



0.安装50系列显卡驱动
参考:在ubuntu下为Nvidia 50系安装显卡驱动 - 青雨染蓑衣的个人小站
截止五月:
前段时间,570.144这版驱动已经进入了22.04及以后的版本,20.04的ppa仓库也已添加,这版已支持50系GPU,与之前的安装方式相比,你只需要在nvidia-driver-570后面加个open,即:
sudo apt install nvidia-driver-570-open1.安装50系的卡驱动,cuda版本正常安装到12.8。
运行代码nvidia-smi后能看见如下界面表示驱动正常:
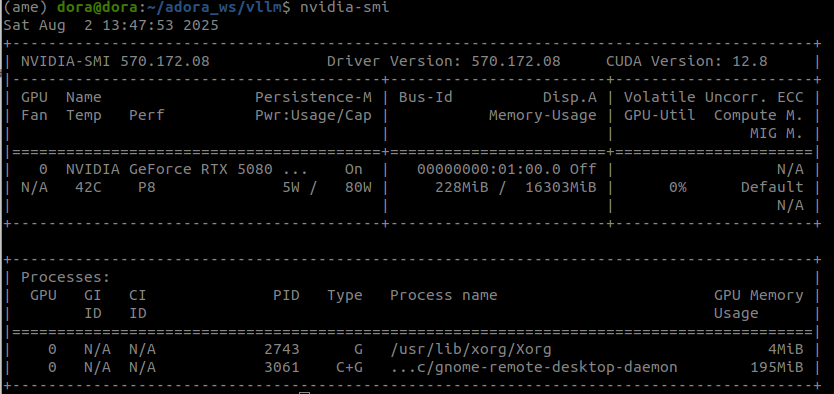
2.安装conda环境
从官网下载Anaconda3-2024.10-1-Linux-x86_64.sh然后直接执行sudo bash Anaconda3-2024.10-1-Linux-x86_64.sh,该类教程网上很多,随便搜一个,这里不多说明。
3.创建虚拟环境
可以直接conda create一个python3.12的环境,也可以列一个环境配置文件在创建,参考博文:
关于RTX50系列显卡(5080/5090/5090D)CUDA12.8版本部署vllm服务相关步骤整理_cuda 12.8-优快云博客
内容如下:在你的数据存储路径下,执行命令
sudo touch environment_linux.yml创建一个环境的配置文件。执行
sudo nano environment_linux.yml编辑,输入以下内容:
channels:
- conda-forge
- pytorch
- nvidia
- defaults
dependencies:
- python=3.12
- anaconda
- pip
保存后执行创建环境的命令,-n参数制定环境名为vllm
conda env create -f environment_linux.yml -n vllm4.安装pytorch
切换至创建好的vllm虚拟环境内,去torch官网根据自己的环境复制下载命令
torch官网:Get Started
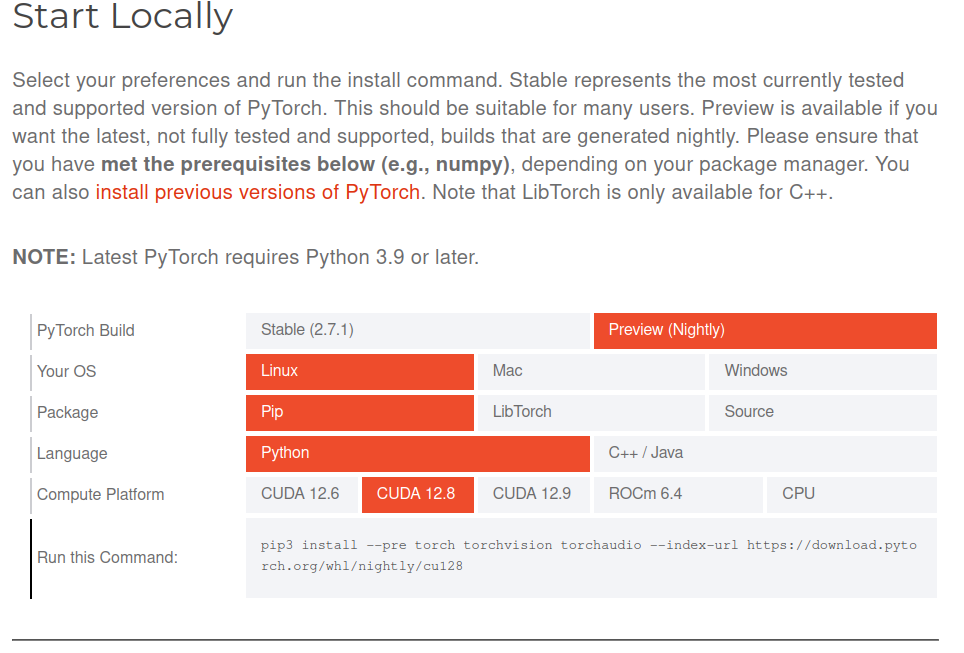
5.测试环境
执行python后进入到python编辑窗口,依次输入以下命令并查看输出结果是否一致:
In [1]: import torch
In [2]: torch.__version__
Out[2]: '2.7.0.dev20250312+cu128'
In [3]: print(torch.cuda.is_available())
True
In [4]: device = "cuda"
In [5]: x = torch.ones(5, 5).to(device)
In [6]: y = torch.randn(5, 5).to(device)
In [7]: z = x + y
In [8]: print(z)
tensor([[ 2.7746, 0.7957, 2.3443, 0.8475, 0.4464],
[ 0.3883, -0.2033, 3.1749, 1.0566, 1.6964],
[ 0.6829, 0.0952, 1.3061, 1.4194, 1.6353],
[ 1.4389, 0.7820, -0.0463, 2.0666, 1.4440],
[ 2.5913, 0.6384, 2.3288, 1.3102, 2.2450]], device='cuda:0')
6.克隆编译
git clone https://github.com/vllm-project/vllm.git
cd vllm
python use_existing_torch.py
pip install -r requirements/build.txt
pip install setuptools_scm
修改参与构建项目的最大线程数
export MAX_JOBS=4
这里很重要,一定要根据自己主机的性能设置,我的环境如开头所说,在内存不够的情况下,设置线程数8或4甚至2都会卡死,所以我这里建议内存不够的朋友设置一下虚拟内存,虽然会慢一些,但是起码不会内存爆满导致死机,吃个饭回来的时间其实也就好了,不会慢多久。
如何设置虚拟内存参考这篇博文:
python setup.py install接下来最好开个htop看着,如果确实不会爆内存死机,再去喝杯咖啡小憩一下。如果内存马上要红,就立马CtrlC终止编译,增大虚拟内存或者减少最大线程数。
构建完了可以试试whereis vllm看看有没有找到
![]()
至此,vllm编译完成,下面我将尝试本地部署RoboBrain2.0-7B模型,并使用RoboOS和机器人本体的RoboSkill大小脑架构来控制我们的人形机器人实现自主导航和抓取任务。
敬请期待!!


















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









