



前言
最近的课程设计是与数字人有关的项目,这里简短记录一下如何实现一个数字人,希望能帮大家规避一些坑(´▽`ʃ♡ƪ)
主要参考了如下教程:
用Audio2Face导出驱动MetaHuman的面部动画_metahuman audio2face、-优快云博客
https://blog.youkuaiyun.com/Wenhao_China/article/details/135369976
https://github.com/metaiintw/build-an-avatar-with-ASR-TTS-Transformer-Omniverse-Audio2Face
https://blog.youkuaiyun.com/ljason1993/article/details/129995288
环境配置
具体的环境配置已经在上述链接中提到,流程如下
-
下载Omniverse
-
在Omniverse中下载audio2face
-
下载如果卡条的话就进入log中找到下载链接,直接从链接下载,然后删除原有的zip包,具体流程可以看相关教程(‾◡◝)
-
编程环境,下载一个pyhton3.8以上的虚拟环境吧,稳妥一点,然后就pip install openai(具体的实现代码可以参考我下方的实现)但是api-key可得自己充钱哦✪ ω ✪,教程在这: https://api-docs.deepseek.com/zh-cn/updates/
-
如果想自己体验捏脸的乐趣的话,可以在metahuman官网捏一个 https://metahuman.unrealengine.com/mhc ,然后导入ue,或者直接下载现成的 https://www.fab.com/listings/0281d63e-71f7-4e07-a344-5fa721ac4d35 登录自己的epic账号下载即可
-
差点儿忘了,记得下载一个UE5.3(o゜▽゜)o☆,因为要和audio2face的插件适配上,我们首先要在关联Audio2Face的目录中找到适配UE版本的插件
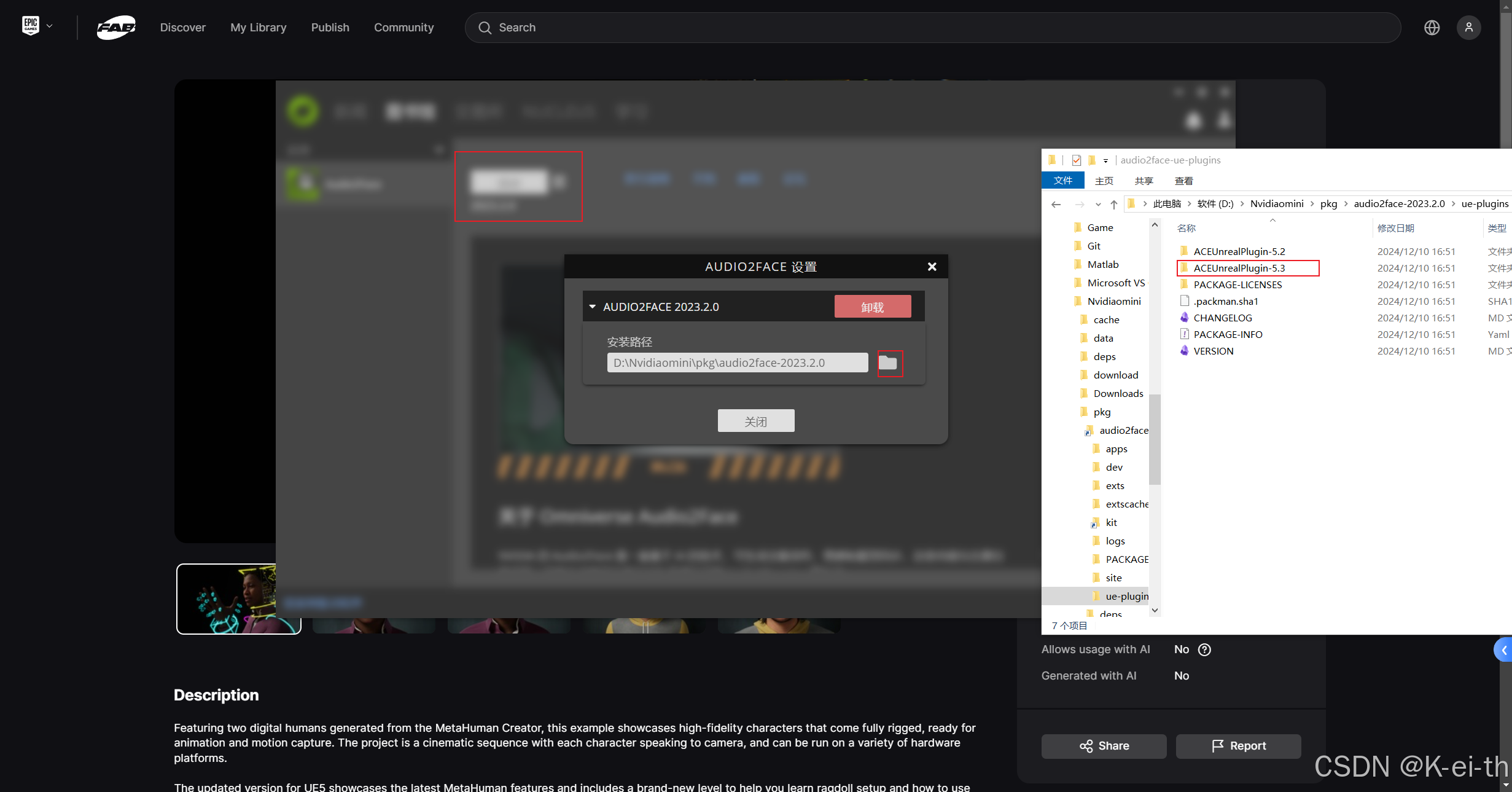
-
然后把插件拷贝到UE对应的插件目录下
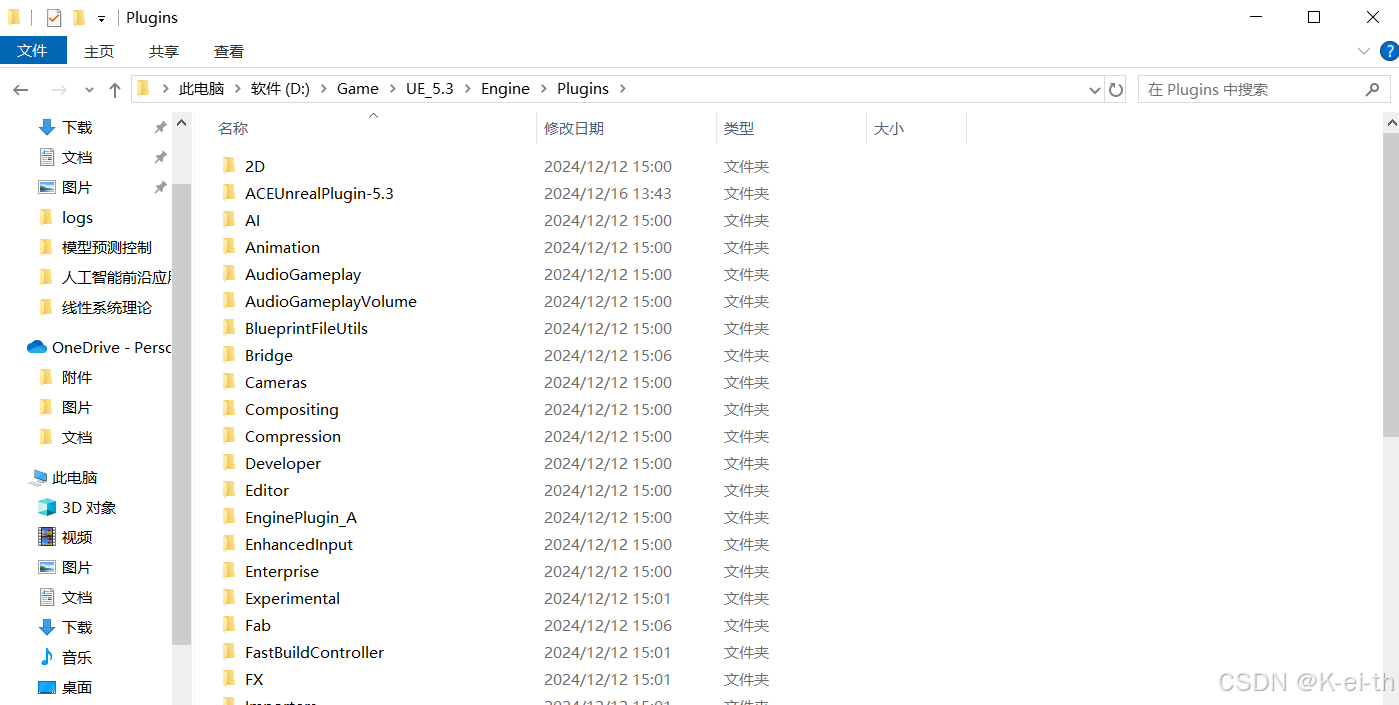
模型关联流
经过上述的操作之后我们终于可以看数字人张嘴啦(bushi,接下来让我们启动audio2face!
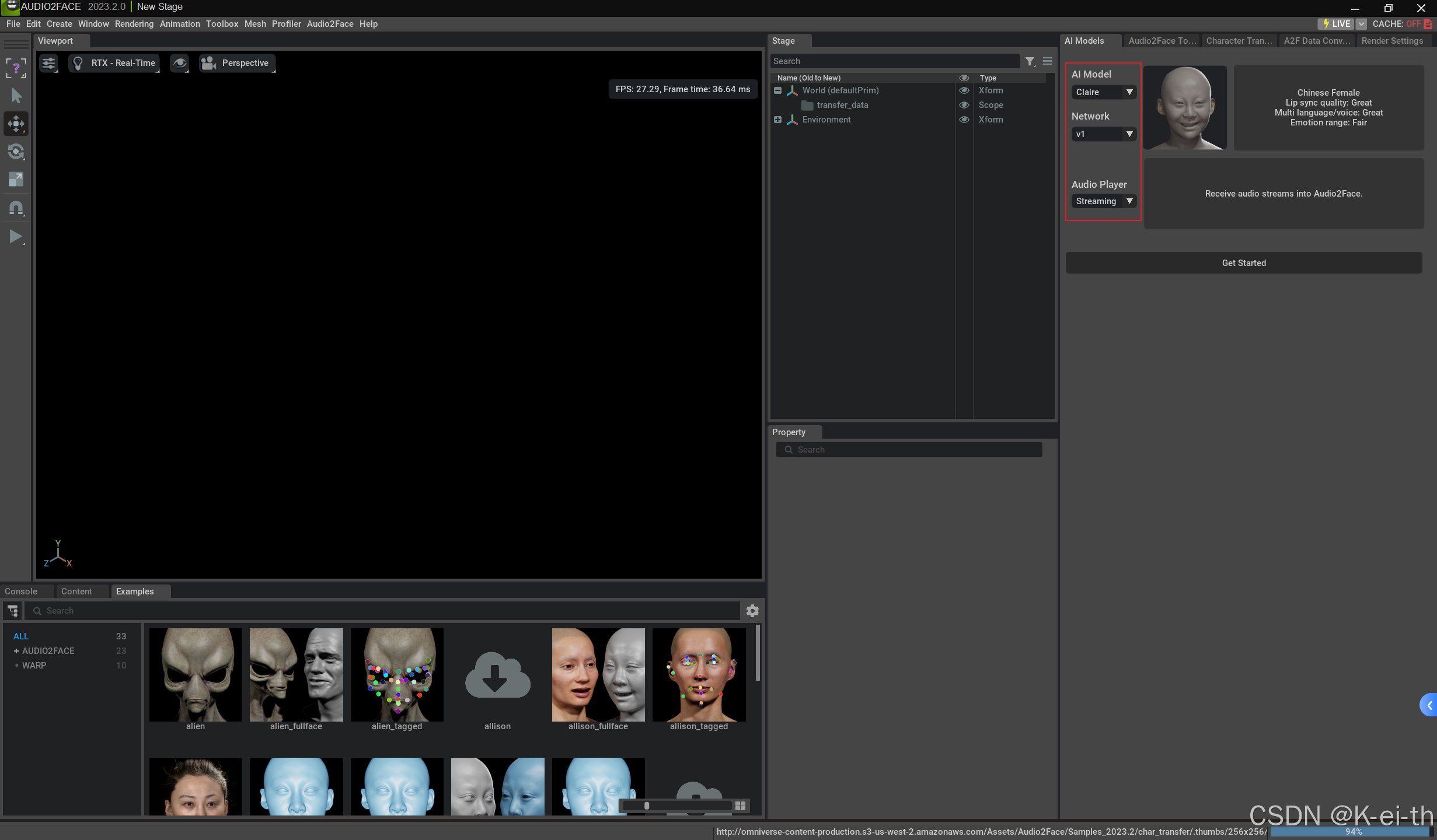
首先咱们要在AI Model中选择亚洲人面孔(看你项目情况嗷ヾ(•ω•`)o
选择流式输入,然后get started!
导入带有求解器的usd文件(或许你们在example里能下载成功?我不行所以就是自己导入的,加这个群里面有捏 http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=q1-5RLm0FRt75SI2irLx3Lw3A9Ic0gcS&authKey=NKcPb4%2FrUtsuYFmxnxY8kv%2BrY8MT7p4H2KdLnZ%2BIK0MIUmB8QQ0s4mfN%2BcaAAPBP&noverify=0&group_code=547033086)
或者这个 https://forums.developer.nvidia.com/t/mark-solved-arkit-audio2face-2023-1-0-is-not-working/261116
btw USD 文件通常是文本格式(ASCII)或二进制格式,核心组件包括:
- 几何体描述(如网格、曲线)
- 材质和着色
- 动画和变换
- 场景分层(Layers)
- 引用和实例
- 变体(Variants)
导入之后我们在StreamLivelink中选择激活,然后记住端口号,这个后面要和UE中的插件关联起来
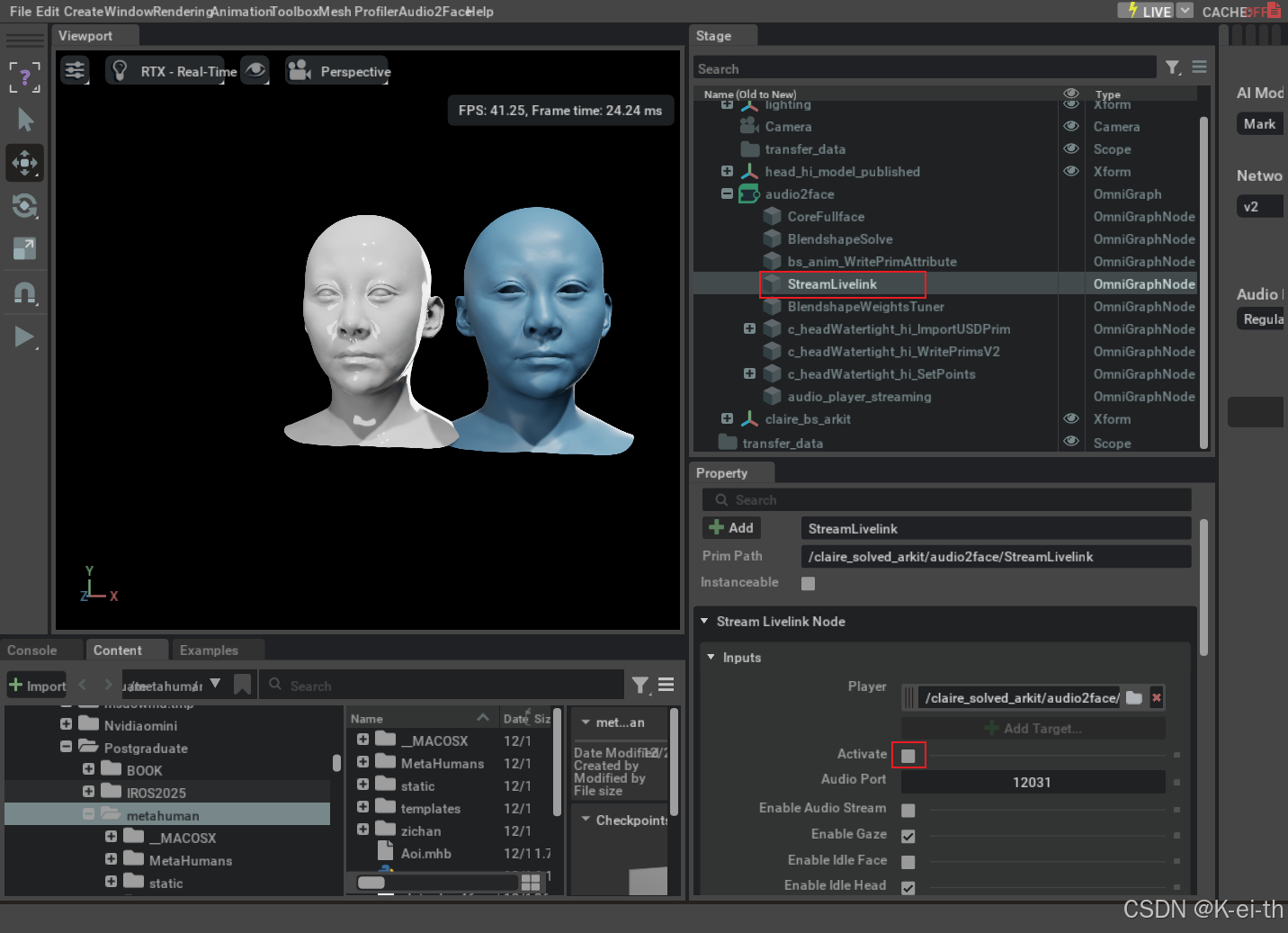
接着我们打开audio2face组件,加入一个音频流播放模块
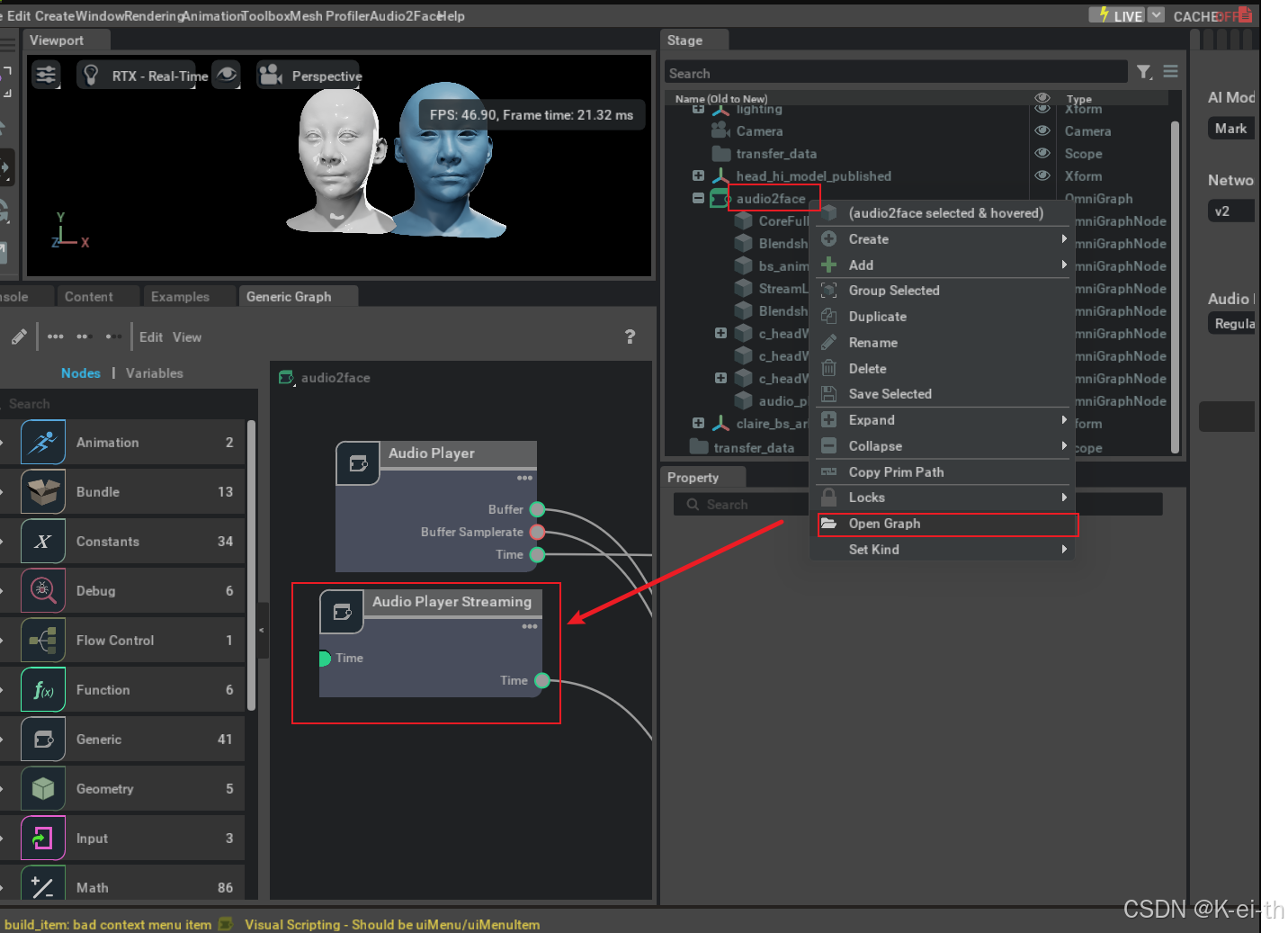
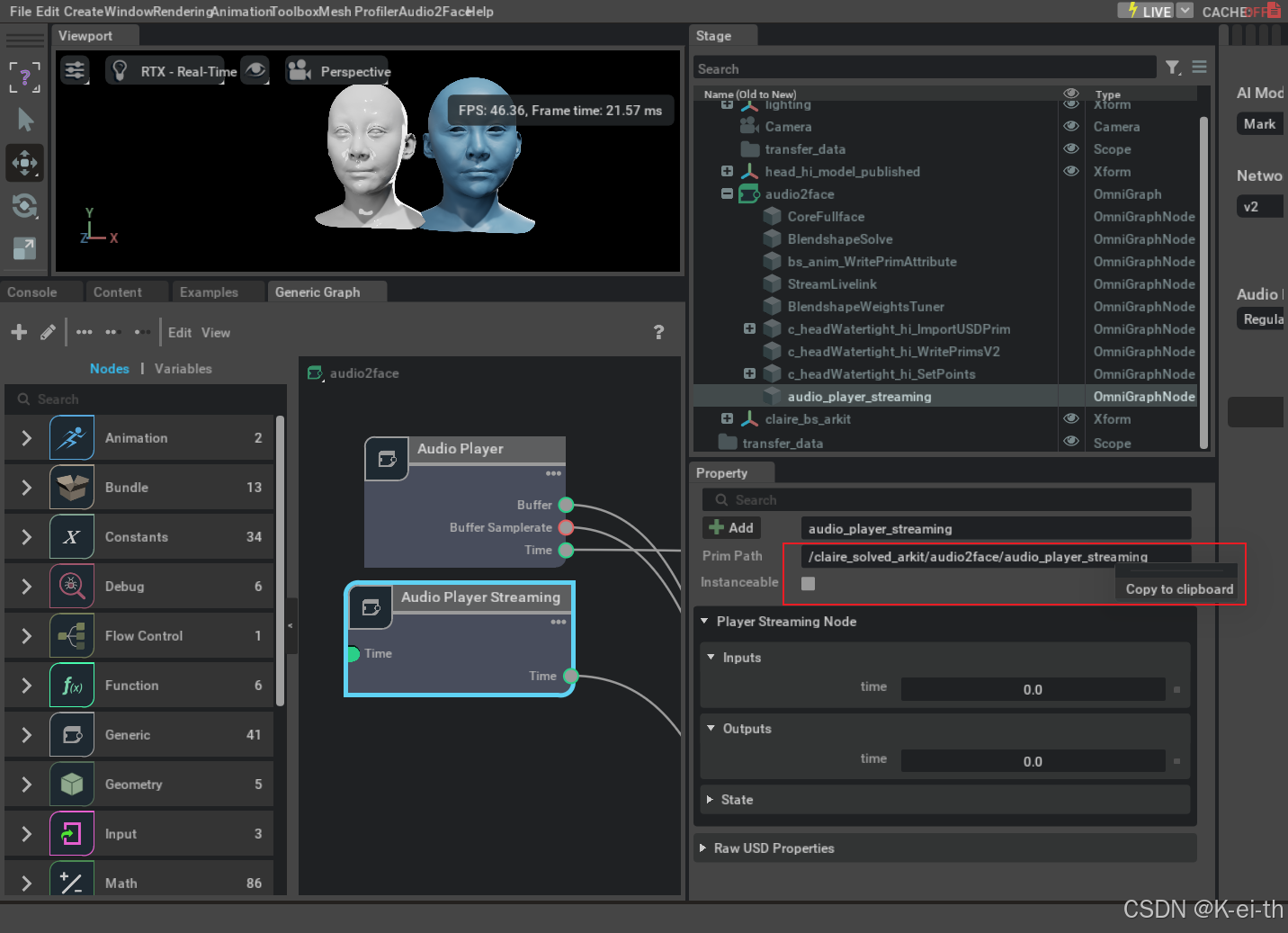
然后咱们还要记住这个路径,后续进行通讯需要用到(●’◡’●)
UE部分
接下来让我们打开UE,把捏好的数字人导入
通过Quixel插件导入我们创建好的数字人到我们的空白关卡中
在插件中添加Audio2face插件,然后重启
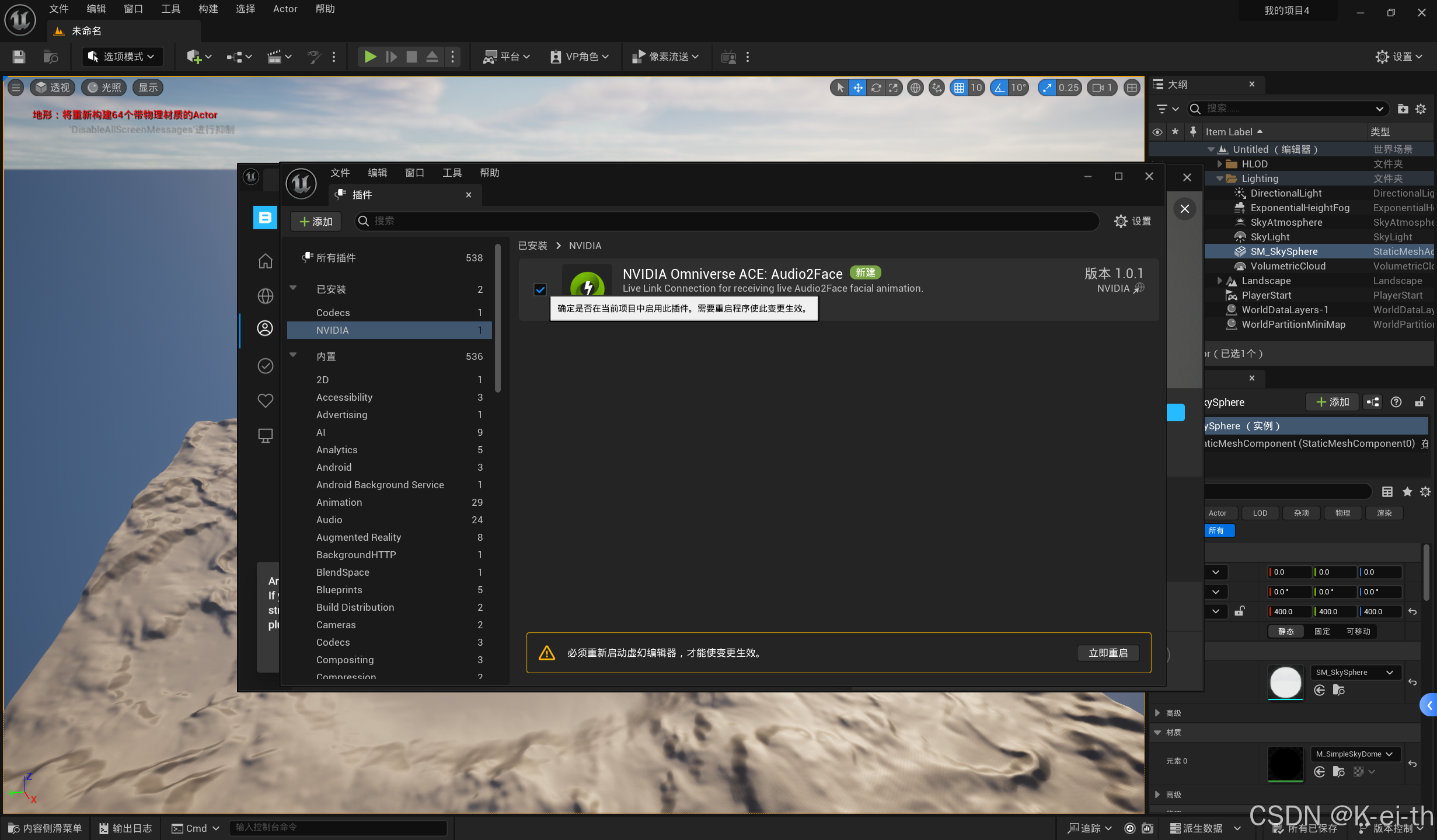
紧接着打开Livelink源
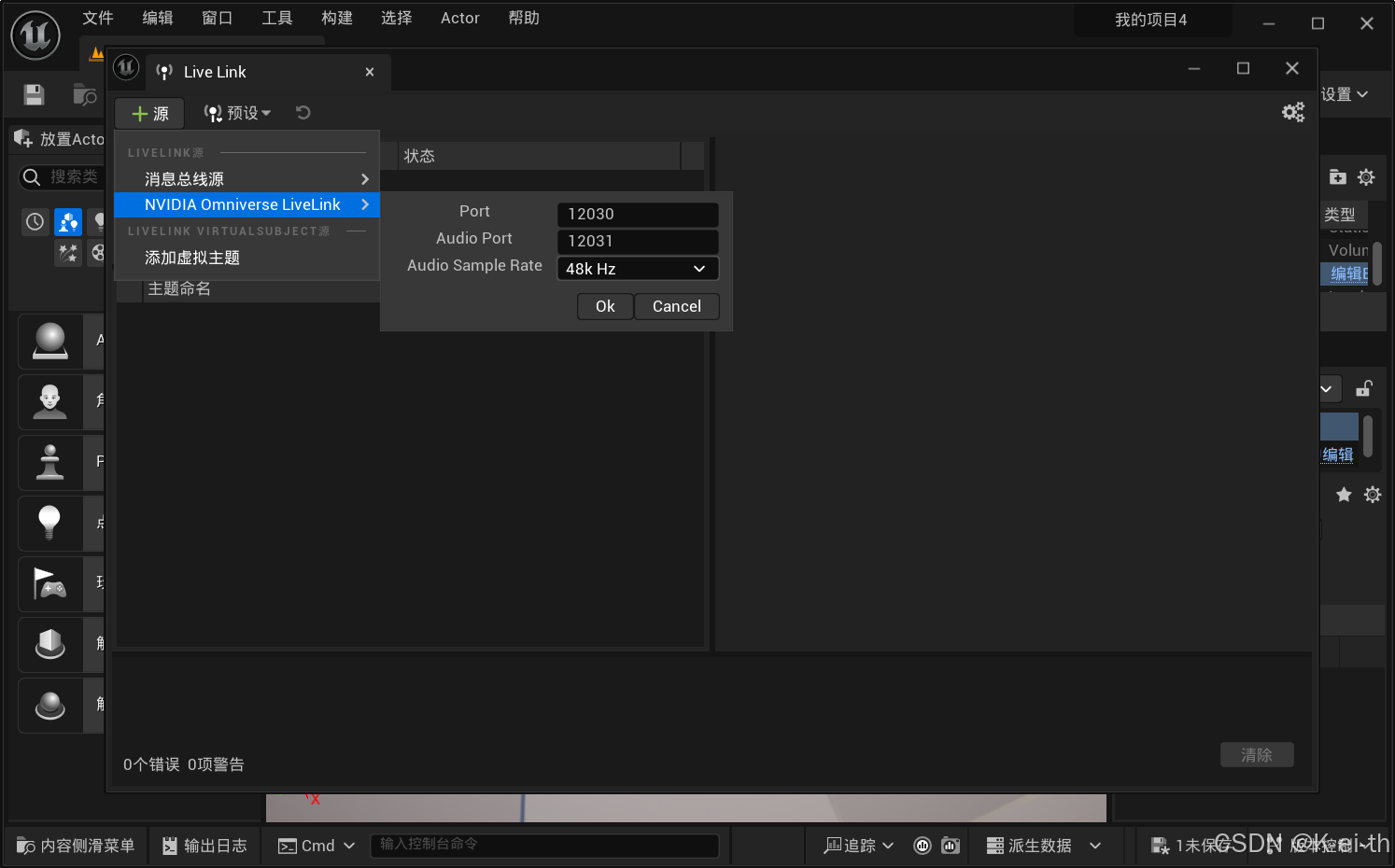
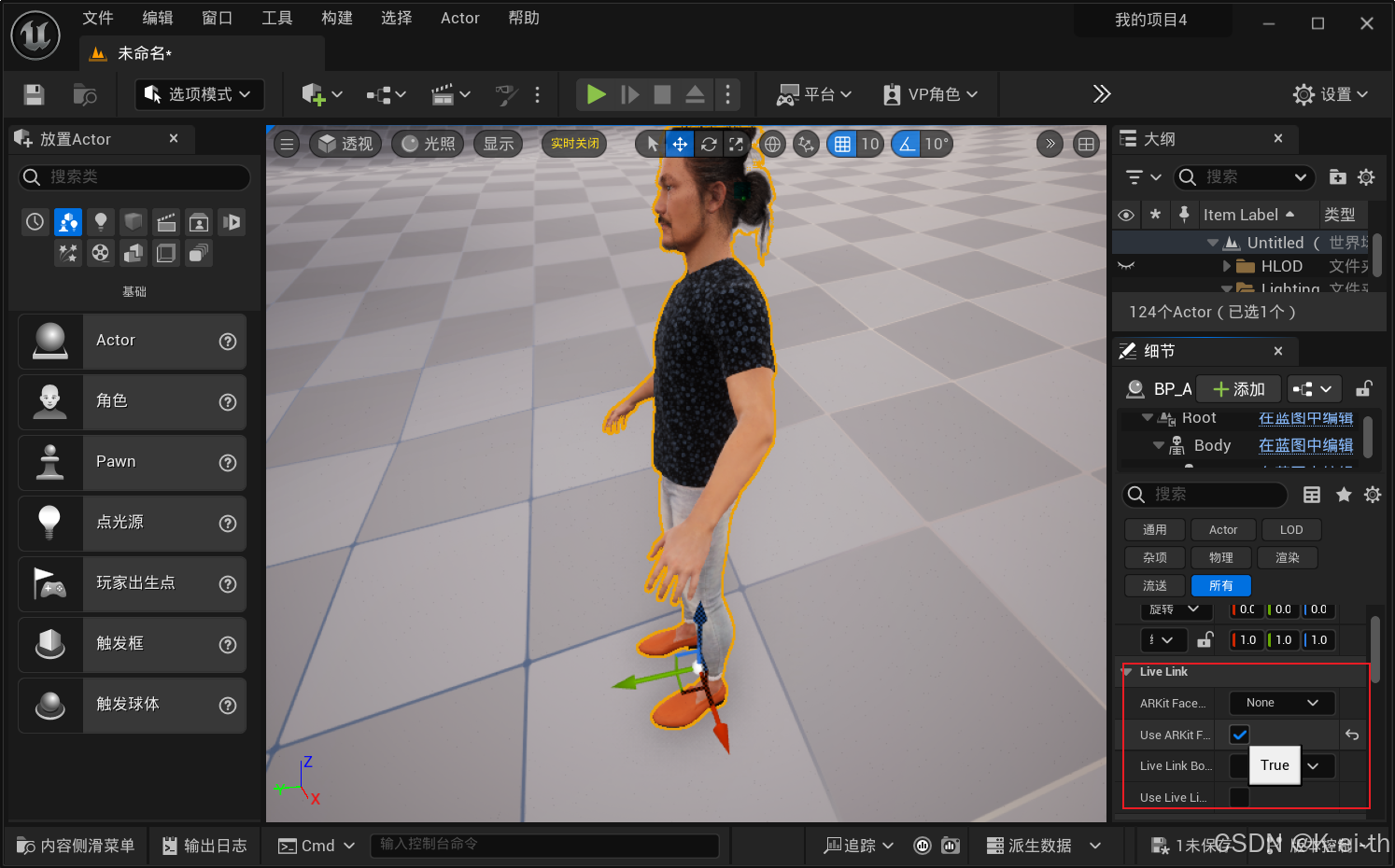
然后在对应我们捏好的数字人实例中找到Live Link,如果配置正确,应该会出现audio2face的选项,然后开启ARKit Face模块,即可实现audio2face和ue中的数字人的串联(✿◕‿◕✿)
代码部分
为了能够实现实时对话,我们需要以下几个模块
- 文本接收器
- LLM分析文本并输出回答
- 回答文本转换为语音模块
- 语音模块和Audio2Face建立流链接
这里是一个简单的demo
import pyttsx3
import subprocess
import os
def text_to_speech(text, output_file="output.wav", rate=200, volume=1.0, voice_id=None):
engine = pyttsx3.init()
# 设置语速
engine.setProperty('rate', rate)
# 设置音量
engine.setProperty('volume', volume)
# 获取当前可用声音列表
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id)
engine.save_to_file(text, output_file)
engine.runAndWait()
def send_audio_to_audio2face(audio_file_path):
"""
通过命令行发送音频文件给数字人模型。
先切换到目标目录,然后执行命令。
参数:
- wav_path: 音频文件的路径,例如 "D:/Postgraduate/研0/人工智能前沿应用/TTS/output.wav"
- instance_name: Audio2Face的实例名称,例如 "D:/Nvidiaomini/pkg/audio2face-2023.2.0/exts/omni.audio2face.player/omni/audio2face/player/scripts/streaming_server/World/audio2face/CoreFullface"
"""
# 设置目标路径
target_directory = "D:/Nvidiaomini/pkg/audio2face-2023.2.0/exts/omni.audio2face.player/omni/audio2face/player/scripts/streaming_server/"
# 切换到目标目录
os.chdir(target_directory)
# 构建命令
command = f"python test_client.py {audio_file_path} /World/audio2face/PlayerStreaming"
# 调用命令行执行
try:
subprocess.run(command, shell=True, check=True)
print("音频文件已成功发送给Audio2Face")
except subprocess.CalledProcessError as e:
print(f"命令执行失败: {e}")
except Exception as e:
print(f"发生错误: {e}")
from openai import OpenAI
if __name__ == "__main__":
# 可根据需要进行参数调整
default_rate = 100 # 默认语速
default_volume = 1.0 # 默认音量
default_voice_id = 0 # 若需选择特定音色,如 voices[0], 则设为0等
client = OpenAI(api_key="输入你自己的API-KEY哦( ´・・)ノ(._.`)", base_url="https://api.deepseek.com/v1")
messages = [{"role": "user", "content": '''你是高欢(496年~547年2月13日),鲜卑名贺六浑,南北朝时期东魏权臣,北齐王朝奠基人。前秦征东参军高泰玄孙,北齐文襄帝高澄之父。(注意:你要和用户对话,每次回复不能超过20字!!!)'''}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(messages[1].content)
while True:
content = input("请输入对话文本(输入“再见”退出):")
messages = [{"role": "user", "content": '''你是高欢(496年~547年2月13日),齐王,谥号献武王,庙号太祖。北齐建立后,追封皇帝,谥号神武,庙号高祖''' + content}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
# 检查是否为退出条件
if content.strip() == "再见":
print("程序已结束,再见!")
break
# 调用语音转换函数并保存为output.wav
audio_file_path = os.path.abspath("output.wav")
text_to_speech(messages[1].content, output_file=audio_file_path, rate=default_rate, volume=default_volume, voice_id=default_voice_id)
print(f"音频文件{messages[1].content}已生成:{audio_file_path}")
# 发送音频文件给数字人模型
send_audio_to_audio2face(audio_file_path)
关于代码中的路径部分,我设置为了绝对路径,采用终端输入输出的方式来操作,请针对你当时安装audio2face的路径来查找这个对应的脚本文件哦┏ (゜ω゜)=☞
结果
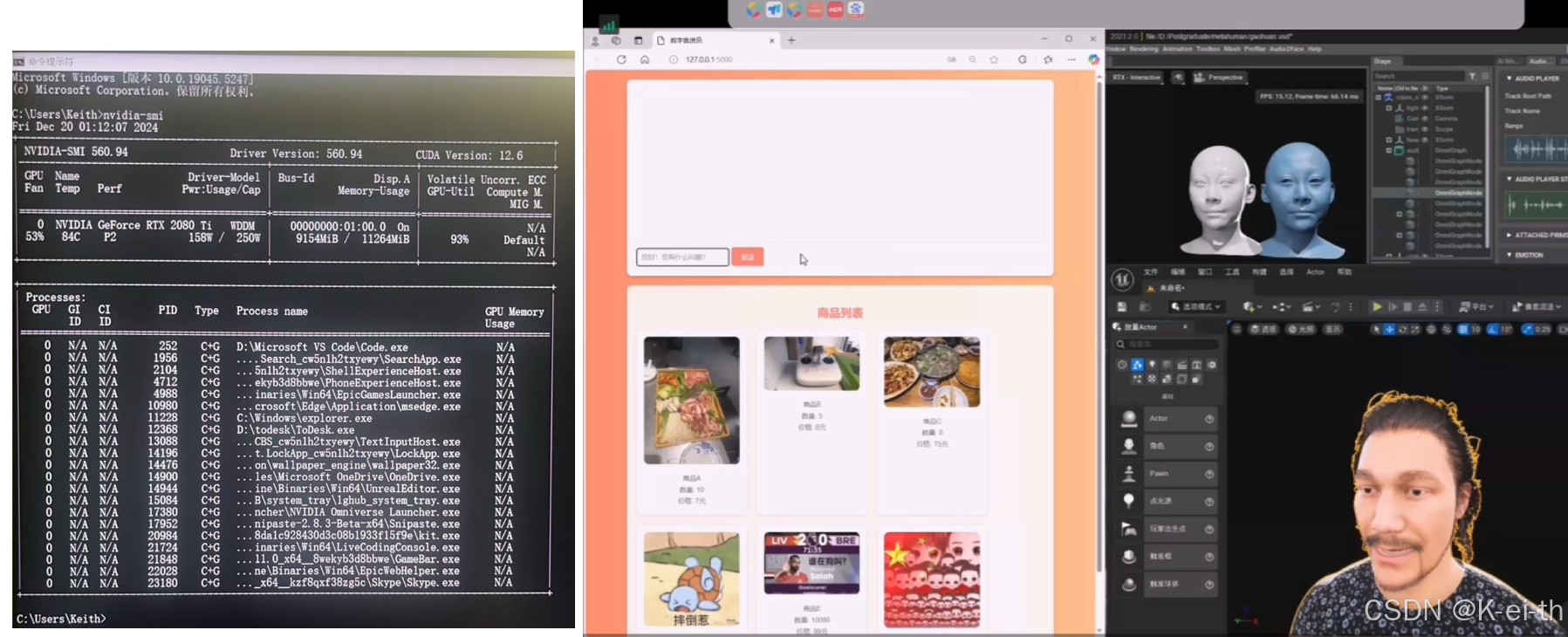
当这些全部配置完成后,我们就可以通过脚本对话,将文本转换为语音,语音输入audio2face输出动作,动作再映射给ue中的数字人,最终的效果如下(✿◕‿◕✿)


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









