






当我们谈论人工智能时,经常会遇到"强化学习"和"智能体"这两个术语。很多人会问:它们是一回事吗?有什么区别?为什么AlphaGo和AlphaStar既被称为强化学习的成功,又被称为智能体的典型?
要回答这些问题,我们需要从根本上理解这两个概念的本质。

一、强化学习和智能体
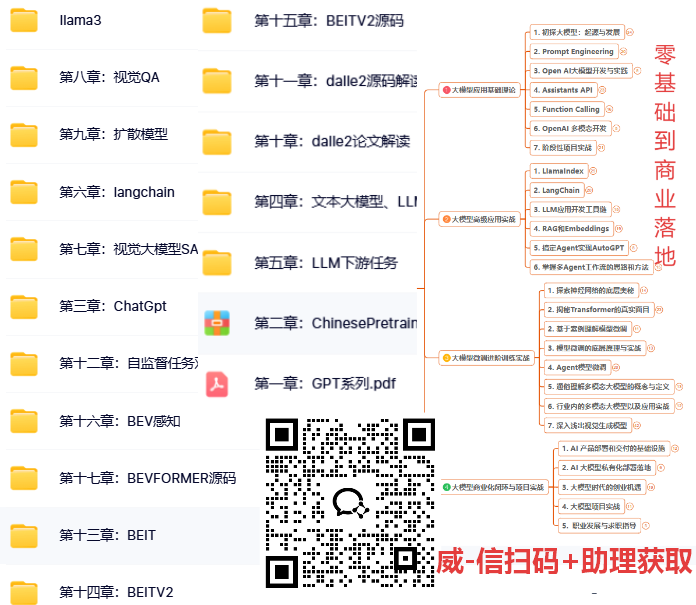
什么是强化学习(Reinforcement Learning)?解决"如何学会做决策"的问题
想象你是一个刚学会走路的孩子,站在一个陌生的房间里,想要到达门口。你不知道哪条路最好,也没有人告诉你标准答案。你只能:
-
尝试向前走 → 撞到桌子 → 感到疼痛(负反馈)
-
尝试绕过桌子 → 顺利前进 → 感到高兴(正反馈)
-
重复这个过程,逐渐学会避开障碍物,找到最短路径
这就是强化学习的核心思想:在没有标准答案的情况下,通过试错和反馈来学习最优的行为策略。
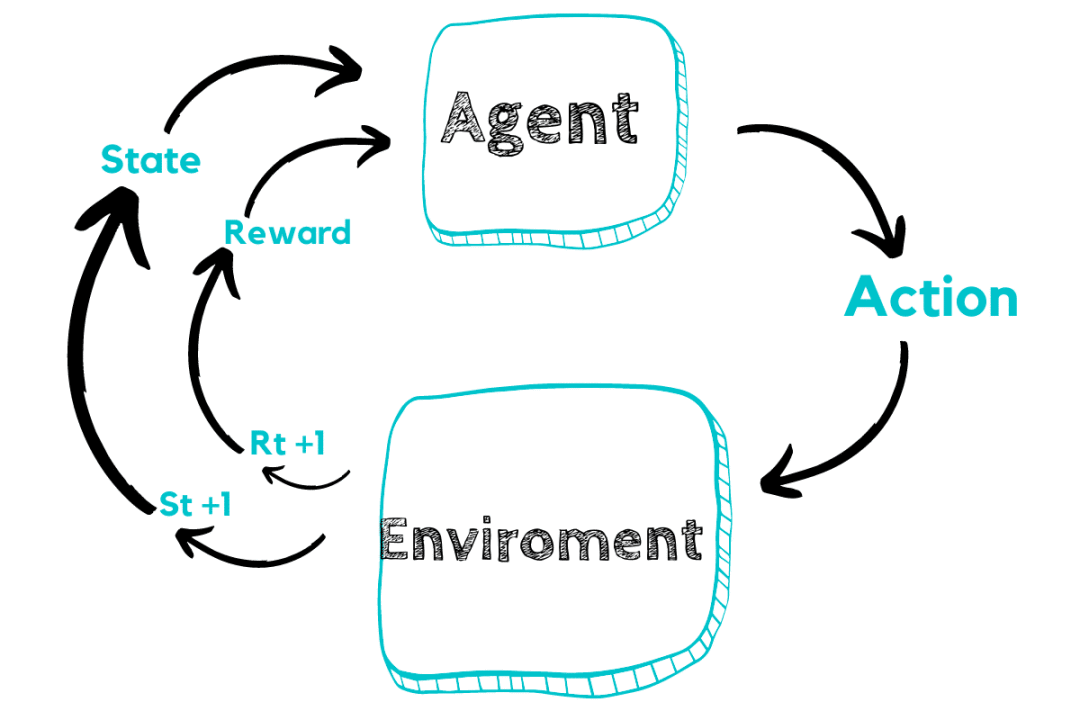
强化学习是一套学习方法论,它回答的是:
-
如何从错误中学习?
-
如何处理延迟的反馈?
-
如何平衡尝试新方法和使用已知好方法?
-
如何优化长期收益而不是短期收益?
什么是智能体(Agent)?解决"如何构建自主系统"的问题
现在换个角度。假设你要设计一个扫地机器人,它需要:
- 感知环境:用传感器检测房间布局、障碍物位置
- 做出决策:选择清扫路径,决定是否需要充电
- 执行动作:控制马达移动,启动吸尘装置
- 适应变化:当家具移动时调整策略
这个扫地机器人就是一个智能体。它是一个完整的系统架构,强调的是如何组织各个组件来实现自主运行。
智能体回答的是:
-
如何设计一个能自主运行的系统?
-
如何组织感知、决策、执行这些功能模块?
-
如何让系统有目标导向的行为?
-
如何让系统适应环境变化?
通过这两个例子,我们可以看出强化学习是一套学习方法论,智能体是一个完整的系统架构。
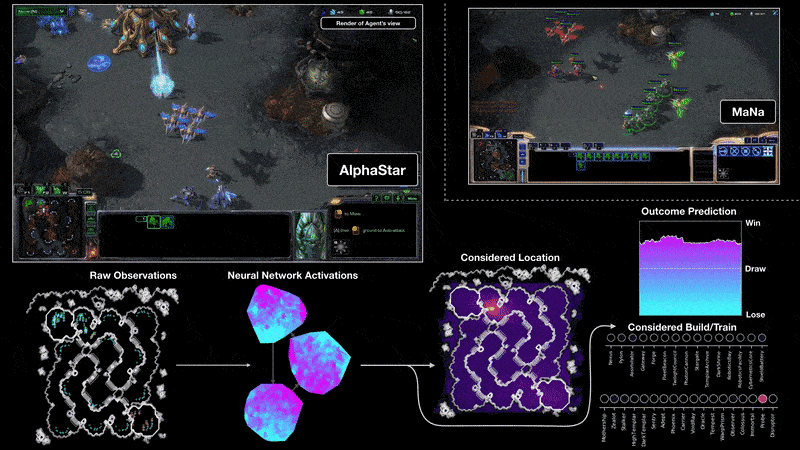
它们可以独立存在,也可以结合。当我们把强化学习嵌入到智能体架构中,就得到了强化学习智能体。例如:AlphaGo,AlphaStar
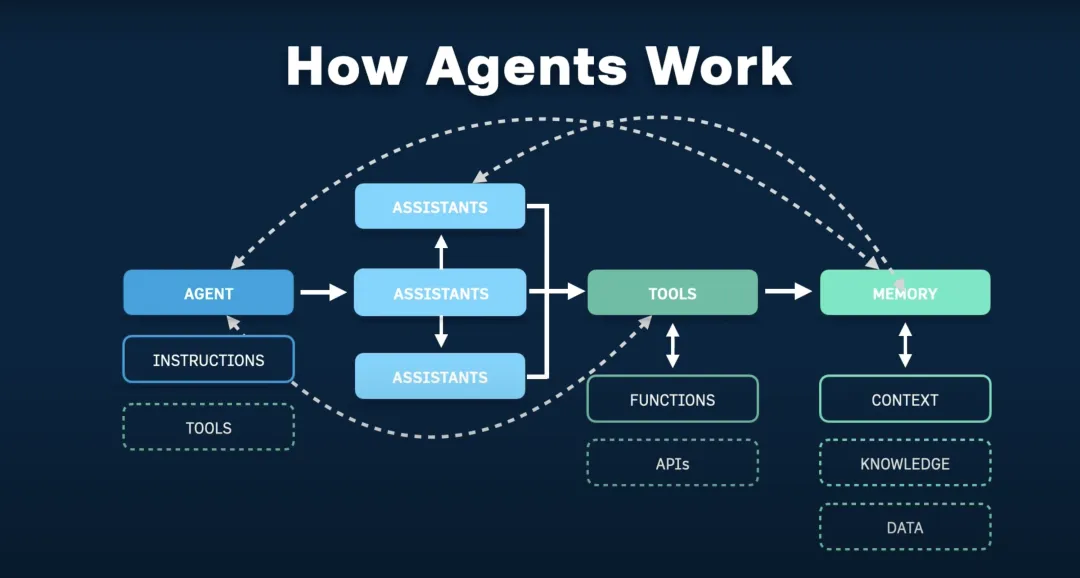
二、大语言模型智能体
随着ChatGPT、GPT-4等大语言模型的突破,AI领域出现了一种新的智能体构建方式:基于大语言模型的智能体(LLM-based Agents)。这种新范式正在重新定义我们对智能体的理解。
大语言模型智能体与传统智能体的差异是什么?
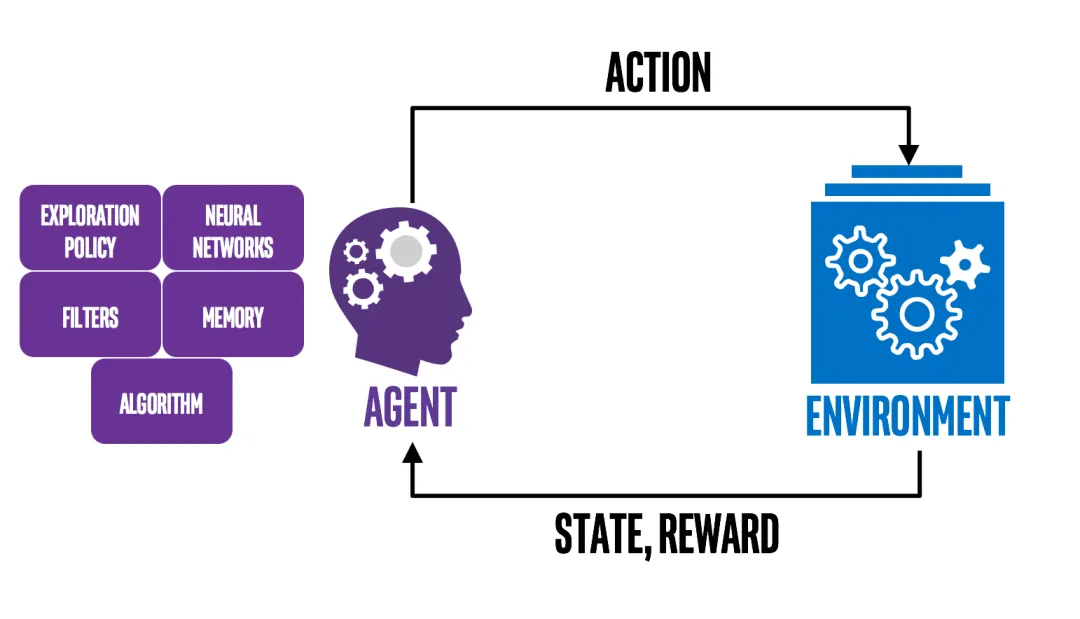
(1)传统智能体的构建方式
智能体系统
├── 感知模块(专门的传感器处理)
├── 决策模块(规则引擎或特定算法)
├── 执行模块(专门的执行器)
└── 学习模块(强化学习、监督学习等)
(2)大语言模型智能体的构建方式
LLM智能体系统
├── 核心:大语言模型(统一的认知引擎)
├── 输入处理:多模态信息转换为文本
├── 推理决策:基于语言的思维链推理
├── 工具调用:通过API连接外部世界
└── 输出转换:文本指令转换为具体行动
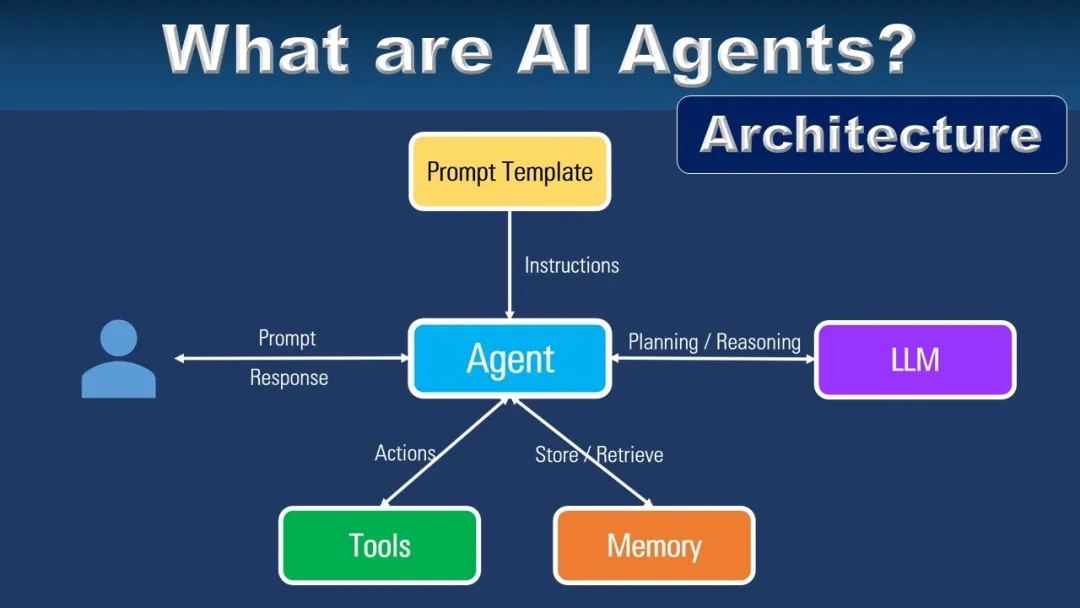
这两种智能体的根本差异在于,大语言模型智能体将语言作为通用接口。
LLM智能体是一个能够理解和生成人类语言的万能助手,主要有三种应用模式。
1. 对话式智能体(Conversational Agents)
以自然语言对话为主要交互方式应用:客服机器人、个人助理、教育辅导。
案例:智能学习助手
学生:"我不理解什么是Transformer架构,和RNN有什么区别?"
智能体:"简单来说:
- RNN像逐字读书,必须按顺序处理,效率低
- Transformer像同时看整页,通过注意力机制并行处理所有信息
核心优势:并行计算、更好捕捉长距离依赖关系。"
学生:"GPT是怎么训练的?"
智能体:"三个阶段:
1. 预训练:用大量文本学习语言规律
2. 指令微调:学习按人类指令行事
3. 强化学习:通过人类反馈优化输出
想动手实践吗?我可以安排从注意力可视化到mini-GPT实现的练习项目。"
2. 任务执行智能体(Task-Oriented Agents)
专注于完成特定任务应用:自动化办公、数据处理、内容生成
案例:营销文案生成器
输入:产品信息 + 目标受众 + 营销目标
处理:分析竞品 → 提取卖点 → 选择文案风格 → 生成多版本文案
输出:A/B测试用的不同风格文案 + 效果预期分析
3. 多智能体系统(Multi-Agent Systems)
多个LLM智能体协作完成复杂任务应用:软件开发、科研协作、决策支持
案例:AI软件开发团队
产品经理智能体:分析需求,制定产品规划
架构师智能体:设计系统架构,制定技术方案
开发者智能体:编写代码,实现功能模块
测试工程师智能体:设计测试用例,执行质量检查
项目经理智能体:协调进度,管理资源分配
在理解了传统强化学习智能体和基于大语言模型智能体的特点后,我们可以根据具体需求选择最适合的技术路径。
- 需要精确控制和实时反应 → 传统智能体架构
- 需要自然语言交互和快速开发 → LLM智能体
- 需要强大学习能力和长期优化 → 强化学习智能体
- 需要复杂推理和知识整合 → 混合架构智能体
需要注意的是,LLM智能体的出现并不意味着传统方法的淘汰,而是为我们提供了更丰富的工具箱,让我们能够根据不同的问题选择最合适的解决方案。


















 4204
4204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









