



这是一个综合性的金融数据分析平台,集成了股票市场数据展示、技术指标分析、机器学习预测、量化投资策略回测和AI智能分析等功能。其核心思路是构建一个从原始数据到投资洞察的完整流水线,整个项目的代码编写遵循着“数据输入 → 数据处理 → 模型分析 → 结果展示”的逻辑链条。
一、项目架构设计
1.1 分析流程
整个程序从数据加载开始,代码采用了分年度读取再合并的策略,这是因为实际金融数据往往按年份更新,这样做既方便管理增量数据,也避免了单文件过大导致的内存问题。读取后立即将交易日期统一转换为整数格式,这是一个关键预处理步骤,为后续基于日期的快速筛选和区间计算奠定了基础。
1.2 技术栈选择
-
前端/交互:Streamlit(简化Web界面开发)
-
数据处理:Pandas、NumPy
-
可视化:Plotly(交互式图表)
-
机器学习:Scikit-learn
-
数据源:CSV/Excel本地文件
二、核心模块代码详解
2.1 数据加载模块
数据加载模块是整个系统平台的起点。这里采用了分年度读取的策略,将2023、2024、2025三年的复权交易数据分别读取后再使用pd.concat合并。这种设计的考虑在于实际金融数据通常是按年份更新的,分开存储便于增量更新和维护。读取后立即执行类型转换,将交易日期统一转为整数格式(YYYYMMDD),这种预处理为后续的日期区间筛选提供了便利,整数比较比字符串或日期对象比较更高效。同时,通过类型转换也能尽早发现数据格式问题,避免在后续计算中出错。
# 读取交易数据 - 采用分年度读取再合并的策略
t2023 = pd.read_csv('复权交易数据2023.csv')
t2024 = pd.read_csv('复权交易数据2024.csv')
t2025 = pd.read_csv('复权交易数据2025.csv')
trade_data = pd.concat([t2023, t2024, t2025], axis=0)
# 数据类型标准化
trade_data['trade_date'] = trade_data['trade_date'].astype(int)2.2 龙虎榜计算模块
龙虎榜计算函数的设计体现了对金融数据特殊性的理解。这个函数不仅仅计算涨跌幅,更重要的是处理实际数据中的各种异常情况。函数内部实现了两种独立的计算方法:
一种是基于首尾收盘价的简单计算,另一种是基于每日涨跌幅的复利累乘。
这两种方法理论上应该一致,但由于数据缺失、停牌等因素,实际结果常有差异。代码在处理这个差异时采用了一个巧妙的策略:如果两种方法结果相近,采用更精确的复利计算法;如果差异较大,则取相对保守的值。
这种双重验证机制大大提高了结果的可靠性。此外,函数还包含了严格的数据清洗步骤,过滤价格异常、涨跌幅过大等不合理数据,确保输出的龙虎榜名单具有实际参考价值。
def calculate_dragon_tiger(start_date_int, end_date_int, trade_data, stock_info_path):
"""
核心设计思想:
1. 多方法验证:使用价格直接计算和日涨跌幅累乘两种方法
2. 异常过滤:过滤价格异常、涨跌幅过大的数据
3. 结果融合:比较两种方法结果,取合理值
"""
# 方法A:使用首尾收盘价直接计算
first_close = group.iloc[0]["close"]
last_close = group.iloc[-1]["close"]
pct_from_price = (last_close - first_close) / first_close * 100
# 方法B:使用日涨跌幅累乘计算
if 'pct_chg' in group.columns:
cumulative = 1.0
for pct in valid_pct:
if -20 <= pct <= 20: # 严格过滤异常值
cumulative *= (1 + pct/100)
pct_from_daily = (cumulative - 1) * 100
# 结果融合策略
if pct_from_daily is not None:
if abs(pct_from_price - pct_from_daily) < 50: # 差异小于50%
final_pct = pct_from_daily
else:
# 取较小值作为保守估计
final_pct = min(pct_from_price, pct_from_daily)
else:
final_pct = pct_from_price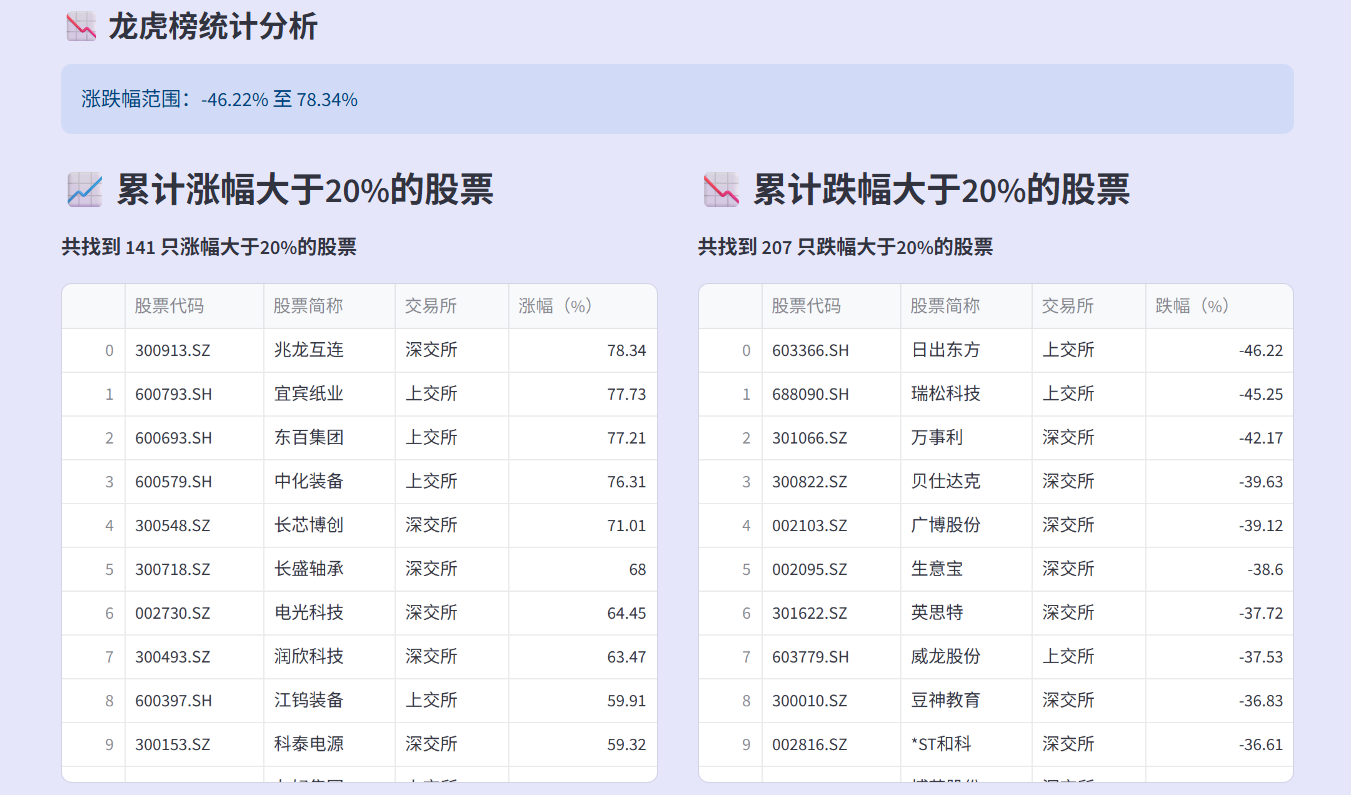
2.3 技术指标计算模块
技术指标计算部分将经典的金融分析理论转化为可执行的代码。移动平均线通过滚动窗口计算不同周期的均值,反映价格的中长期趋势。
MACD指标的计算则需要先计算指数移动平均,然后求差值和信号线,最后得出MACD柱。这里特别注意了计算顺序的依赖关系,确保每个步骤都基于前一步的正确结果。
KDJ和RSI的计算则关注价格的相对位置和动量变化。整个计算过程中,代码考虑了边界情况,比如数据量不足时如何避免计算错误,如何正确处理NaN值等。最终生成的技术指标不仅用于可视化展示,更重要的是作为机器学习模型的特征输入。
def calculate_technical_indicators(df):
"""技术指标计算工厂函数"""
# 1. MA移动平均线 - 基础趋势指标
df['MA5'] = df['close'].rolling(window=5).mean()
df['MA10'] = df['close'].rolling(window=10).mean()
df['MA20'] = df['close'].rolling(window=20).mean()
# 2. MACD - 趋势动量指标
df['EMA12'] = df['close'].ewm(span=12, adjust=False).mean()
df['EMA26'] = df['close'].ewm(span=26, adjust=False).mean()
df['DIF'] = df['EMA12'] - df['EMA26']
df['DEA'] = df['DIF'].ewm(span=9, adjust=False).mean()
df['MACD'] = (df['DIF'] - df['DEA']) * 2
# 3. KDJ - 超买超卖指标
low_min = df['low'].rolling(window=9).min()
high_max = df['high'].rolling(window=9).max()
df['RSV'] = (df['close'] - low_min) / (high_max - low_min) * 100
df['K'] = df['RSV'].ewm(com=2).mean()
df['D'] = df['K'].ewm(com=2).mean()
df['J'] = 3 * df['K'] - 2 * df['D']
# 4. RSI - 相对强弱指标
delta = df['close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
df['RSI'] = 100 - (100 / (1 + rs))
# 5. 趋势标签 - 用于机器学习
df['trend'] = (df['close'].diff() > 0).astype(int)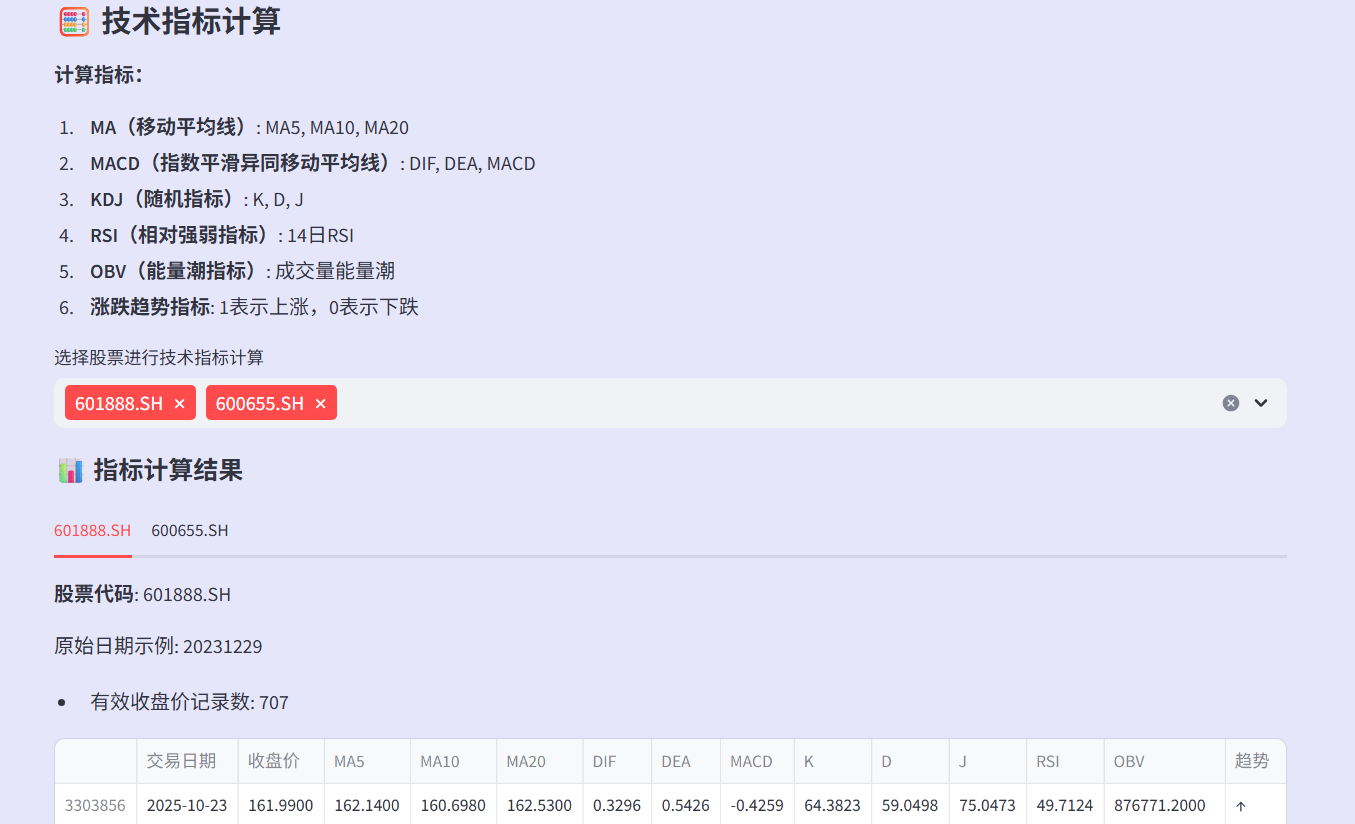
2.4 机器学习模型模块
训练函数接收相同的输入接口,但内部可以根据参数选择不同的算法。逻辑回归模型简单快速,适合作为基线模型;随机森林模型能够处理非线性关系,且对特征工程要求较低;神经网络模型具有强大的表征能力,但需要更多的数据和调参。
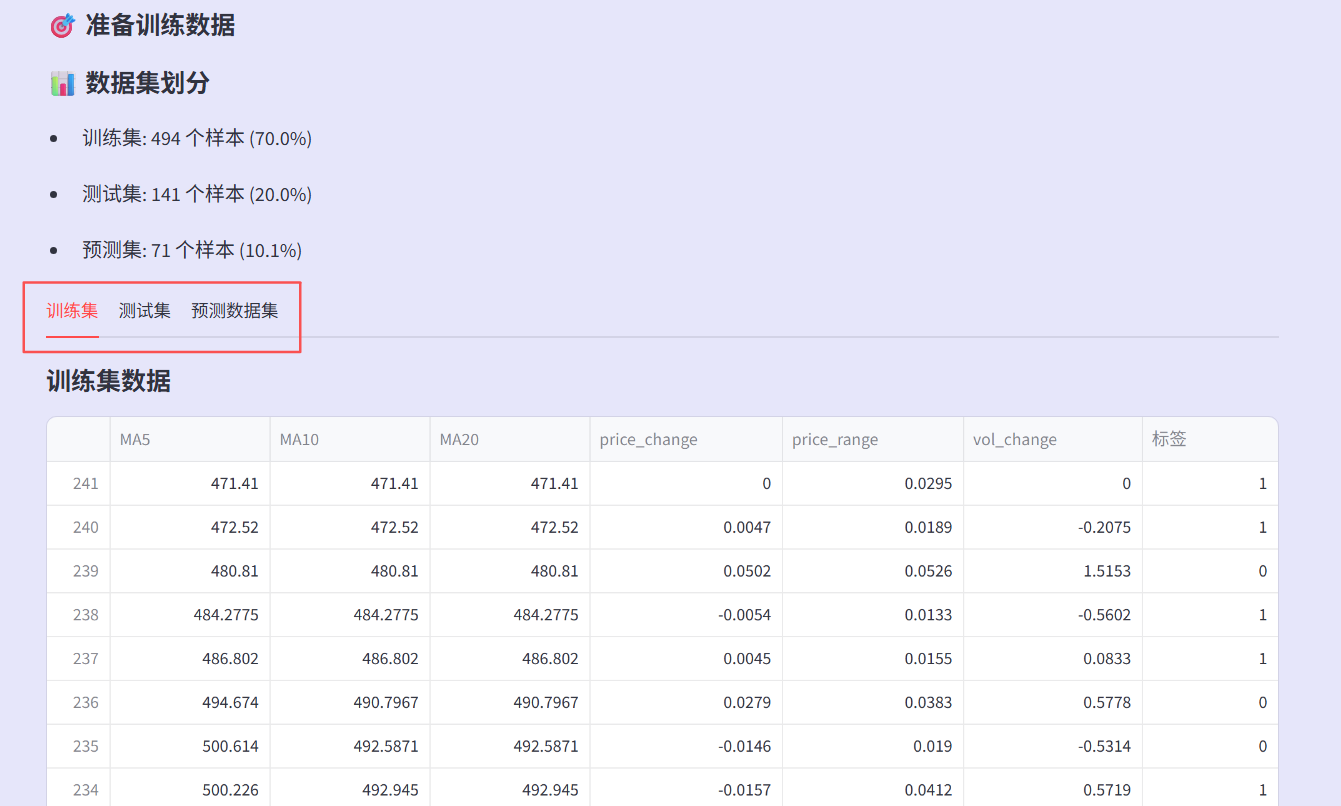
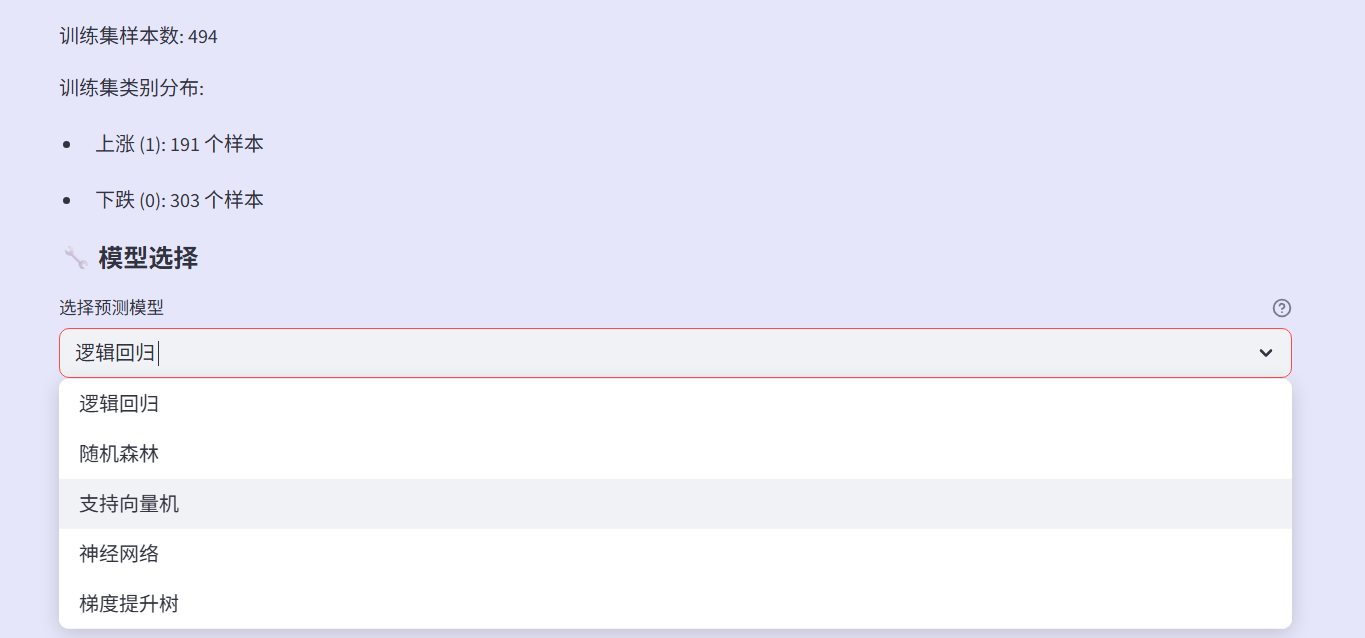
代码为每种模型都设置了合理的默认参数,并统一了训练流程:数据标准化、模型训练、性能评估。在数据划分策略这一部分,70%的训练集用于学习模式,20%的测试集用于验证泛化能力,10%的预测集模拟真实应用场景。这种划分方式更贴近实际投资中的时间序列特性。
def train_prediction_model(X, y, model_type='逻辑回归'):
"""
模型训练的统一接口
支持多种模型,便于对比和选择
"""
# 数据集划分策略:70%训练,20%测试,10%预测
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.3, random_state=42
)
X_test, X_pred, y_test, y_pred = train_test_split(
X_temp, y_temp, test_size=1/3, random_state=42
)
# 模型选择器
model_dict = {
'逻辑回归': LogisticRegression(random_state=42, max_iter=1000),
'随机森林': RandomForestClassifier(n_estimators=100, random_state=42),
'支持向量机': SVC(random_state=42, probability=True),
'神经网络': MLPClassifier(hidden_layer_sizes=(100, 50), random_state=42, max_iter=1000),
'梯度提升树': GradientBoostingClassifier(random_state=42)
}
model = model_dict.get(model_type, model_dict['逻辑回归'])
# 标准化处理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练和评估
model.fit(X_train_scaled, y_train)
y_pred_test = model.predict(X_test_scaled)
test_acc = accuracy_score(y_test, y_pred_test)
return {
'model': model,
'scaler': scaler,
'test_acc': test_acc,
# ... 返回训练过程的所有关键数据
}
2.5 综合评价模块
综合评价函数的实现展示了如何将多维度财务信息压缩为单一得分。面对一家公司的多个财务指标,直接比较是困难的。函数首先对原始数据进行清洗,剔除负值和缺失值,因为某些财务比率为负值可能表示公司经营异常,不适合参与正常的比较分析。
接着进行标准化处理,消除不同指标的量纲差异。然后通过主成分分析提取主要信息,这里设置了保留95%信息量的阈值,在降维和信息保留之间取得平衡。最后根据各主成分的方差贡献率进行加权求和,得到每个公司的综合得分。这个得分反映了公司在多个财务维度上的整体表现,为股票排序提供了量化依据。
def Fr(data, year):
"""
基于主成分分析的综合评价函数
设计思路:多财务指标降维 → 综合得分排序
"""
# 1. 数据清洗
data_x = tdata.iloc[:, 1:-1] # 提取指标列
data_x = data_x[data_x > 0] # 过滤负值
data_x = data_x.dropna() # 删除空值
# 2. 标准化 - 消除量纲影响
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 主成分分析 - 提取主要信息
pca = PCA(n_components=0.95) # 保留95%信息
Y = pca.fit_transform(X_scaled)
gxl = pca.explained_variance_ratio_ # 各成分解释度
# 4. 综合得分计算
F = (Y * gxl).sum(axis=1) # 加权求和
return pd.DataFrame({
'股票代码': data_x['股票代码'].values,
'综合得分': F,
'股票简称': stock_names # 通过合并获取
})2.6 收益率计算模块
收益率计算模块需要解决数据匹配的难题。在实际的金融数据系统中,同一个股票可能在不同数据源中有不同的代码格式。函数设计了一个渐进式的匹配策略:
首先尝试精确匹配,如果失败则尝试匹配代码的数字部分,如果还失败则尝试添加常见的交易所后缀。
这种多层次匹配大大提高了数据查找的成功率。在计算收益率时,代码仔细检查了数据的有效性:确保有足够的交易日数据,确保价格数据没有缺失或为零,确保时间区间在数据范围内。这些检查看似繁琐,但对于保证计算结果的正确性至关重要。
def Tr(rdata, rank, date1, date2, trade_data):
"""
收益率计算核心函数
设计特点:容错处理 + 多格式支持
"""
# 1. 数据格式统一化(关键步骤)
A = trade_data.copy()
A['trade_date'] = A['trade_date'].astype(str).str.strip() # 转字符串去空格
A['ts_code'] = A['ts_code'].astype(str).str.strip().str.upper() # 统一大写
# 2. 股票代码多格式匹配策略
base_code = str(code).strip().upper()
search_codes = []
if '.' in base_code: # 带后缀的代码
search_codes.append(base_code) # 原格式
search_codes.append(base_code.split('.')[0]) # 纯数字格式
else: # 纯数字代码
search_codes.append(base_code)
search_codes.extend([f"{base_code}.SH", f"{base_code}.SZ"]) # 尝试添加后缀
# 3. 模糊查找
for search_code in search_codes:
temp_data = A[
(A['ts_code'].str.contains(search_code.split('.')[0], na=False)) &
(A['trade_date'] >= date1_str) &
(A['trade_date'] <= date2_str)
]
if not temp_data.empty:
stk_data = temp_data
break
# 4. 收益率计算
if stk_data is not None and len(stk_data) >= 2:
p1 = stk_data['close'].iloc[0]
p2 = stk_data['close'].iloc[-1]
ri = (p2 - p1) / p1 if p1 > 0 else 02.7 Streamlit界面设计
Streamlit界面的构建采用了分层组织的思想。侧边栏作为应用的总控台,让用户可以在市场总览和各个行业之间自由切换。主界面根据选择动态加载不同的内容模块。当用户选择市场总览时,界面会展示大盘指数走势和龙虎榜统计;
当选择具体行业时,则会展示该行业的指数走势、成分股表现、财务数据等详细信息。界面设计上充分利用了Streamlit的布局组件,通过列、标签页、折叠面板等方式组织复杂信息,使界面既内容丰富又不显得杂乱。每个图表都配备了交互功能,用户可以通过悬停查看详细数值,通过缩放调整观察范围。
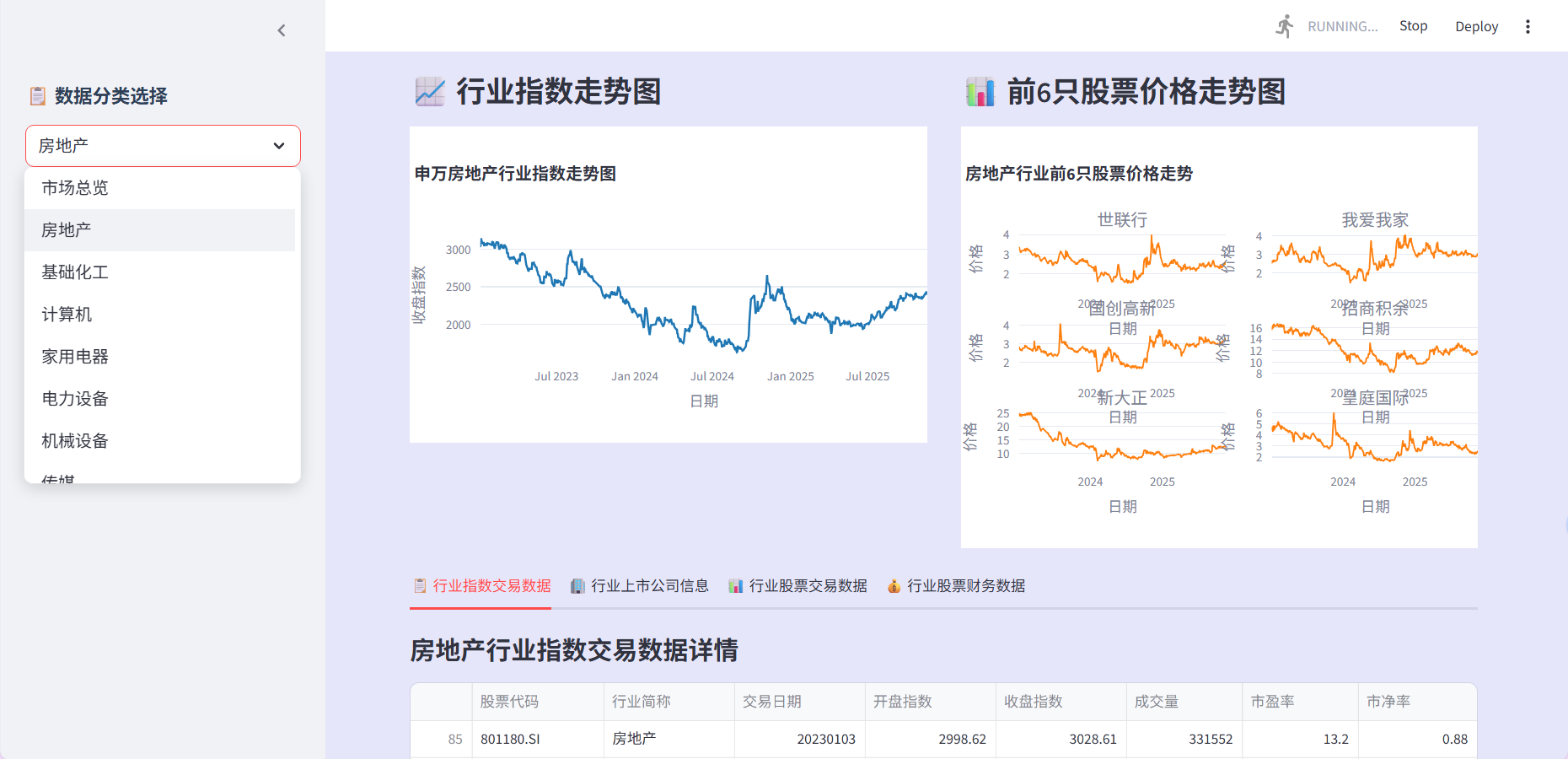
def st_fig():
"""主界面函数 - 采用标签页组织复杂功能"""
# 1. 页面配置
st.set_page_config(
page_title="金融数据挖掘及其应用综合实训",
layout='wide',
initial_sidebar_state="expanded"
)
# 2. 自定义CSS - 美化界面
st.markdown("""
<style>
.main { padding-top: 1rem; }
.stApp { background-color: #E6E6FA; }
</style>
""", unsafe_allow_html=True)
# 3. 侧边栏 - 导航控制
with st.sidebar:
nm = st.selectbox(
label="请选择查看的分类",
options=['市场总览'] + industry_list,
index=0
)
# 4. 主内容区 - 标签页组织
if nm == '市场总览':
t1, t2 = st.tabs(["📈 主要市场指数行情", "📊 行业统计分析"])
with t1:
# 时间选择器
col1, col2 = st.columns(2)
with col1:
start_date = st.date_input("开始日期", value=date(2024, 12, 1))
with col2:
end_date = st.date_input("结束日期",
value=start_date + timedelta(days=30))
# 可视化组件
plot_stock_index_charts_actual(start_date_int, end_date_int, trade_data)
else: # 行业分析页面
tab1, tab2, tab3, tab4 = st.tabs([
"📋 行业指数交易数据",
"🏢 行业上市公司信息",
"📊 行业股票交易数据",
"💰 行业股票财务数据"
])2.8 量化策略回测模块
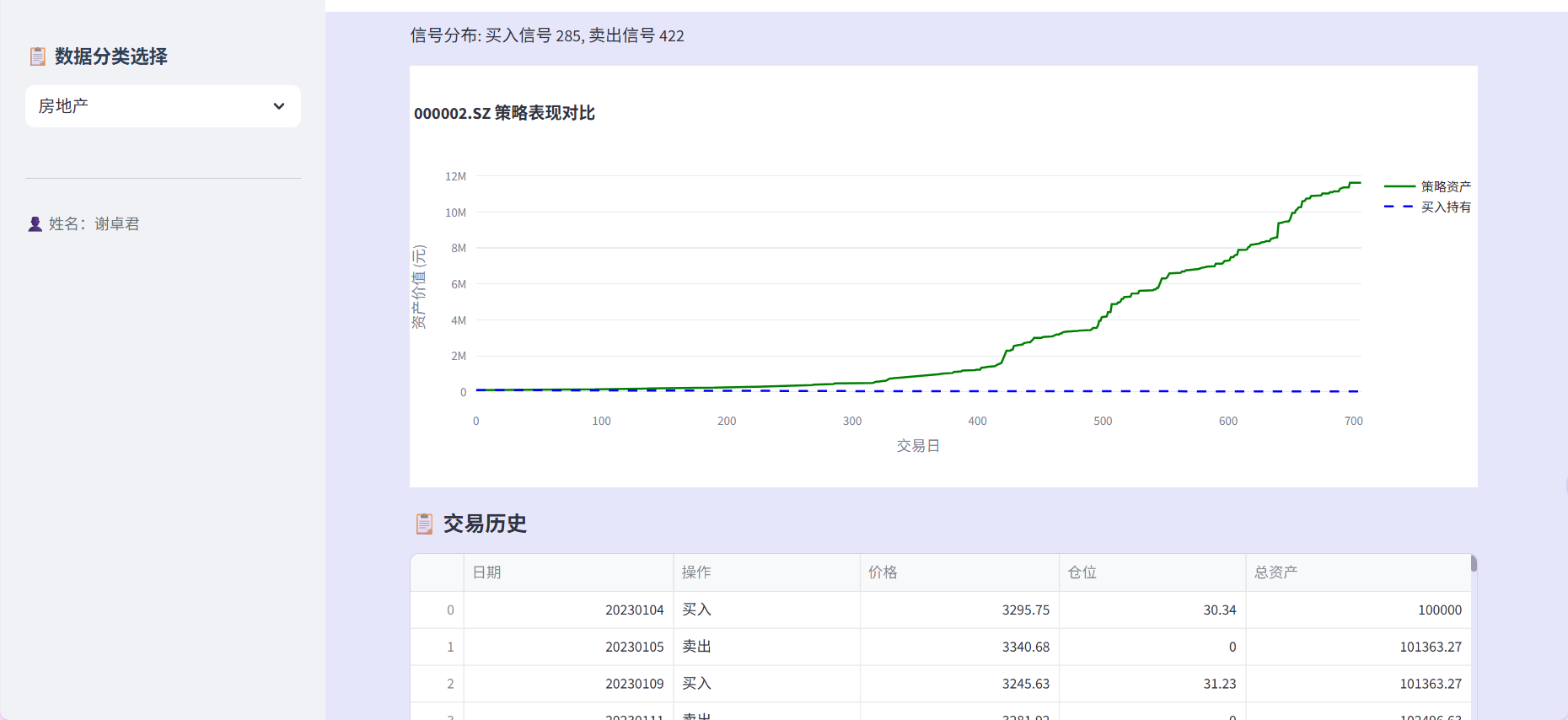
量化策略回测部分将模型预测转化为具体的投资操作。代码模拟了一个简单的全仓进出策略:
当模型预测上涨时全仓买入,预测下跌时全仓卖出。
虽然这个策略在实际交易中可能过于简单,但它提供了一个清晰的框架来验证模型预测的有效性。回测过程中记录了每次交易的日期、价格、仓位变化和资产总值,这些详细记录不仅用于计算最终收益率,也为分析策略表现提供了数据基础。通过对比策略收益率和简单的买入持有收益率,可以直观地评估模型增加的价值。
# 策略回测核心逻辑
def backtest_strategy(prices, signals, initial_capital=100000):
"""
量化策略回测引擎
逻辑:全仓进出,基于预测信号交易
"""
capital = initial_capital
positions = 0
trade_history = []
portfolio_values = []
for i in range(len(prices)):
current_price = prices[i]
# 记录当前资产
current_value = capital + (positions * current_price)
portfolio_values.append(current_value)
# 执行交易(从第二天开始)
if i > 0:
signal = signals[i]
if signal == 1 and positions == 0 and capital > 0:
# 买入信号:全仓买入
positions = capital / current_price
capital = 0
trade_history.append({'操作': '买入', '价格': current_price})
elif signal == 0 and positions > 0:
# 卖出信号:全仓卖出
capital = positions * current_price
positions = 0
trade_history.append({'操作': '卖出', '价格': current_price})
# 计算绩效指标
final_value = capital + (positions * prices[-1])
total_return = (final_value - initial_capital) / initial_capital
return {
'total_return': total_return,
'trade_history': trade_history,
'portfolio_values': portfolio_values
}
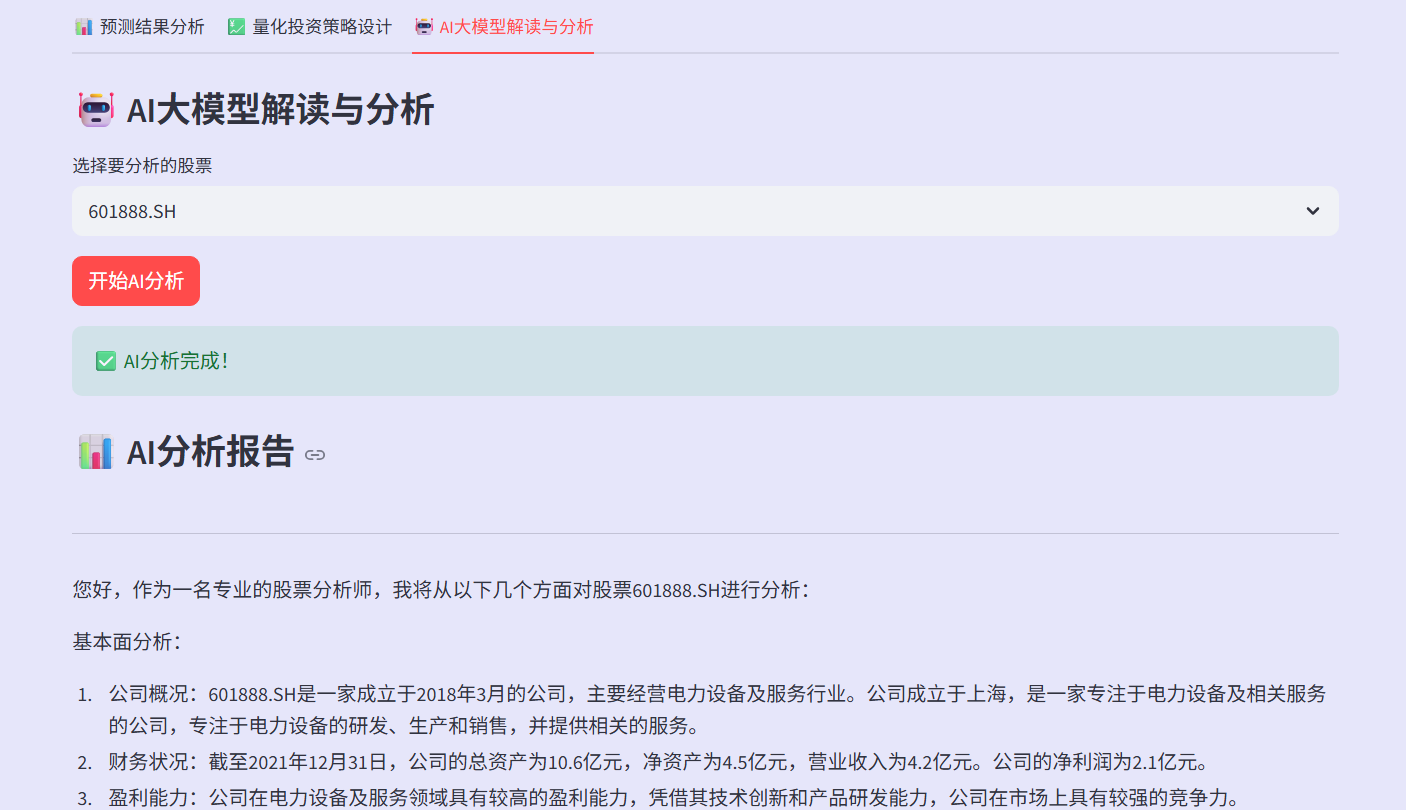
2.9 AI集成模块
AI集成模块展示了如何将大语言模型与传统量化分析相结合。代码没有简单地将原始数据直接发送给AI,而是首先对股票信息进行结构化整理,然后构建专业的提示词,明确要求AI从基本面、技术面、行业地位、风险提示等多个维度进行分析。这种有引导的提问方式能够获得更专业、更有针对性的分析结果。API调用部分包含了完整的错误处理,包括网络超时、认证失败、服务异常等各种情况,确保即使AI服务暂时不可用,也不会影响整个应用的正常运行。
def ai_stock_analysis(stock_info):
"""
集成大模型进行股票分析
设计思路:结构化信息 + 专业提示词
"""
# 构建专业提示词
prompt = f"""作为专业的股票分析师,请分析以下股票:
股票名称:{stock_info['name']}
股票代码:{stock_info['code']}
当前股价:{stock_info['price']}
市盈率:{stock_info['pe_ratio']}
请从以下几个方面进行分析:
1. 基本面分析(财务状况、盈利能力、成长性)
2. 技术面分析(趋势、支撑阻力位)
3. 行业地位和竞争优势
4. 风险提示
5. 投资建议(短期、中期、长期)
请提供详细、专业的分析,用中文回答。"""
# API调用
response = requests.post(
api_url,
headers=headers,
json={
"model": "deepseek-ai/DeepSeek-OCR",
"messages": [
{"role": "system", "content": "资深证券投资顾问"},
{"role": "user", "content": prompt}
]
}
)
三、总结
每个模块的代码都体现了相同的设计框架:在追求功能完整性的同时,始终保持代码的健壮性和可维护性。日志记录和调试信息的输出帮助开发者理解程序的运行状态。清晰的函数命名和详细的注释使得代码即使在没有文档的情况下也具有很好的可读性。这种编写方式不仅让当前项目更加可靠,也为后续的功能扩展和维护打下了良好基础。
四、最终界面展示
数据来源:Tushare数据
项目代码已上传至Github:18June96/financial-platform: 综合性金融数据分析平台

















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









