




标题:
Large language models for oncological applications 大语言模型的肿瘤学应用
Abstract:
诸如ChatGPT之类的大型语言模型已经引起了公众和科学界的关注。这些模型可能支持肿瘤学家的工作。肿瘤学家应该熟悉大型语言模型,以利用它们的潜力,同时意识到潜在的危险和局限性。
正文:
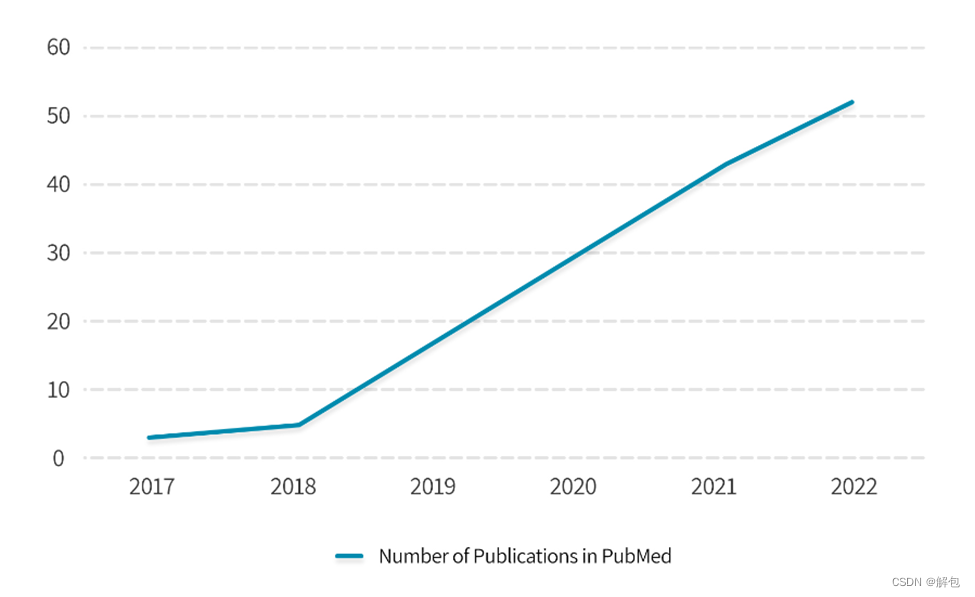
诸如ChatGPT之类的大型语言模型已经引起了公众和科学界的关注。尽管科学界对LLM生成数据的能力存在不小的争议(Editorials Nature 2023),但重要的是要认识到这些模型在各种NLP应用中的潜力,包括文本摘要、问答和会话人工智能。尽管存在合理的担忧,这项革命性的技术有望通过简化临床决策、加强患者教育和加快研究,对肿瘤学产生重大影响(Rösler等人,2023)。深度学习自然语言处理(NLP)越来越多地用于医学和肿瘤学,允许自由文本分析(Hirschberg and Manning 2015;Sorin et al. 2020a)。深度学习NLP在医学领域的出版物数量也在不断增加(补充图1)。
近年来,Transformer模型已成为许多NLP应用的最先进方法。Transformers是一种深度学习算法,可以分析和处理大量文本数据。它们由使用了注意力机制的多个层次堆叠而成。该机制使模型能够给文本中的各词语分配不同的重要性等级(补充图2)。与传统的机器学习方法不同,transformer专注于文本中单词的上下文。通过考虑周围的单词及其它们之间的关系,transformer能够更好地捕捉文本中的复杂模式和细微关系(Vaswani 2017)(补充图3)。
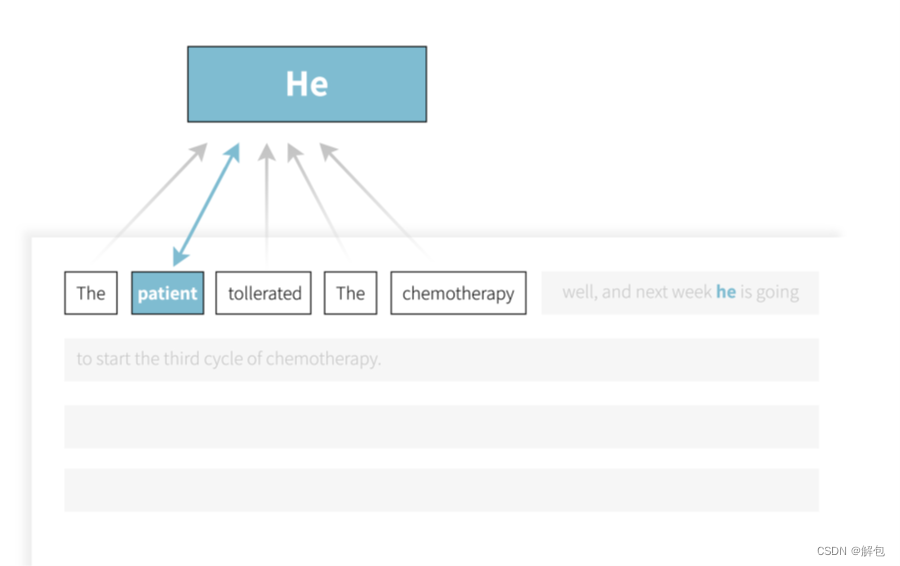
通过在每个周围的单词上训练小型神经网络来为关注的单词提供上下文。考虑以下句子:“患者对化疗的耐受性很好,下周他将开始第三个周期的化疗。该模型同时分析句子中的所有单词,根据与“他”一词的相关性对其进行加权。通过这样做,模型能够为“他”这个词提供上下文,并将其与“患者”一词联系起来。经Sorin等人许可转载,用于肿瘤学应用的深度学习自然语言处理。《柳叶刀肿瘤学》。2020
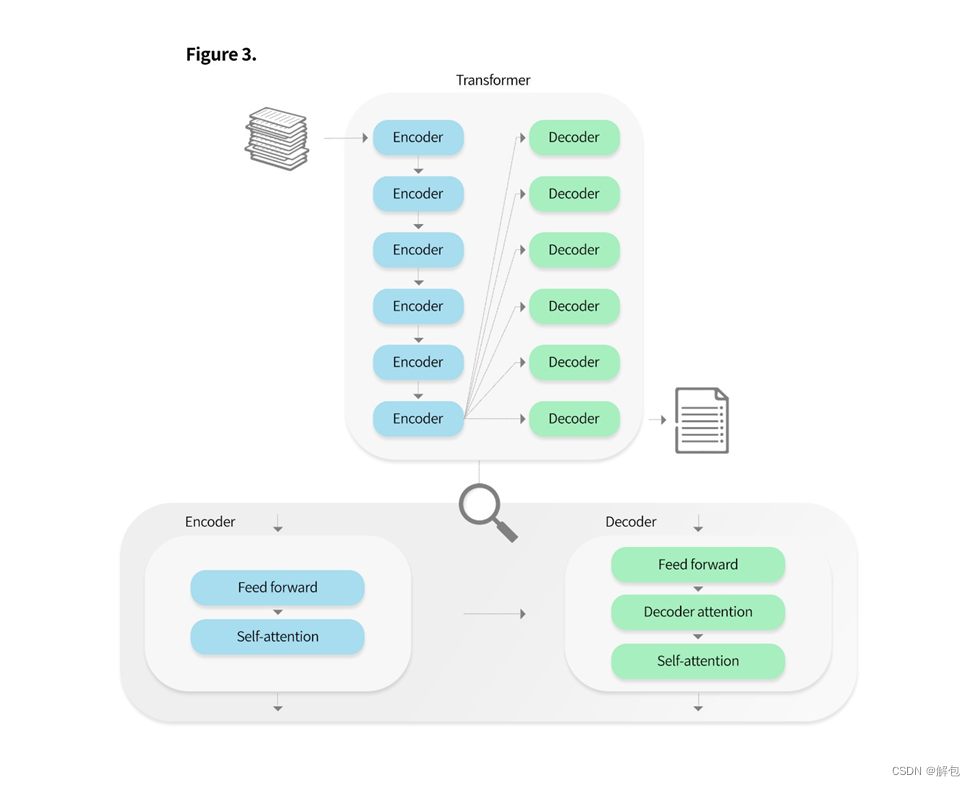
Transformer是一种使用编码器和解码器来处理输入的神经网络。输入经过编码器层,然后经过解码器层,产生最终输出。编码器通过self-attention机制来处理输入。这个过程将输入与输入的其他部分联系起来进行分析。每个编码器还有一个前馈神经网络。信息沿单一方向从输入层传递到输出层,而不进行循环。随后编码器的输出被传递到解码器。每个解码器层包括self-attention层、decoder attention层和前馈神经网络。Decoder attention能分析编码器的输出与输入的关系。经过整个过程,transformer可以理解输入中元素之间的上下文和关系,并根据这种理解生成输出。
transformers在各种NLP任务中的出色性能引起了人们进一步探索更大模型的兴趣。LLM目前正处于研发前沿。这些模型使用多样且广泛的文本数据进行预训练,包含数十亿乃至万亿个单词和参数。这使得它们能对不同的NLP任务给出近似于人类的响应。GPT((Generative Pre-training Transformer)是一个典型的例子。“ChatGPT”是OpenAI提供的一个免费使用的公共聊天机器人。它能够从文本数据中捕捉复杂的关系,因而成为了各种应用程序中的强大工具。在医疗保健领域,该模型处理和分析大量文本的能力,使其在诸如医学文献综述、患者沟通和临床决策支持等任务上都是有价值的。也有专门为科学和医学目的而训练的LLM。例如,以PubMed的出版物为训练数据集的BioBERT(Lee 2019)。另一个例子是MedPaLM,这是一个由谷歌推出的医疗问答聊天机器人,其在HealthSearchQA、PubMedQA等医疗数据集上进行了训练。
在肿瘤学领域,LLM有几个潜在用途(Singhal等人,2022;Yang等人,2022年;Kather 2023)。这些模型可以用于临床医生的日常临床工作,以节省时间并改善医疗服务水平(补充图4)。例如,LLM可用于识别和总结研究文本或临床笔记中的关键内容。LLM可以总结放射学或病理学报告中的主要发现(Elkassem和Smith 2023;马等人,2021)。该算法甚至可能提出适当的管理(刘2023)(图1)。这些信息可以以清晰简洁的方式组织和呈现,使肿瘤学家能够快速获取患者的重要数据并对其采取行动。我们使用LLM“ChatGPT”,通过总结合成的放射性报告展示了一个可能的用例(补充图5)。

该图展示了大型语言模型帮助肿瘤学家进行日常工作的一个场景。这是一种潜在用途的例子。大型语言模型可以帮助肿瘤学家快速总结和分析患者数据,并提供有助于癌症诊断和治疗的见解。
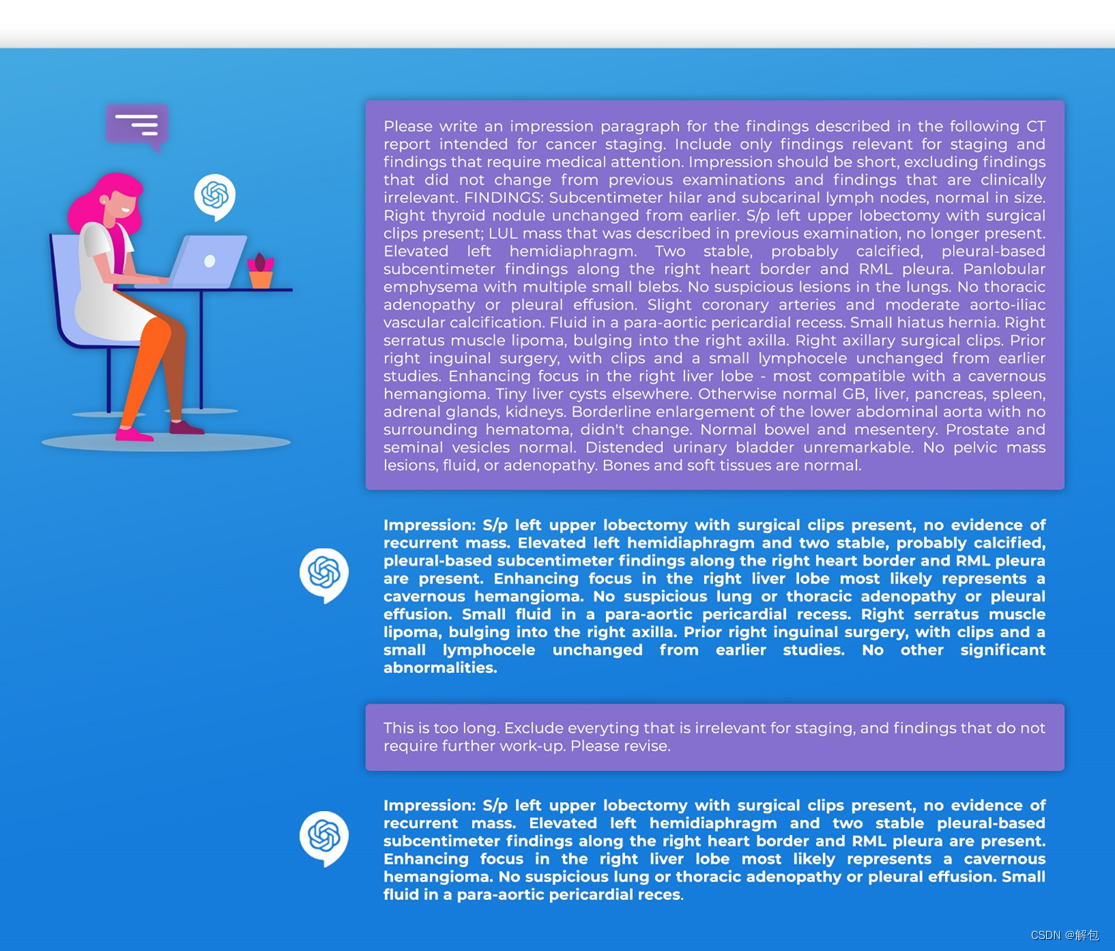
此图显示了我们与ChatGPT进行的实际“对话”。我们要求它在一份用于癌症分期的合成CT报告上写一个Impression部分。
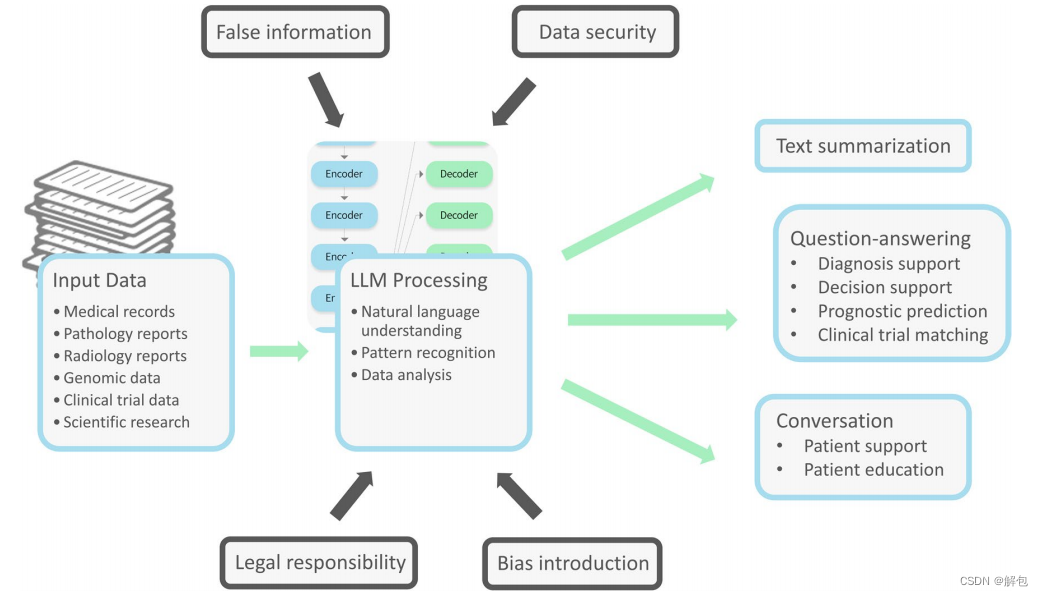
LLM可以用于不同主题的问答,包括肿瘤学。通过与ChatGPT交互,医生可以快速获取相关信息并了解所有类型的主题,从而有可能增强他们的知识和决策能力。例如,Holmes等人最近的一份出版物(2023)评估了四种不同的LLM(包括Bard、BLOOMZ、ChatGPT-3.5和ChatGPT-4)在放射肿瘤物理学的多项选择题中的表现。ChatGPT-4是唯一一个在测试分数上优于医学物理学家的模型(Holmes等人,2023)。
LLM可以被用于有效地教育和告知患者其癌症诊断、可用的治疗方案以及潜在的副作用。这些模型可以为公众生成易于理解的医疗个人数据解释(Jeblick等人,2022)。通过用户友好的界面,患者可以与模型交互,提出问题并接收个性化信息。这使得患者能够更好地理解他们的自身状况并对治疗做出明智的决定,同时促进患者和医疗保健提供者之间的沟通。LLM也可以对科学研究产生巨大影响。补充表1总结了肿瘤学潜在应用的不同想法。
|
类别 |
用途 |
|
结构化临床数据 |
|
|
支持临床工作 |
|
|
个性化医疗 |
|
|
患者支持和教育 |
|
|
研究 |
|
然而,必须考虑这项技术的局限性。训练数据集的质量和多样性会影响LLM的性能。数据必须能代表各种癌症类型、阶段和人口统计数据,以创建无偏见的模型。然而,获取准确、多样和庞大的数据集是具有挑战性的。数据分散在各个机构,存在患者隐私问题,并且医疗机构不愿共享数据。此外,罕见的癌症病例或代表性不足的人群可能没有足够的数据,导致模型中潜在的盲点。最后,使用未经验证的数据源来训练LLM会带来将不正确或过时的信息纳入模型的风险。这可能会导致模式输出不准确或过时的应答,从而对患者的治疗产生负面影响。
目前,LLM有时会产生错误或虚假的信息,但它们看起来似乎很可信。在临床应用中,错误信息可能会产生严重后果。对模型的过度依赖可能会导致人类专业知识的减少。这反过来将导致无法识别模型何时出错。此外,基于训练数据,算法会复制偏见和歧视(Sorin和Klang 2021)。解决LLM中的偏见对于确保其在肿瘤学中的安全有效部署至关重要。这可以通过预处理训练数据来完成,确保数据代表不同的患者群体和癌症类型。让肿瘤学家参与进来,可以帮助确定潜在的偏见来源,并指导选择高质量和可靠的数据来源。在训练过程中,可以使用对抗性示例(Sorin等人2020a,b)来最小化模型预测中的偏见。为了确保不引入偏差,还必须定期评估和监测不同人群亚组的模型性能。
为了在肿瘤学或任何其他医学领域有效利用LLM,医疗保健提供者和患者应当对模型生成的回答的准确性和可靠性充满信心。否则,将这些人工智能模型整合到医疗实践中是不可行的。为了培养信任,提高人工智能算法的透明度很重要,即让人们更清楚模型是如何得出结论的。由于LLM的复杂性和其庞大的规模,提高LLM的透明度可能是具有挑战性的。因此,培养信任可能要包含对模型的基本逻辑进行解释,或为其预测提供置信度分数。此外,实施验证机制,如将生成的内容与可信的医疗数据库进行交叉引用,也有助于降低错误信息的风险。
如果将这些模型纳入医疗决策过程,则会涉及伦理方面和法律责任问题。制定明确的指导方针、法规和道德框架(联合国教科文组织2022年)对于确保在医学中负责任地使用人工智能至关重要。这些模型的使用必须符合《健康保险便携性和责任法案》(HIPAA)(1996年HIPAA法案)。当前版本的GPT不符合HIPAA法规,可能会损害患者的机密性。因此,在具有足够防护措施的专业级版本推出之前,临床医生应避免输入受保护的健康信息。此外,随着LLM在医疗保健中越来越普遍,它们可能成为对抗性网络攻击的目标(Finlayson等人,2019)。因此,需要强有力的安全措施,包括加密、安全访问控制和对潜在漏洞的持续监控。
该技术在肿瘤学中有一些很有前景的未来方向。LLM可以被看作“few-shot learner”(Brown等人,2020),这意味着一旦经过训练,它们就可以通过少量的例子适应新的领域。这与传统的机器学习模型形成了鲜明对比,它们往往需要很大的数据集来学习新任务或微调以适应特定主题。这不仅使LLM变得灵活,而且如果对特定狭窄主题的大量数据进行微调,则可能会非常高效。
这项技术呈指数级增长,我们只能想象它在未来几年的表现。例如,具有1750亿个参数的GPT-3比GPT-2大100倍。GPT-4推出于2023年3月14日,它更大、更准确。LLM最终可能会在肿瘤学领域节省临床研究和患者护理的成本。该技术的同化也已经在发生了。因此,应当讨论和解决风险和局限性问题。可能需要专家就LLM的使用发表一致声明,以确保在日常临床工作中安全、负责任地使用该技术。
跨学科合作对于最大限度地发挥LLM在肿瘤学中的潜力至关重要。人工智能专家、数据科学家、肿瘤学家和政策制定者之间的协调努力对于LLM在实践中的成功开发和实施至关重要。人工智能专家和数据科学家开发和完善算法。肿瘤学家可以贡献他们的临床专业知识,指导开发过程,并解决临床相关的问题。他们还能确保人工智能生成的内容是准确的、有意义的和可操作的。监管者和政策制定者必须制定并执行透明的指导方针和道德框架,以管理LLM在医疗保健中的使用,保护患者安全和隐私。通过培养合作氛围,利益相关者可以克服挑战,增强LLM的优势,并最终改善肿瘤学中的患者护理和结果。
Conclusion
总之,我们可能正处于NLP革命的边缘。LLM在许多人类语言任务中取得了最先进的成果,并具有适应新任务和领域的能力。其中的一些模型可以通过互联网轻松访问,便于随时使用。在肿瘤学方面,它们可以提高癌症研究和治疗的效率和准确性。尽管LLM存在局限性和相关问题,但LLM在肿瘤学中的应用很可能会扩大和发展。鉴于这些重大进展,肿瘤学家应该熟悉这项技术及其潜在的好处、成本和局限性。


















 4340
4340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









