






当前,大语言模型LLM在特定任务上的训练范式基本上都是:先监督微调SFT,再强化学习RL训练。两者都是作为预训练之后的“后训练阶段”,旨在进一步调优模型的行为表现。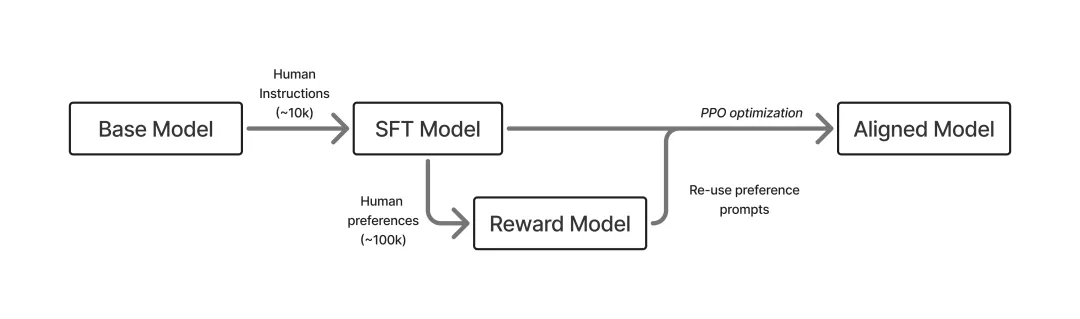
不同之处在于,前者(监督微调SFT)旨在激发通用预训练模型已学得的知识,通过特定领域的数据集来提升通用模型在该特定领域的能力;后者(强化学习RL)通过使用如PPO、DPO、GRPO等强化学习算法来对SFT后的模型进行进一步优化,通过最大化奖励模型所给出的分数,来驱使模型的输出结果符合人类的期望,从而符合人类的价值观。
下面我们从任务定义、适配任务、训练数据和训练方式来对两者进行详细介绍。
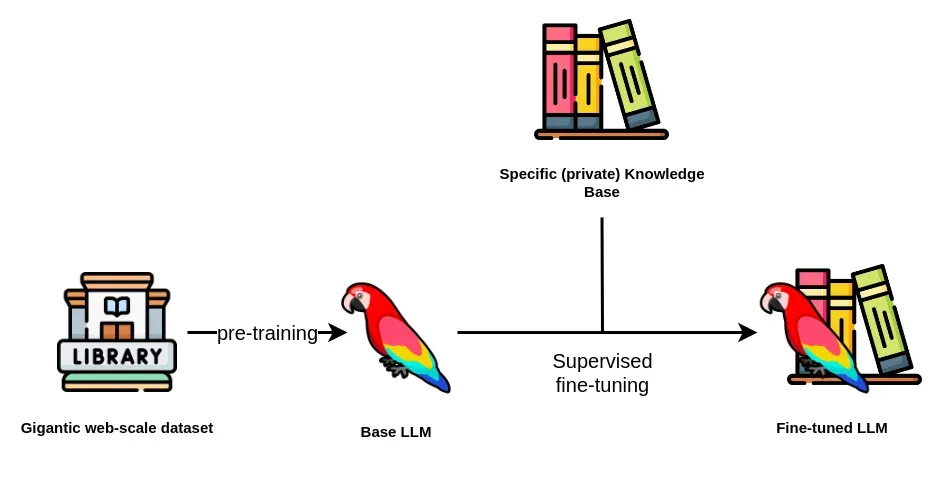
监督微调SFT
准确地说,其可以理解为“精教”。模型通过模仿标准答案来学习,目标是让模型的输出风格、格式和内容质量尽可能接近“教师”(特定领域)提供的优秀范例。它是一个模仿学习的过程。
任务定义:用户给定一个输入(Prompt),模型需要生成一个输出答案(回答,Response)。SFT的任务是学习一个从Prompt到Response的映射函数,使得模型的输出与训练数据中提供的“标准答案”在内容、格式和风格上高度一致。它本质上是一个有监督的分类(下一个token预测)或回归任务。
适配任务:机器翻译、情感分析、问答、代码生成等生成性任务均可。
训练数据:以机器翻译为例,
{
"source": "The model learns patterns from large-scale data.",
"target_text": "Le modèle apprend des motifs à partir de données à grande échelle."
}以情感分析为例:
{
"text": "The system responded promptly and the interface was intuitive.",
"label": "positive"
}训练方式:包括全量微调(需要大量数据、算力成本高)、参数高效微调(PEFT,例如LoRA)等,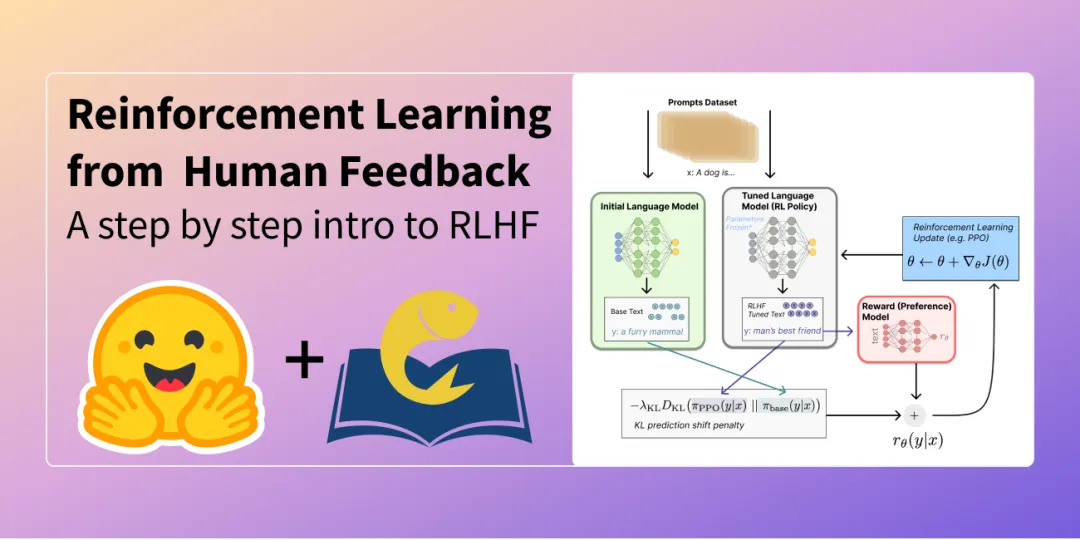
强化学习RLHF
可以理解为“引导”,引导正确的价值观。模型不再有标准答案,而是通过与环境(通常是一个奖励模型,强化学习的重点在于需要设计一个奖励模型)互动,根据获得的“奖励”或“惩罚”信号来自我调整和优化,目标是学会在复杂、开放的任务中做出整体上更符合人类偏好的决策。它是一个试错学习的过程。
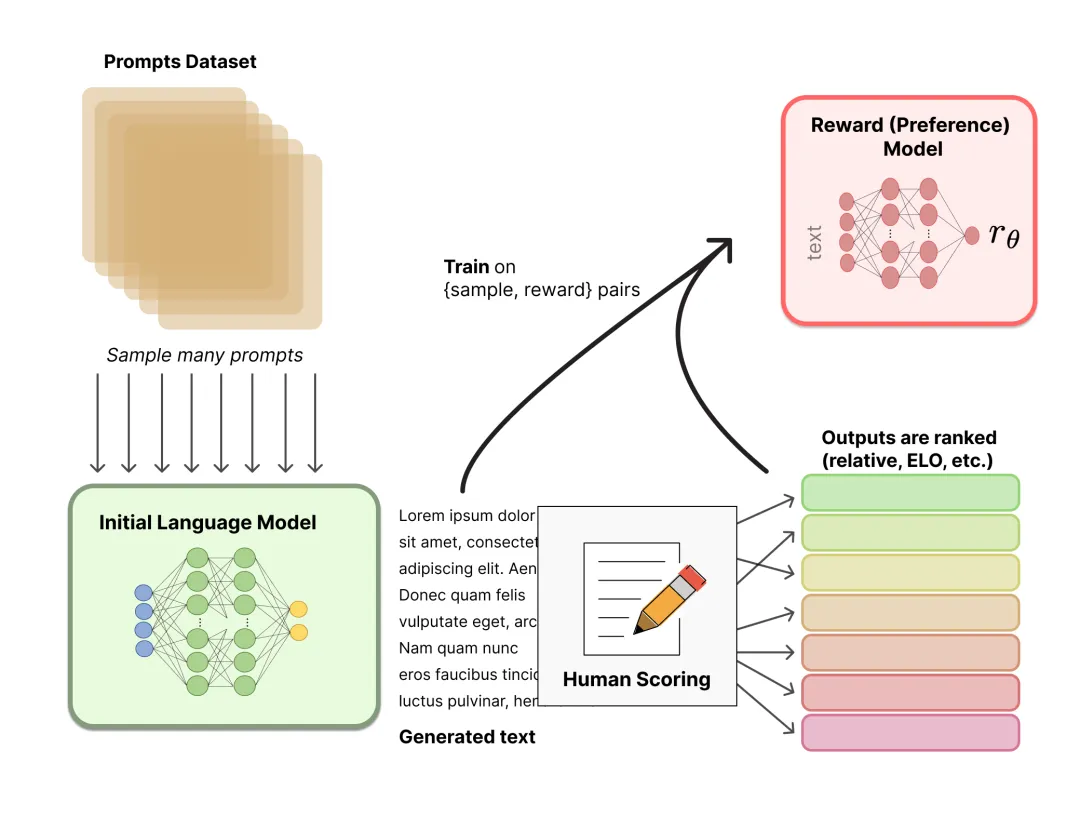
任务定义:模型(作为一个智能体,Agent)在面对一个状态(当前的Prompt和已生成的部分文本)时,需要选择一个动作(生成下一个token)。这个动作会改变状态,并可能从环境(奖励模型,Reward Model)中获得一个奖励信号。RL的任务是学习一个生成策略,使得从开始到生成完整回答的整个过程中,所获得的累积期望奖励最大化。
适配任务:评分任务、迫选任务、排序任务、反馈任务等。
训练数据:以评分任务为例,
{
"text": "Quantum computers leverage qubits to perform computations that are infeasible for classical machines.",
"ratings":
{ "accuracy": 5,
"clarity": 4,
"scientific_depth": 5,
"coherence": 5
}
}以迫选任务为例,
{
"prompt": "Explain how neural networks process visual information.",
"outputs": [
{ "text": "Neural networks analyze images by converting pixels into numerical tensors and passing them through layered transformations.", "rating": 1 },
{ "text": "A convolutional neural network uses filters to detect edges, textures, and higher-level patterns across layers.", "rating": 2 }
],
"preferred_output": 1
}以反馈任务为例
{
"prompt": "Describe a snowstorm.",
"output": "Snow spiraled through the sky, blanketing the city in a cold, shimmering white.",
"feedback": "The description is clear, but adding more sensory details about the wind, temperature, or sound could enhance the atmosphere."
}训练方式:
-
PPO是常用的基于策略梯度的RL算法,采用剪切(clip)或罚项约束策略更新幅度,使用KL散度来控制模型的变化,从而在高维深度策略网络上既保持稳定性又能多次小批量更新样本以提高样本利用率。
-
DPO用于基于“偏好对”进行微调的方法,通过对比人类偏好对训练一个奖励/排序参数化,并在该参数化下直接导出或优化最优策略,避免了传统 RLHF 中复杂的策略-奖励交替训练流程。
-
GRPO目标是通过对样本/任务分组或对比组内相对评价来提高微调效果和样本效率,其实现细节和命名尚未像 PPO 那样形成单一权威标准,常被用于对推理/数学能力等专门技能进行后训练。


















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









