



一、项目背景
在数据科学和机器学习领域,实践是学习的最佳途径。针对《Python数据挖掘实战》这本书的几章内容,我设计并开发了一个基于Streamlit + AI大模型的交互式Python数据挖掘学习平台,将代码学习、AI辅助、实时编程融为一体,大模型能看懂代码,自动生成中文讲解,还能回答学习者的问题,学习者可以在网页上直接修改代码、运行看结果,特别适合初学者边学边练。
1.1 项目亮点
-
AI智能知识点生成:自动解析Python代码,生成结构化知识点;
-
交互式AI问答:支持自然语言提问,解答代码疑问;
-
实时代码编辑与运行:修改代码后即时查看结果;
-
智能数据文件预览:自动识别并展示数据集结构;
-
章节化内容管理:智能识别章节文件夹,按学习路径组织,循序渐进。
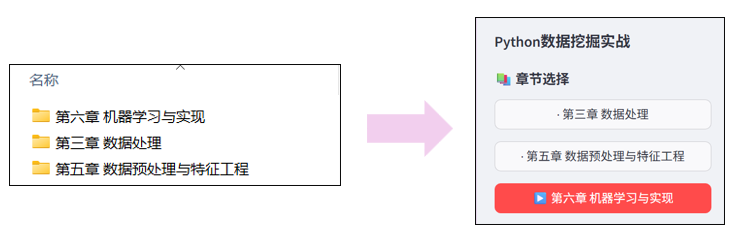
本平台的核心价值在于构建一个AI驱动的智能化学习生态系统,通过两大功能模块帮助进一步学习。首先,AI智能知识点生成系统能够自动解析Python代码并生成结构化的知识框架,不仅提供清晰的功能概述和核心概念解析,还能结合实际应用场景给出拓展建议,降低初学者理解复杂代码逻辑的认知门槛。其次,交互式AI问答系统实现自然语言与编程语言的深度对话融合,学习者可以直接针对代码功能、实现逻辑、优化方案等维度进行提问,获得个性化的实时指导与专业解答。
在此基础上,平台进一步打造了三位一体的沉浸式学习环境,实时代码编辑与运行功能让学习者能够即时修改代码并观察执行结果,形成"编码-运行-调试"的完整学习闭环;智能数据文件预览系统自动识别并可视化展示相关数据集结构,提供直观的数据感知体验;章节化内容管理体系按照科学的学习路径组织知识单元,确保学习过程的系统性和渐进性。
1.2 技术栈
| 模块 | 技术/工具 |
|---|---|
| 前端界面 | Streamlit |
| AI大模型 | 硅基流动平台-ChatGLM-4-9B |
| 数据处理 | Pandas, NumPy |
| 文件操作 | os, hashlib |
| 代码执行 | contextlib, io |
| 网络请求 | requests |
import streamlit as st
import os
import pandas as pd
import numpy as np
import io
import contextlib
import hashlib
from datetime import datetime二、系统架构
系统采用模块化设计,包含以下核心模块:
-
代码学习模块:展示、编辑、执行Python代码;
-
AI智能辅助模块:集成大模型,生成知识点与智能问答;
-
文件管理模块:自动扫描章节与数据文件;
-
界面交互模块:Streamlit构建的直观UI;
-
缓存管理模块:双层级缓存提升性能。
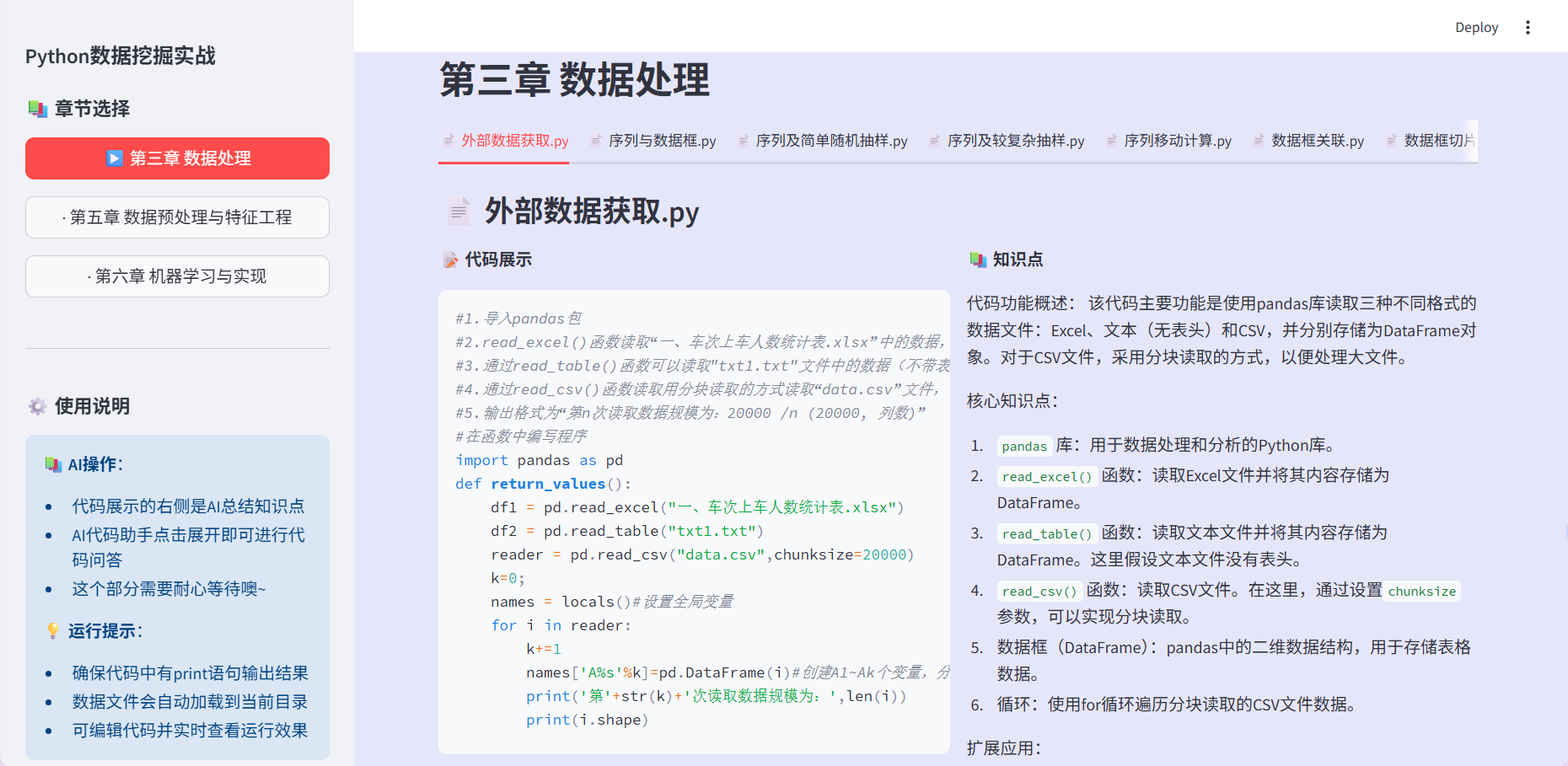
三、Streamlit界面设计效果
-
左侧导航:章节快速切换
-
右侧主区:四分区清晰布局
-
响应式设计:适应不同屏幕尺寸
-
视觉层次:颜色、图标、间距提升可读性
四、核心代码功能详解
4.1 页面基础配置与样式设计
-
st.set_page_config():设置Streamlit页面全局配置 -
CSS自定义:修改字体、颜色、背景,提升视觉体验
# =页面配置
st.set_page_config(
page_title="Python数据挖掘实战",
page_icon="❀",
layout="wide", # 使用全宽布局,适合代码展示
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main { padding-top: 1rem; }
h1, h2, h3 { color: #2E4057; font-family: "Microsoft YaHei", sans-serif; }
.sidebar .sidebar-content { background-color: #F8F9FA; padding-top: 1rem; }
/* 添加淡紫色背景 */
.stApp {
background-color: #E6E6FA;
}
</style>
""", unsafe_allow_html=True)4.2 自动识别章节函数
-
os.listdir():遍历目录内容; -
os.path.isdir():判断是否为文件夹; -
智能识别逻辑:同时支持中文"第X章"和数字开头格式;
-
错误处理:try-except确保程序健壮性。
通过os模块遍历项目目录,智能识别以"第"开头或数字开头的文件夹作为学习章节,自动建立章节索引;在选定章节文件夹内扫描所有.py文件,按文件名排序后呈现给用户,支持多种命名规范;并且使用UTF-8编码读取Python文件内容;最后根据用户选择的章节和文件,动态构建文件路径,实现学习资源的灵活组织和快速访问。
# 获取所有章节文件夹
def get_chapter_folders():
folders = []
current_dir = os.getcwd()
try:
# 查找所有以"第"开头或以数字开头的文件夹
for item in os.listdir(current_dir):
item_path = os.path.join(current_dir, item)
if os.path.isdir(item_path):
# 匹配章节文件夹:如"第三章"、"第2章"、"Chapter 3"、"3. xxx"等
if ("第" in item and "章" in item) or item[0].isdigit():
folders.append(item)
except Exception as e:
st.error(f"读取目录失败: {e}")
return sorted(folders)4.3 自动识别章节下的py文件
item.endswith('.py'):筛选Python文件
# 获取章节文件夹下的所有.py文件
def get_chapter_files(chapter_folder):
files = []
chapter_path = os.path.join(os.getcwd(), chapter_folder)
if os.path.exists(chapter_path):
try:
for item in os.listdir(chapter_path):
if item.endswith('.py'):
files.append(item)
except:
pass
return sorted(files)4.4 读取文件内容
-
os.path.exists():检查文件是否存在; -
os.path.join():跨平台路径拼接。
# 读取Python文件内容
def read_python_file(chapter_folder, file_name):
file_path = os.path.join(os.getcwd(), chapter_folder, file_name)
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except:
return "# 读取文件失败"
return "# 文件不存在"4.5 AI知识点生成系统(带缓存)
-
@st.cache_data(ttl=3600):Streamlit缓存装饰器,缓存1小时; -
st.session_state:会话状态管理,保持用户状态; -
双缓存策略:短期用session_state,长期用装饰器缓存;
-
缓存键设计:基于"章节_文件名"确保唯一性。
这个知识点获取部分是调用大模型进行生成,大模型精准读取Python源代码,调用ChatGLM-4-9B进行代码理解,生成“功能概述-核心知识点-应用场景”三段式内容。
# 缓存AI生成的知识点,避免重复调用
@st.cache_data(ttl=3600, show_spinner=False) # 缓存1小时
def generate_knowledge_with_ai_cached(py_content, py_file, chapter_folder):
"""带缓存的AI知识点生成"""
try:
return generate_knowledge_with_ai(py_content, py_file, chapter_folder)
except Exception as e:
return f"# AI知识点生成失败: {str(e)}"
# 获取知识点:直接调用AI生成
def get_knowledge(chapter_folder, py_file):
if not py_file:
return "# 未选择文件"
# 创建唯一的缓存键
cache_key = f"knowledge_{chapter_folder}_{py_file}"
# 检查是否已生成过知识点(优先使用session_state缓存)
if cache_key in st.session_state:
return st.session_state[cache_key]
# 直接调用AI生成知识点
try:
# 读取Python文件内容
py_content = read_python_file(chapter_folder, py_file)
if not py_content or py_content.startswith("# 文件不存在") or py_content.startswith("# 读取文件失败"):
error_msg = "# 无法读取Python文件内容"
st.session_state[cache_key] = error_msg
return error_msg
# 使用缓存的AI生成(避免重复调用)
with st.spinner("🤖正在总结知识点..."):
ai_content = generate_knowledge_with_ai_cached(py_content, py_file, chapter_folder)
# 存储到session_state
st.session_state[cache_key] = ai_content
return ai_content
except Exception as e:
error_msg = f"# 知识点生成失败: {str(e)}\n请确保已安装requests库: pip install requests"
st.session_state[cache_key] = error_msg
return error_msg4.6 大模型API调用实现
-
API请求结构:符合OpenAI兼容格式;
-
系统角色设计:定义AI的教学专家身份;
-
提示词工程:结构化输出要求,确保内容质量;
-
超时与重试:设置30秒超时,提高稳定性;
-
温度参数:
temperature=0.7平衡创造性与稳定性; -
token限制:控制输入输出长度,节省成本。
对硅基流动平台的大模型API进行配置,设置合理的超时时间和重试策略,保障服务可靠性。建立"Python数据挖掘教学专家"系统角色,定义专业的回答风格和内容结构,针对代码分析和教学场景优化提示词,明确要求中文回答、结构清晰、适合初学者等约束条件,确保生成内容的教学价值,并且实现完善的异常处理机制,包括网络超时、认证失败、服务异常等情况,提供友好的用户提示。
# 使用硅基流动API生成知识点
def generate_knowledge_with_ai(py_content, py_file, chapter_folder):
import requests
# 硅基流动平台的API配置
api_key = "你的API密钥" # API密钥
api_url = "https://api.siliconflow.cn/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 构建分析请求
prompt = f"""作为Python数据挖掘教学助手,请分析以下Python代码,生成详细的知识点讲解:
- 文件名称:{py_file}
- 所属章节:{chapter_folder}
{py_content[:3000]} # 限制代码长度,避免超出token限制
请按照以下结构生成知识点讲解:
代码功能概述:简要说明这段代码的主要功能
核心知识点:列出代码中涉及的主要Python/数据挖掘知识点
扩展应用:说明这些知识在实际项目中的应用场景
要求:
使用中文回答,语言简洁明了,适合初学者理解,重点突出,结构清晰
"""
data = {
"model": "THUDM/glm-4-9b-chat", # 硅基流动上的模型
"messages": [
{
"role": "system",
"content": "你是一位资深的Python数据挖掘教学专家,擅长用简洁易懂的语言整理代码知识点,生成的内容美观,文本在不超过500字"
},
{
"role": "user",
"content": prompt
}
],
"temperature": 0.7,
"max_tokens": 500,
}
try:
response = requests.post(api_url, headers=headers, json=data, timeout=30)
if response.status_code == 200:
result = response.json()
ai_content = result['choices'][0]['message']['content']
return ai_content
else:
return f"#调用失败 (状态码: {response.status_code})\n响应内容: {response.text[:500]}"
except requests.exceptions.Timeout:
return "## ⏰ 请求超时,请稍后重试"
except requests.exceptions.ConnectionError:
return "## 🔌 网络连接失败,请检查网络"
except Exception as e:
return f"## ❌ AI生成失败: {str(e)}" 4.7 代码安全执行环境
-
io.StringIO():内存缓冲区,捕获输出; -
contextlib.redirect_stdout/stderr:重定向标准输出/错误; -
目录切换:确保相对路径引用的数据文件能正确加载;
-
隔离环境:
exec(code, exec_globals)限制可访问的变量; -
异常分类:区分语法错误和运行时错误;
-
finally保证:确保目录总是被恢复。
def run_code(code, chapter_folder):
"""
在隔离环境中安全执行用户代码
"""
output = io.StringIO() # 创建内存字符串缓冲区
original_dir = os.getcwd() # 保存原始工作目录
try:
# 切换到章节目录(确保相对路径有效)
chapter_path = os.path.join(original_dir, chapter_folder)
if os.path.exists(chapter_path):
os.chdir(chapter_path)
# 重定向输出流,捕获所有输出
with contextlib.redirect_stdout(output), contextlib.redirect_stderr(output):
# 创建安全的执行环境
exec_globals = {
'pd': pd, # 预加载Pandas
'np': np, # 预加载NumPy
'__builtins__': __builtins__ # 保留内置函数
}
# 执行用户代码
exec(code, exec_globals)
output_text = output.getvalue()
# 处理无输出的情况
if not output_text.strip():
output_text = """代码执行成功,但没有任何输出,有以下原因可追溯:
1. 代码只定义了变量/函数但没有调用print
2. 代码直接修改了数据但没有显示结果
3. 代码执行了计算但没有输出
建议:添加print语句查看结果"""
return {"success": True, "output": output_text}
except SyntaxError as e:
return {"success": False, "output": f"语法错误: {str(e)}"}
except Exception as e:
return {"success": False, "output": f"运行时错误: {str(e)}"}
finally:
os.chdir(original_dir) # 无论如何都恢复原始目录4.8 交互式AI问答系统
-
上下文融合:将代码内容、知识点、问题三部分结合;
-
角色定义明确:系统提示词定义教学助手身份;
-
长度控制:代码2000字,知识点1000字,防止token超限;
-
结构化输出要求:要求结合代码示例,提供可运行片段。
def ask_ai_question(py_content, knowledge, question, chapter_folder, py_file):
"""
基于代码上下文进行智能问答
"""
import requests
# 系统提示词定义AI角色
system_prompt = """你是一位Python数据挖掘教学助手,专门帮助学生理解代码和解答问题。
基于提供的代码内容和知识点,回答用户的问题。
要求:
1. 回答要具体,结合代码示例
2. 用简洁易懂的中文解释
3. 如果涉及代码修改,提供可运行的代码片段
4. 鼓励学生思考和动手实践
5. 如果问题不清晰,可以请求澄清
"""
# 构建包含上下文的用户提示词
user_prompt = f"""请基于以下信息回答我的问题:
【代码信息】
- 文件:{py_file}
- 章节:{chapter_folder}
【代码内容】
{py_content[:2000]}
【知识点总结】
{knowledge[:1000]}
【我的问题】
{question}
请给出详细、具体的回答,可以结合代码示例解释。"""
data = {
"model": "THUDM/glm-4-9b-chat",
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
"temperature": 0.7,
"max_tokens": 800, # 问答可以更长一些
}
# 发送请求并处理响应(类似知识点生成)
# ...4.9 数据文件智能预览系统
-
数据预览:使用
df.head(10)显示前10行; -
形状信息:显示DataFrame维度信息;
-
唯一键生成:
hashlib.md5()避免按钮key冲突。
def display_data_files(chapter, py_file):
"""
显示章节下的数据文件并提供预览功能
"""
chapter_path = os.path.join(os.getcwd(), chapter)
data_files = []
if os.path.exists(chapter_path):
# 筛选常见数据文件类型
for item in os.listdir(chapter_path):
if item.endswith(('.xlsx', '.csv', '.txt')) and item != py_file:
data_files.append(item)
if data_files:
for data_file in sorted(data_files):
# 使用哈希生成唯一键
preview_key = f"preview_{hashlib.md5(f'{chapter}_{py_file}_{data_file}'.encode()).hexdigest()[:8]}"
# 预览按钮
if st.button(f"📊 预览 {data_file}", key=preview_key):
file_path = os.path.join(chapter_path, data_file)
try:
if data_file.endswith('.xlsx'):
df = pd.read_excel(file_path)
st.dataframe(df.head(10), use_container_width=True)
st.caption(f"数据形状: {df.shape}")
elif data_file.endswith('.csv'):
# 编码兼容处理
try:
df = pd.read_csv(file_path, encoding='utf-8')
except UnicodeDecodeError:
df = pd.read_csv(file_path, encoding='gbk')
st.dataframe(df.head(10), use_container_width=True)
st.caption(f"数据形状: {df.shape}")
elif data_file.endswith('.txt'):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
except UnicodeDecodeError:
with open(file_path, 'r', encoding='gbk') as f:
content = f.read()
st.text_area("文件内容", content[:1000], height=200)
except Exception as e:
st.error(f"预览失败: {str(e)}")
else:
st.caption("暂无其他数据文件")4.10 Streamlit界面布局设计
-
响应式布局:
layout="wide"+st.columns(); -
动态导航:根据文件夹自动生成导航按钮;
-
标签页系统:多文件时自动创建标签页;
-
状态管理:
st.session_state保持用户选择状态; -
唯一键策略:使用哈希避免Streamlit的key重复错误。
# 侧边栏设计
with st.sidebar:
st.header("Python数据挖掘实战")
st.markdown("### 📚 章节选择")
# 动态生成章节导航按钮
for i, chapter in enumerate(chapter_folders):
nav_key = f"nav_{hashlib.md5(f'nav_{chapter}_{i}'.encode()).hexdigest()[:8]}"
# 高亮显示当前选中章节
is_selected = (st.session_state.selected_chapter == chapter)
button_label = f"{'▶️' if is_selected else '·'} {chapter}"
if st.button(button_label, key=nav_key, use_container_width=True,
type="primary" if is_selected else "secondary"):
st.session_state.selected_chapter = chapter
st.rerun()
# 主内容区 - 标签页设计
if len(chapter_files) > 1:
# 多文件时使用标签页
sub_tabs = st.tabs([f"📄 {file}" for file in chapter_files])
for sub_idx, py_file in enumerate(chapter_files):
with sub_tabs[sub_idx]:
display_file_content(current_chapter, py_file, f"{sub_idx}")
else:
# 单文件时直接显示
display_file_content(current_chapter, chapter_files[0], "0")4.11 文件内容显示与编辑系统
-
四分区布局:代码展示、知识点、AI问答、编辑运行;
-
独立状态管理:每个文件有独立的编辑和运行状态;
-
文本区域编辑:
st.text_area()提供代码编辑功能; -
实时反馈:运行后立即显示结果。
def display_file_content(chapter, py_file, tab_idx):
"""
显示单个Python文件的所有功能模块
"""
# 1. 读取原始代码
code = read_python_file(chapter, py_file)
# 2. 创建学习区(代码 + 知识点)
col1, col2 = st.columns([1, 1])
with col1:
st.markdown("**📝 代码展示**")
st.code(code, language='python')
with col2:
st.markdown("**📚 知识点**")
knowledge = get_knowledge(chapter, py_file) # 调用AI生成
st.markdown(knowledge)
# 3. AI问答区域
display_ai_section(chapter, py_file, code, knowledge)
# 4. 编辑运行区
st.markdown("#### ✏️ 编辑与运行")
# 为每个文件创建独立的编辑状态
file_key = f"{chapter}_{py_file}_{tab_idx}"
if file_key not in st.session_state:
st.session_state[file_key] = code
# 可编辑的代码区域
edited_code = st.text_area(
"修改代码(可在此处编辑后运行)",
value=st.session_state[file_key],
height=300,
key=f"editor_{file_key}",
label_visibility="collapsed"
)
# 更新编辑状态
st.session_state[file_key] = edited_code
# 运行按钮
col_btn1, col_btn2 = st.columns([1, 1])
with col_btn1:
if st.button("▶️ 运行代码", key=f"run_{file_key}"):
result = run_code(edited_code, chapter)
st.session_state[f"result_{file_key}"] = result
st.rerun()
# 显示运行结果
if f"result_{file_key}" in st.session_state:
result = st.session_state[f"result_{file_key}"]
# ... 显示成功/失败结果五、开发中遇到额问题和解决方案
5.1 大模型响应延迟问题
初期API调用响应时间较长,影响用户体验。通过引入缓存机制和优化提示词长度,将平均响应时间降低。
5.2 多文件状态管理问题
在标签页间切换时,编辑状态容易丢失。利用st.session_state为每个文件创建独立的状态存储,实现了状态持久化。
5.3 AI生成内容稳定性问题
大模型生成的内容格式不一致。通过优化系统角色定义和输出约束,提高了生成内容的结构化和稳定性。
六、项目总结与未来展望
本项目成功构建了一个Python数据挖掘交互式学习平台,将AI大模型能力与编程教学深度融合,创造一种智能化、个性化的学习模式。平台不仅证明了Streamlit在构建数据科学教学应用中的强大能力,也展示了国产大模型在实际应用场景中的价值潜力。
6.1 项目成果总结
平台实现了代码学习、AI辅助、实践操作的一体化整合,提供了从理论到实践的完整学习路径。技术实现上,成功解决了大模型集成、代码安全执行、状态管理等关键技术问题,构建了一个稳定可靠的教学系统。
6.2 未来改进方向
在功能层面,计划增加学习进度跟踪、个性化推荐、代码版本对比等高级功能;在技术层面,探索多模型融合、本地模型部署、性能优化等方向;在教学层面,扩展更多数据挖掘算法和应用场景,丰富学习内容。
七、项目网页展示
Python数据挖掘网页
项目代码已上传至Github:18June96/Python_data_platform: Python


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









