




目录
3.1 文件描述符(File Descriptor, FD)
1 概述
浪潮信息KOS是浪潮信息基于Linux Kernel、OpenAnolis等开源技术自主研发的一款服务器操作系统,支持x86、ARM等主流架构处理器,性能和稳定性居于行业领先地位,具备成熟的 CentOS 迁移和替换能力,可满足云计算、大数据、分布式存储、人工智能、边缘计算等应用场景需求。详细介绍见官网链接https://www.ieisystem.com/kos/product-kos-xq.thtml?id=12126
2 VFS虚拟文件系统的设计哲学
对于用户来说,所有操作都是通过open、read、write、ioctl、close等接口操作的,确实很方便;但是对于linux,底层明明是不同的硬件设备,这些设备怎么才能统一被上述接口识别和适配了?识别和适配这层接口的功能就是虚拟文件系统,简称VFS,VFS(Virtual File System)是Linux内核中实现文件系统抽象的核心模块,其设计哲学深刻体现了UNIX“一切皆文件”的思想,同时通过分层抽象和统一接口实现了对异构文件系统的无缝兼容。以下是其核心设计理念与实现机制的综合分析:
2.1 “万物皆文件”的统一抽象
VFS的核心理念源于UNIX哲学,将设备、管道、套接字、进程信息等非传统文件对象抽象为文件形式。例如:
设备文件(如/dev/sda)通过VFS接口被读写,内核将其映射到对应的设备驱动程序,整体架构图如下:
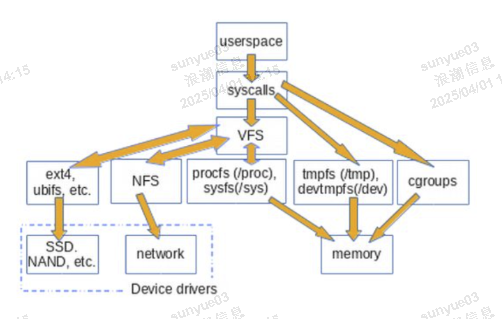
网络套接字通过/proc/net等虚拟文件系统暴露状态信息,用户可通过文件操作接口访问。

进程信息通过/proc/<pid>目录以文件形式展示,如/proc/self/maps反映进程内存布局。
设计意义:统一的文件接口简化了用户态与内核的交互,开发者无需为不同对象学习多种API。

2.2 分层抽象模型
VFS通过分层设计实现接口统一性与底层多样性的平衡,分为三个层次:
用户接口层:提供open()、read()、write()等系统调用,用户程序通过文件描述符(File Descriptor)操作文件,当用户调用操作系统提供的文件系统API时会通过软中断的方式调用内核VFS实现的函数。如下表所示是部分文件API与内核VFS函数的对应关系:

虚拟文件系统层:定义通用文件模型(struct inode、struct dentry、struct file),并维护目录缓存(dcache)加速路径解析,VFS 定义了一组通用接口(如 struct file_operations),具体文件系统需实现这些接口:

具体文件系统层:各文件系统(如Ext4、XFS)实现VFS定义的接口(如inode_operations、file_operations),完成实际I/O操作。

示例:比如 Linux 写一个文件:
int ret = write(fd, buf, len);
调用了write()系统调用,它的过程简要如下:
首先,勾起 VFS 通用系统调用sys_write()处理。
接着,sys_write()根据fd找到所在的文件系统提供的写操作函数,比如op_write()。
最后,调用op_write()

2.3 多态与松耦合机制
VFS通过函数指针表实现多态,允许不同文件系统自定义行为:
超级块(super_block):存储文件系统元数据,并关联super_operations结构,定义挂载、同步等方法,super_operations的定义如下:

inode操作集(inode_operations):包含文件创建、删除、重命名等操作,由具体文件系统实现(如Ext4的ext4_create()),inode结构有两个指针(i_op和i_fop),指向实现了上述抽象的数组。一个数组与特定于inode的操作有关,另一个数组则提供了文件操作。file_operations用于操作文件中包含的数据,而inode_operations负责管理结构性的操作(例如删除一个文件)和文件相关的元数据(例如,属性)。所有inode操作都集中到以下结构中:

inode_operations的部分函数说明如下:
| lookup | 根据文件系统对象的名称(表示为字符串)查找其inode实例 |
|---|---|
| link | 用于删除文件。但根据上文的描述,如果硬链接的引用计数器表明该inode仍然被多个文件使用,则不会执行删除操作 |
| xattr | 函数建立、读取、删除文件的扩展属性,经典的UNIX模型不支持这些属性。例如,可使用这些属性实现访问控制表(access control list,简称ACL) |
| truncate | 修改指定inode的长度。该函数只接受一个参数,即所处理的inode的数据结构。在调用该函数之前,必须将新的文件长度手工设置到inode结构的i_size成员 |
| truncate_range | 用于截断一个范围内的块(即,在文件中穿孔),但该操作当前只有共享内存文件系统支持。follow_link根据符号链接查找目标文件的inode。因为符号链接可能是跨文件系统边界的,该例程的实现通常非常短,实际工作很快委托给一般的VFS例程完成 |
| fallocate | 用于对文件预先分配空间,在一些情况下可以提高性能。但只有很新的文件系统(如Reiserfs或Ext4)才支持该操作 |
文件操作集(file_operations):实现read()、write()等具体I/O逻辑,例如块设备与字符设备的读写差异, 各个file实例都包含一个指向struct file_operations实例的指针,该结构保存了指向所有可能文件操作的函数指针。该结构定义如下:

仅当文件系统以模块形式装载并未编译到内核中时,才使用owner项。该项指向在内存中表示模块的数据结构。
| read和write分别负责读写数据。这两个函数的参数包括文件描述符、缓冲区(放置读/写数据)和偏移量(指定在文件中读写数据的位置),另一个参数指定了需要读取和写入的字节数目。 |
|---|
| aio_read用于异步读取操作。 |
| open打开一个文件,这相当于将一个file对象关联到一个inode。 |
| file对象的使用计数器到达0时,调用release。换句话说,即该文件不再使用时。这使得底层实现能够释放不再需要的内存和缓存内容。 |
| 如果文件的内容映射到进程的虚拟地址空间中,访问文件就变得很容易。这通过mmap完成 |
| readdir读取目录内容,因此只对目录对象适用。 |
| ioctl用于与硬件设备通信,因而只能用于设备文件(不能用于其他对象,因为其他对象对应的file_operations中,ioctl为NULL指针)。在有必要向设备发送控制命令时,将使用该方法(write函数用于发送数据)。尽管该函数对所有外设的名称和调用语法都相同,但实际支持的命令与具体硬件相关。 |
| poll用于poll和select系统调用,以便实现同步的I/O多路复用。这意味着什么?在进程等待来自文件对象的输入数据时,需要使用read函数。如果没有数据可用(在进程从外部接口读取数据时,可能有这样的情况),该调用将阻塞,直至数据可用。如果一直没有数据,read函数将永远阻塞,这将导致不可接受的情况出现。 |
优势:新增文件系统只需实现接口,无需修改内核其他模块,极大提升了扩展性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









