




论文下载:
论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)
论文Generative Adversarial Text to Image Synthesis详解
论文DF-GAN: ASimple and Effective Baseline for Text-to-Image Synthesis详解
论文StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks详解
论文HDGAN(Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network)详解
论文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks详解
论文MirrorGAN: Learning Text-to-image Generation by Redescription详解
基于GAN的文生图(DM-GAN:Dynamic MemoryGenerative Adversarial Networks for Text-to-Image Synthesis)
基于监督对比学习的统一图像生成框架(A Framework For Image Synthesis Using Supervised Contrastive Learning)
基于GAN的文生图算法详解(Text to Image Generation with Semantic-Spatial Aware GAN)
基于GAN的文生图算法详解ControlGAN(Controllable Text-to-Image Generation)
StyleGAN-T文生图算法详解(Unlocking the Power of GANs forFast Large-Scale Text-to-Image Synthe)
本文综述了多篇文本生成图像(Text-to-Image)领域的代表性论文,包括GALIP、DF-GAN、StackGAN系列、AttnGAN、MirrorGAN等。重点分析了现有方法的三方面局限性:单描述信息不足、语义鸿沟问题和生成质量受限。针对这些问题,提出了两种改进架构:级联C4Synth采用串行生成器-判别器对逐步优化图像;循环C4Synth通过权重共享和隐状态记忆实现更灵活的多描述融合。两种方法都利用跨文本描述循环一致性来提升生成质量,其中级联模型固定阶段数,而循环模型支持动态描述输入。实验验证了这些方法在解决多描述融合和图像细节生成方面的有效性。
目录

现有方法的局限性
1.单描述信息不足
现有文本到图像生成方法(如GAN-INT-CLS、StackGAN、AttnGAN等)都只使用单个文本描述来生成图像。然而,单个描述存在以下问题: 信息覆盖不全:难以捕捉图像中所有细节和多样性;语义表达有限:无法充分表达复杂场景的多维度信息;细节描述不足:如图1所示,同一张图像可以有多个互补的描述角度 。
2. 语义鸿沟问题
虽然现有方法使用分布式文本表示来编码单词概念,但“一图胜千言”的挑战依然存在: 视觉信息的丰富性难以通过单一文本来完全表达 ;标准数据集(如COCO、Pascal Sentences)虽提供多个描述,但现有方法未能充分利用 。
3. 生成质量受限
基于单一描述的生成方法在复杂场景下表现受限,特别是: 对细微差别的捕捉能力不足 ;生成图像的细节丰富度有限 ;对复杂物体关系的表达能力较弱。
提出的方法

1. 级联C4Synth(Cascaded-C4Synth)
架构特点:串行生成器-判别器对:每个阶段对应一个描述 ;渐进式优化:每个阶段基于前阶段结果和当前描述优化图像 ;固定阶段数:架构阶段数限制了可使用的描述数量。
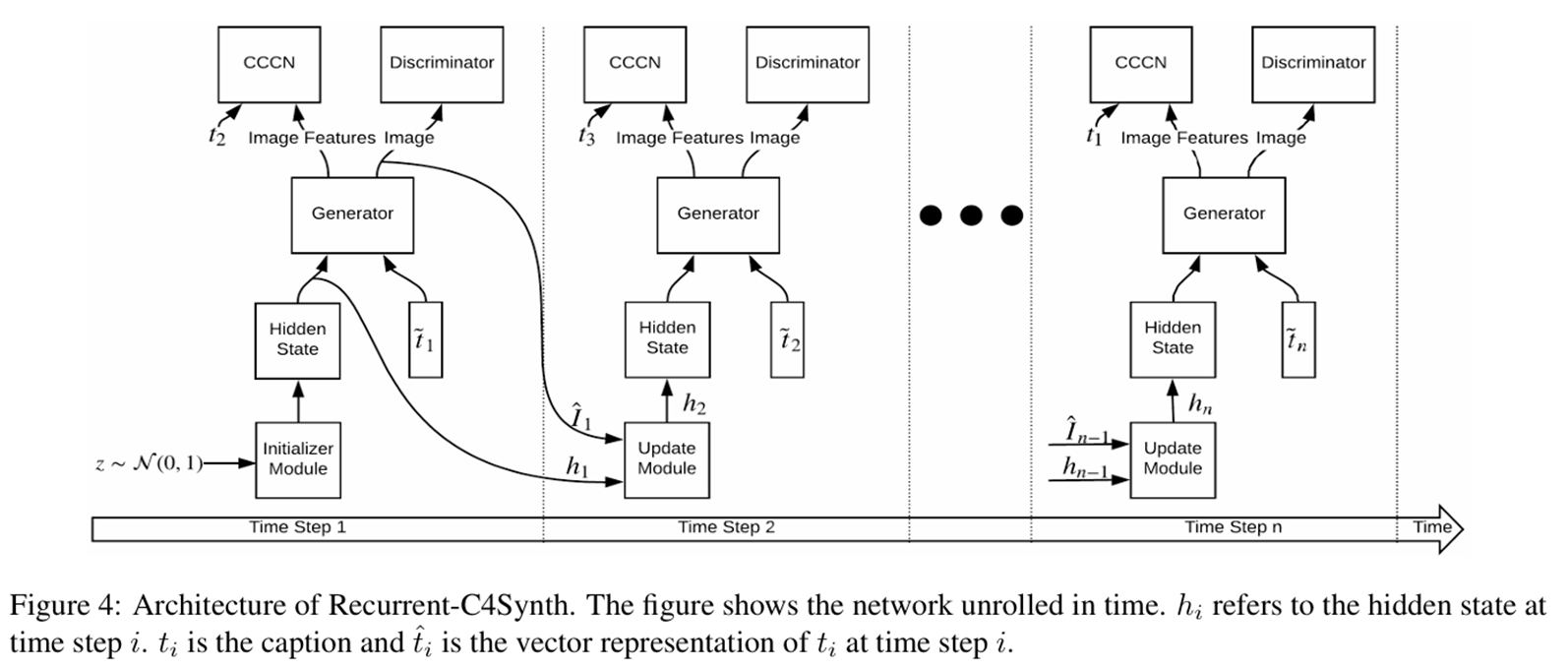
2. 循环C4Synth(Recurrent-C4Synth)
解决级联模型的限制: 描述数量灵活:不受固定阶段数限制 ;权重共享:单一生成器在不同时间步共享参数 ;隐状态记忆:通过隐藏状态积累多描述信息 。 初始化模块:从噪声向量生成初始隐藏状态 ;循环更新:隐藏状态融合前一时间步的图像信息 ;时间展开:通过BPTT进行训练。
具体方法
生成对抗网络

文本嵌入

跨文本描述循环一致性

级联的跨文本描述循环一致性
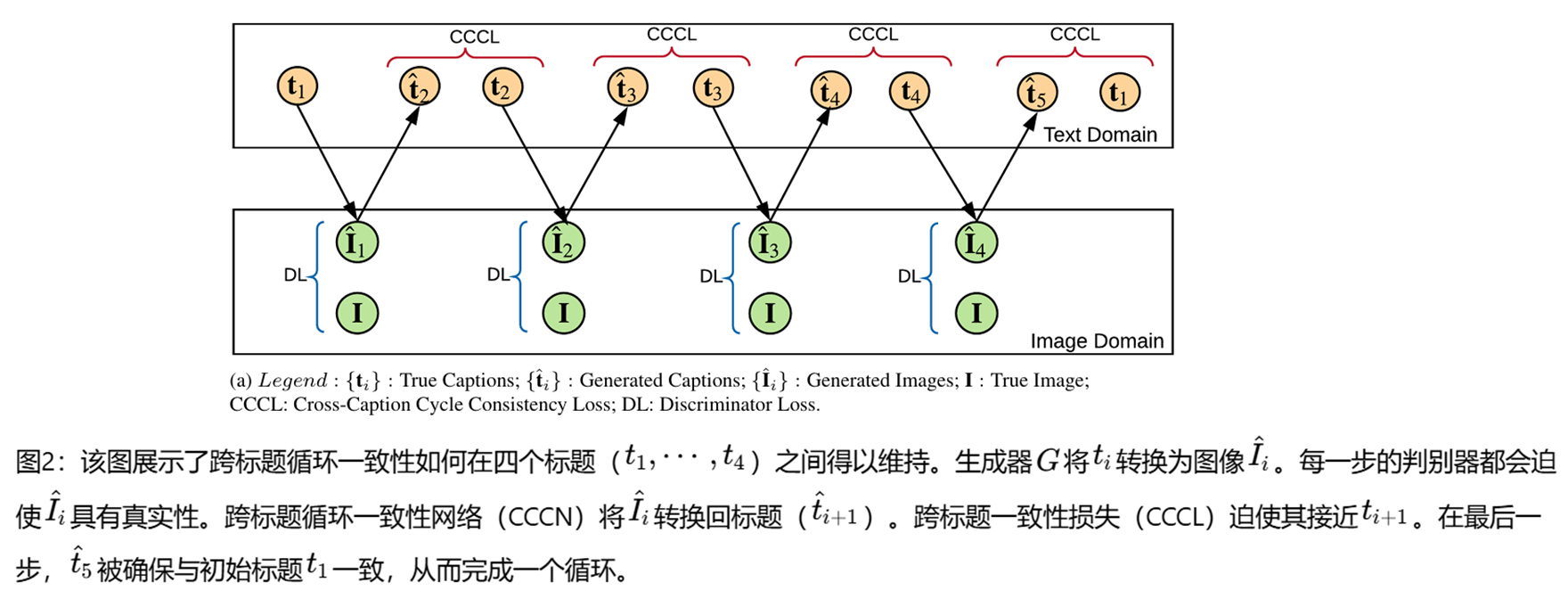
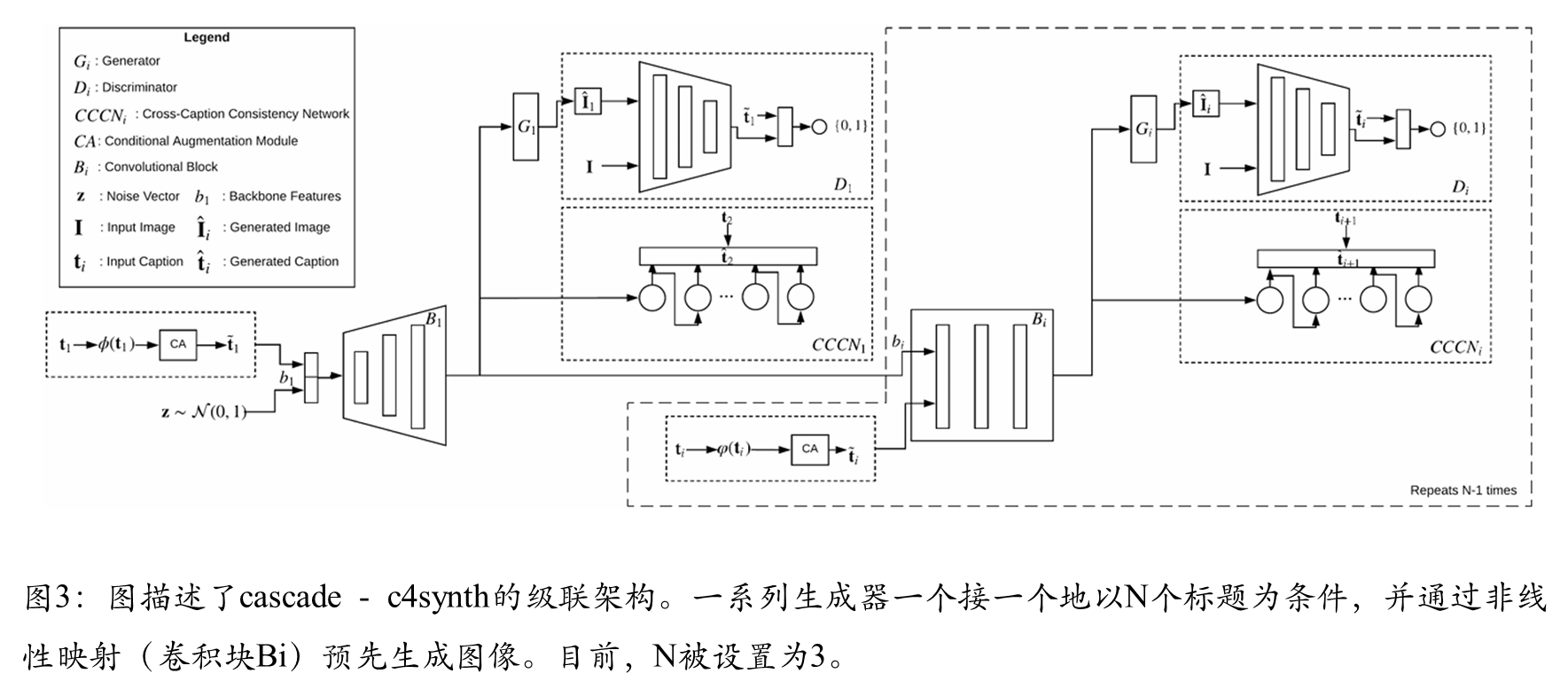
在第一种方法中,将跨文本描述循环一致的图像生成视为一个级联过程,其中一系列生成器依次使用多个文本描述来生成图像。每一步生成的图像是前一阶段生成的图像与当前阶段所提供文本描述的函数。这使得每一阶段能够基于前一阶段生成的中间图像,利用当前阶段看到的新文本描述中的额外概念进行构建。每个阶段分别使用一个判别器和一个CCCN。判别器的任务是判断生成的图像是真实的还是虚假的,而CCCN则负责将图像转换为其对应的文本描述,并检查其与下一个连续文本描述的相似度。
其架构如图3所示。一组卷积块(在图中标记为Bi)构成了网络的主干。每个Bi的第一层接收一个文本描述作为输入。每个生成器(Gi)和CCCN(CCCNi)从每个Bi的最后一层分支出来,同时一个新的Bi会连接到主干上以扩展架构。Bi的数量在设计架构时是固定的,这限制了可用于生成图像的文本描述数量。该架构的主要组成部分将在下文进行解释。
主干模型

生成器

判别器

跨文本描述循环一致性网络

更新隐藏状态

实验结果




















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









