:
| 超大容量支持 | 突破传统文件系统的PB级存储限制 |
|---|---|
| 高性能I/O | 满足非线性编辑场景下的低延迟需求 |
| 元数据可靠性 | 保障长时间运行时的数据一致性 |
| 动态扩展能力 | 支持在线扩容和碎片整理 |
技术里程碑:XFS率先将B+树引入文件系统核心架构,创新性地应用于元数据管理(inode)、空间分配(Extent)和目录结构三大关键领域,奠定了现代高性能文件系统的设计范式。
3.2 B+树核心特性与磁盘优化
B+树基础架构
结构类似如下:

B+树作为平衡多路搜索树,具有以下核心特征:
| 多叉树结构 | 单个节点可存储nn个键值(通常匹配磁盘页大小) |
|---|---|
| 分层索引 | 内部节点仅存储键值和子节点指针叶子节点存储实际数据并形成双向链表 |
| 高度平衡 | 所有叶子节点位于同一层级 |
磁盘存储优化原理
B+树的优势在磁盘存储场景下被显著放大:
| I/O效率最大化 | 单个节点大小设置为磁盘页(通常4KB),通过减少树高降低寻道次数。例如:4阶B+树存储100万记录仅需log4(106)≈10log4(106)≈10次I/O相同数据量二叉搜索树需要log2(106)≈20log2(106)≈20次I/O |
|---|---|
| 顺序访问优化 | 叶子节点链表结构使范围查询性能提升3-5倍,特别适合视频编辑等连续读写场景。 |
| 写优化机制 | 采用延迟分裂(Delayed Split)和批量合并技术,减少元数据更新次数。 |
3.3 XFS中的B+树创新应用
动态Extent管理
Extent核心概念:

每个Extent记录连续物理块的起止位置,相比传统块映射表节省90%元数据空间。
B+树与Extent的协同
XFS Extent B+树示意图:

XFS通过两棵B+树实现高效空间管理:
| Allocation B+Tree (ABT) 分配B+树(ABT) | 跟踪空闲空间块,采用(起始块, 长度)键值对,支持:最优适配算法:查找长度≥需求的空闲区快速合并:相邻空闲区自动合并 |
|---|---|
| Mapping B+Tree (MBT) 映射B+树 | 记录文件物理块分配,键值为文件逻辑偏移,实现:O(logn)O(logn)复杂度定位任意文件位置大规模稀疏文件的高效管理 |
Inode高效管理
动态Inode分配机制,XFS突破传统固定inode表限制,创新设计:
| Inode B+Tree | 按需动态分配inode |
|---|---|
| Chunk分配 | 以64个inode为单元分配存储空间 |
| 区位策略 | 将inode分配到靠近相关数据的磁盘区域 |
优势对比:

目录结构优化
B+Tree目录组织:

XFS目录实现突破性创新:
| 哈希加速 | 计算文件名哈希值作为B+树键 |
|---|---|
| 分层存储 | 小目录:线性结构(<100条目)中目录:块目录结构大目录:B+树索引 |
| 节点缓存 | 热点目录节点常驻内存 |
性能测试(100万文件目录):

3.4 XFS B+树架构优势分析
性能维度
吞吐量对比
文件系统吞吐量对比图(随机读写):

在NVMe SSD上的FIO测试(4K随机写):

延迟优化:
B+树的高度平衡特性使操作延迟标准差降低40%,保障多媒体处理的实时性要求。
扩展性优势
容量线性扩展
通过B+树的分层索引,XFS实现:
| 最大文件尺寸 | 8EB(exabyte) |
|---|---|
| 最大文件系统 | 16EB |
| 目录条目数 | 理论无上限 |
对比测试(创建1000万文件):

可靠性增强
日志系统创新
XFS采用双日志机制:
| 元数据日志 | 记录B+树结构变更 |
|---|---|
| 数据日志 | 可选记录数据变更 |
故障恢复对比:

3.5 工程实践优化
延迟分配技术
写入流程优化:

减少元数据更新次数
提升连续写入概率
降低碎片产生
动态Inode创建
传统文件系统在格式化时预分配inode,XFS实现:
| 按需分配 | 首次写入文件时创建inode |
|---|---|
| 空间复用 | 删除文件后inode空间可回收 |
| 区位优化 | inode靠近关联数据存储 |
并行化设计
多粒度锁机制

3.6 现存挑战
| 小文件场景 | 单个inode 512字节可能造成空间浪费 |
|---|---|
| 碎片问题 | 长期随机写入后性能下降约15% |
| 内存占用 | B+树缓存需要较大内存支撑 |
3.7 关键参数调优
# 格式化参数示例
mkfs.xfs -b size=4096 -d agcount=32 /dev/sdb

# 挂载参数优化
mount -o noatime,nodiratime,logbsize=256k /dev/sdb /data
![]()
调优矩阵:

4 Btrfs的写时复制原理实践
4.1 Btrfs 写时复制(CoW)文件系统
相比 ext4,Btrfs 拥有的杰出特性之一是,它是一个 写时复制(Copy-on-Write)(CoW)文件系统。当一个文件被改变和回写磁盘,它不会故意写回它原来的位置,而是被复制和存储在磁盘上的新位置。从这个意义上,可以简单地认为 Cow 是一种 “重定向”,因为文件写入被重定向到不同的存储块上。
这听起来很浪费,但实际上并不是。这是因为被修改的数据无论如何一定会被写到磁盘上,不管文件系统是如何工作的。Btrfs 仅仅是确保了数据被写入在之前没被占据的块上,所以旧数据保持完整。唯一真正的缺点就是这种行为会导致文件碎片化比其他文件系统要快。在日常的电脑使用中,你不太可能会注意到这点差异。
CoW 的优势在哪里?简单的说:文件被修改和编辑的历史被保存了下来。Btrfs 保存文件旧版本的引用(inode)可以轻易地被访问。这个引用就是快照:文件系统在某个时间点的状态镜像。
除了保存文件历史,CoW 文件系统永远处于一致的状态,即使之前的文件系统事务(比如写入一个文件)由于断电等原因没有完成。这是因为文件系统的元数据更新也是写时复制的:文件系统本身永远不会被覆写,所以中断不会使其处于部分写入的状态。
对文件的写时复制
可以将文件名视为对 inode 的指针。在写入文件的时候,Btrfs 创建一个被修改文件内容(数据)的拷贝,和一个新的 inode(元数据),然后让文件名指向新的 inode,旧的 inode 保持不变。下面是一个假设示例来阐述这点:

这里 myfile.txt 增加了三个字节。传统的文件系统会更新中间的 Data 块去包含新的内容。CoW 文件系统不会改变旧的数据块(图中灰色),写入(复制)更改的数据和元数据在新的地方。值得注意的是,只有被改变的数据块被复制,而不是全部文件。
如果没有空闲的块去写入新内容,Btrfs 将从被旧文件版本占据的数据块中回收空间。
对目录的写时复制
从文件系统的角度看,目录只是特殊类型的文件。与常规文件不同,文件系统直接解释数据块的内容。一个目录有自身的元数据(inode,就像上面说的文件一样)去记录访问权限或修改时间。最简单的形式,存在目录里的数据(被叫作目录项)是一个 inode 引用的列表,每个 inode 又是另外的文件或目录。但是,现代文件系统在目录项中至少会存储一个文件名和对应的 inode 引用。
之前已经指出,写入一个文件会创建之前 inode 的副本,并相应修改其内容。从根本上,这产生了一个和之前无关的新的 inode 。为了让被修改的文件对文件系统可见,所有包含这个文件引用的目录项都会被更新。
这是一个递归的过程!因为一个目录本身是一个带有 inode 的文件。修改目录里的任何一项都会为这个目录文件创建新的 inode 。这会沿着文件系统树递归直到文件系统的根。
所以,只要保留对任何旧目录的引用,并且这些目录没有被删除和覆写,就可以遍历之前旧状态的文件系统树。这就是快照的功能。
4.2 原理结合实践
下面我们用原理讲解与实际操作结合来更好的熟悉Btrfs的写时复制原理:
Btrfs基本文件组织
在Btrfs中,文件系统的组织结构与Git非常相似:普通文件类似于Git中的blob对象,而目录则对应Git中的tree对象。以Linux的根目录为例,它是一个tree对象,其中包含了文件(blob对象)以及子目录(子tree对象)。

在Btrfs中,这些Tree对象被称为子卷(Subvolume)。子卷是Btrfs的一个核心概念,它本质上是一个特殊的目录,能够捕获并保存特定时刻的文件系统状态。这与快照(Snapshot)的概念密切相关。
首先安装btrfs
yum install btrfs-progs

重启系统
查看btrfs内核模块是否加载
lsmod | grep btrfs

创建一个brtfs文件系统,如:mkfs.btrfs -f /dev/vdc3

创建一个目录并将/dev/vdc3挂载到该目录:
mkdir /test1
mount /dev/vdc3 /test1

创建一个空子卷的命令为btrfs subvolume create <path>
例如,要在/test1下创建一个名为my_subvol的空子卷:
btrfs subvolume create /test1/my_subvol

Btrfs子卷具有双重特性:它既可以作为普通目录在文件系统中进行管理,又可以像独立的分区一样被挂载到Linux系统的任意挂载点。这种灵活的特性为实现系统级别的快照和回滚功能奠定了重要基础。
快照
Btrfs实现了一种称为快照(Snapshot)的机制来保存文件系统的历史状态。在Btrfs中创建快照时,系统只会复制tree对象的结构,而不会复制实际的文件内容。这种设计与Git的存储机制非常相似:不同的快照之间会共享相同的文件数据(blob对象),每个快照只需要存储发生变化的部分。这种写时复制(Copy-on-Write)的策略使得快照操作既快速又节省存储空间。

在Btrfs的实现中,子卷和快照共享相同的底层数据结构。它们的主要区别在于创建方式:子卷可以作为独立的空白容器创建,而快照则必须基于现有的子卷创建,并会继承该子卷的全部数据状态。

btrfs创建快照的命令
创建一个名为snap的快照:
btrfs subvolume snapshot -r /path/to/subvolume /path/to/snap
在拍摄快照的时候 -r参数代表创建一个只读快照。在这种情况下,快照只允许读取数据,不能进行写入操作。
例如:
btrfs subvolume snapshot -r /test1/my_subvol /test1/snap

快照的恢复
虽然Btrfs没有提供快照的直接恢复机制,但由于快照本质上是一个只读的子卷,我们可以直接访问快照中的文件内容。这种特性使得快照特别适合于选择性文件恢复的场景,用户可以方便地浏览快照中的文件,并选择所需的文件进行恢复。
首先查看系统中的快照
# 列出指定Btrfs文件系统中的所有子卷和快照
# 参数为Btrfs文件系统的挂载点或者子卷路径
btrfs subvolume list /test1

输出结果中的path字段显示了每个子卷的路径。通常情况下,我们可以直接通过这个路径访问快照的内容。但需要注意的是,如果你的系统本身就安装在Btrfs文件系统上(根目录挂载在@子卷),那么这些快照可能无法通过常规路径直接访问,因为它们位于Btrfs文件系统的根层级。
手动挂载
linux的mount在挂载Btrfs的时候,同时支持挂载的子卷或快照。这样我们同样实现了查看快照内容的目的。
# 挂载快照
# 手动挂载快照以访问
sudo mount -o subvol=快照路径 /dev/硬盘 /mnt/临时目录
虽然单个文件的恢复需要一些额外步骤,但对于整个系统的恢复,Btrfs提供了更优雅的解决方案:GRUB引导加载器支持直接从Btrfs的子卷或快照启动系统。这意味着我们可以在启动时选择任意一个系统快照作为根文件系统,从而实现完整的系统状态回滚。
从GRUB配置中可以看到,通过在rootflags参数中指定subvol选项,我们可以轻松地选择要启动的Btrfs子卷或快照。这种优雅的设计使得系统回滚变得异常简单。
insmod ext2
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root 35669a62-1315-4b0b-be17-92f89eebffc2
else search --no-floppy --fs-uuid --set=root 35669a62-1315-4b0b-be17-92f89eebffc2
fi
echo 'Loading Snapshot: 2024-10-28 16:48:06 .snapshots/1/snapshot'
echo 'Loading Kernel: vmlinuz-6.8.0-51-generic ...'
linux "/vmlinuz-6.8.0-51-generic" root=UUID=0841c522-e696-4499-8f39-3de52d1a4120 rootflags=defaults,subvol=".snapshots/1/snapshot"
echo 'Loading Initramfs: initrd.img-6.8.0-51-generic ...'
initrd "/initrd.img-6.8.0-51-generic"
在上面的GRUB启动linux的参数中,rootflags中的subvol就是启动linux目录的btrfs子卷或快照。
Btrfs快照备份
Btrfs同样也支持把快照同步到外部存储设备上。命令也很简单
sudo btrfs send /path/to/snapshot | pv > 备份文件路径
例如:
btrfs send /test2/my_snap | pv > /test1/snap1

没有pv工具可以先去官网(https://www.ivarch.com/programs/pv.shtml)下载对应的rpm包,rpm -ivh安装即可

因为btrfs send 发送快照的时候,默认使用输出,并且没有任何进度提示。使用pv命令可以实现进度提示,也可以在less后面直接使用gzip或者tar等命令实现快照的压缩。
btrfs send /test2/my_snap | pv | gzip > /test1/snap1.gz

btrfs send命令需要快照为可读才能被发送到外部设备。如果快照不是可读,你需要下面的命令去设置快照为可读属性
btrfs prop set /test2/my_snap ro false

ro为true代表把快照设置为可读,false代表把快照设置为可读可写。
Btrfs 快照恢复
Btrfs同样也支持从外部存储设备恢复快照。命令也很简单
pv 备份文件路径 | btrfs receive /path/to/subvolume
例如:
pv /test1/snap1 | btrfs receive /test2/my_snap

可以配合btrfs快照备份功能与Grub的启动参数,实现间接的系统迁移。
本文系统讲解了文件系统的一些黑科技,本系列共4篇,链接如下:

















 3542
3542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









