







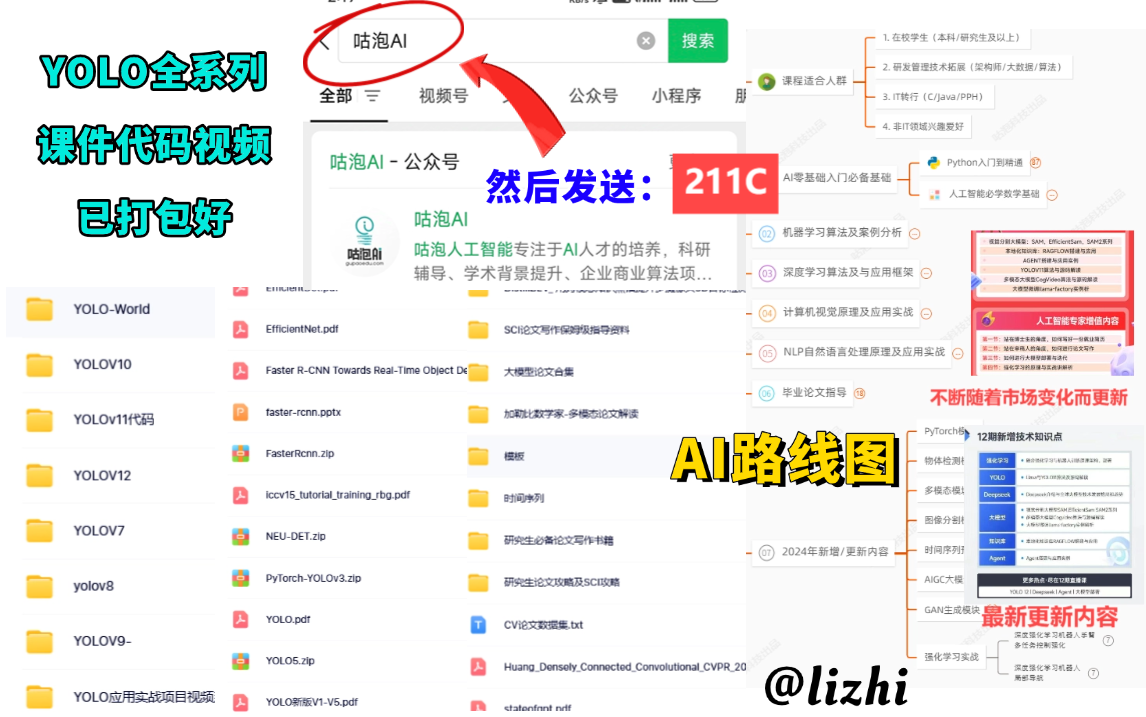
YOLO 系列作为目标检测领域的经典算法,其版本迭代(从 V1 到 V13)主要围绕精度、速度、泛化能力等方向优化,但 “新版本推出后旧版本仍被广泛使用” 是技术领域的常见现象,核心原因可归结为实际应用中 “适用性” 比 “最新性” 更重要。具体来说,YOLOv8 仍被广泛使用的原因包括以下几点:【YOLO学习资料+个人学习规划】
1. 稳定性与成熟度:经过充分验证的 “可靠选择”
YOLOv8 发布于 2023 年初,至今已经过近 2 年的大规模实际应用验证,其性能边界(如在不同场景下的精度、速度、对噪声 / 模糊的鲁棒性)、缺陷(如小目标检测短板、特定类别误检率)、调优方法(如数据增强策略、锚框调整技巧)都已被开发者充分掌握。
而 YOLOv13 作为较新版本(假设发布于 2024 年后),尚未经过足够多的工业级场景检验,可能存在未暴露的潜在问题(如极端场景下的稳定性、与特定数据分布的兼容性)。在对可靠性要求极高的领域(如自动驾驶、工业质检),“已知的稳定” 远比 “未知的新功能” 更重要。
2. 生态与工具链:完善的 “基础设施” 降低开发成本
YOLOv8 拥有极其成熟的生态体系:
- 工具链支持:官方提供了完整的训练、推理、部署工具(如 Ultralytics 库),并与主流部署框架(TensorRT、ONNX、OpenVINO 等)深度兼容,甚至针对边缘设备(如 NVIDIA Jetson、树莓派)有现成的优化方案。
- 社区资源:GitHub 上有大量基于 v8 的开源项目、预训练模型(覆盖行人、车辆、工业零件等数十类场景),Stack Overflow、优快云 等平台有海量问题解答,开发者遇到问题时能快速找到解决方案。
相比之下,YOLOv13 的生态仍在建设中:工具链可能不完善(如部署脚本缺失)、预训练模型少、社区讨论不足,会显著增加开发和调试的时间成本。
3. 迁移成本:“重新适配” 的代价高于 “性能提升”
大量企业和项目已基于 YOLOv8 完成全流程开发:
- 数据标注格式、训练 pipeline、模型评估指标已与 v8 绑定;
- 生产环境的部署代码(如 C++ 推理接口、硬件驱动适配)已稳定运行;
- 团队成员对 v8 的调优经验(如学习率调度、损失函数权重调整)已形成积累。
若迁移到 YOLOv13,需重新适配代码、调整训练参数、测试部署兼容性,甚至可能需要重新标注部分数据(因输入格式或预处理逻辑变化)。只有当 v13 的性能提升(如精度提高 5% 以上、速度提升 30% 以上)能覆盖迁移成本时,企业才会考虑升级。但多数场景下,v8 的性能已足够满足需求,升级的 “投入产出比” 过低。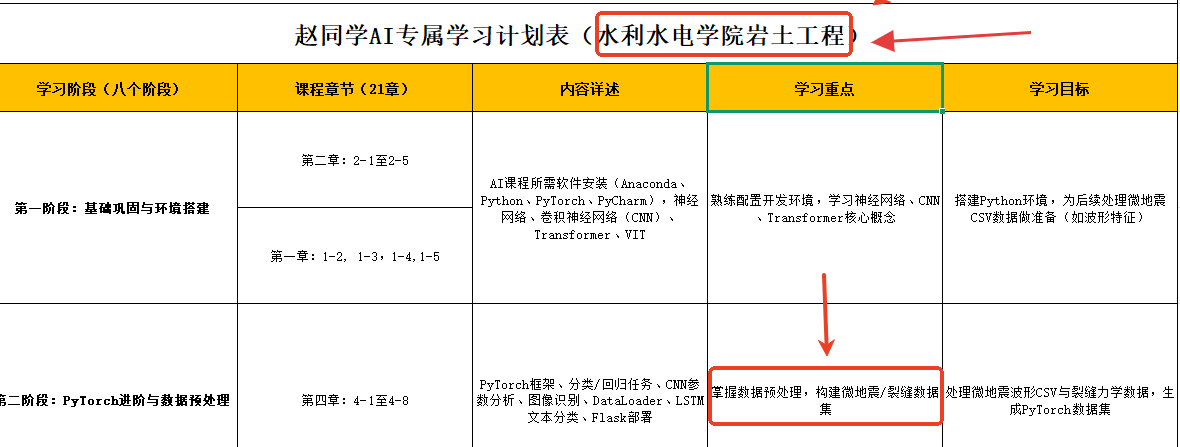
4. 性能需求匹配:“够用就好” 的实际场景逻辑
YOLO 的版本迭代通常聚焦于 “边际提升”(如小目标检测精度 + 2%、参数量 - 5%),但多数实际场景中,YOLOv8 的性能已能满足需求:
- 例如,在普通监控场景中,v8 的 “每秒 30 帧 + 95% 准确率” 已足够识别行人 / 车辆;
- 在移动端部署中,v8 的轻量版本(如 v8n)的速度和模型大小(<10MB)已适配低算力设备。
此时,v13 的 “理论提升”(如小目标精度 + 3%)在实际场景中可能无法转化为 “业务价值”(如监控系统漏检率无显著下降),自然缺乏升级动力。
5. 硬件与部署兼容性:旧设备更适配 “经过验证的模型”
工业场景中,硬件设备的更新速度往往慢于算法迭代:
- 许多企业的服务器、边缘设备仍是 2-3 年前的硬件(如 NVIDIA Tesla T4、Jetson Nano),这些设备对 YOLOv8 的优化(如算子支持、内存占用)已被充分验证;
- 而 YOLOv13 可能针对最新硬件(如 NVIDIA H100、AMD MI300)做了优化,在旧设备上可能出现兼容性问题(如算子不支持)或性能不达标(如推理速度反而比 v8 慢)。
总结
技术选型的核心是 “需求匹配” 而非 “追新”。YOLOv8 凭借稳定的性能、成熟的生态、低迁移成本,在多数场景中仍能高效满足需求;而 YOLOv13 的普及需要时间 —— 直到其生态完善、迁移成本降低,且在特定场景中展现出不可替代的优势(如极端小目标检测、超低延迟部署),才会逐步取代 v8 成为主流。这一过程类似 “Windows 10 仍被广泛使用,而 Windows 11 的普及需要数年”,本质是技术迭代与实际应用节奏的差异。
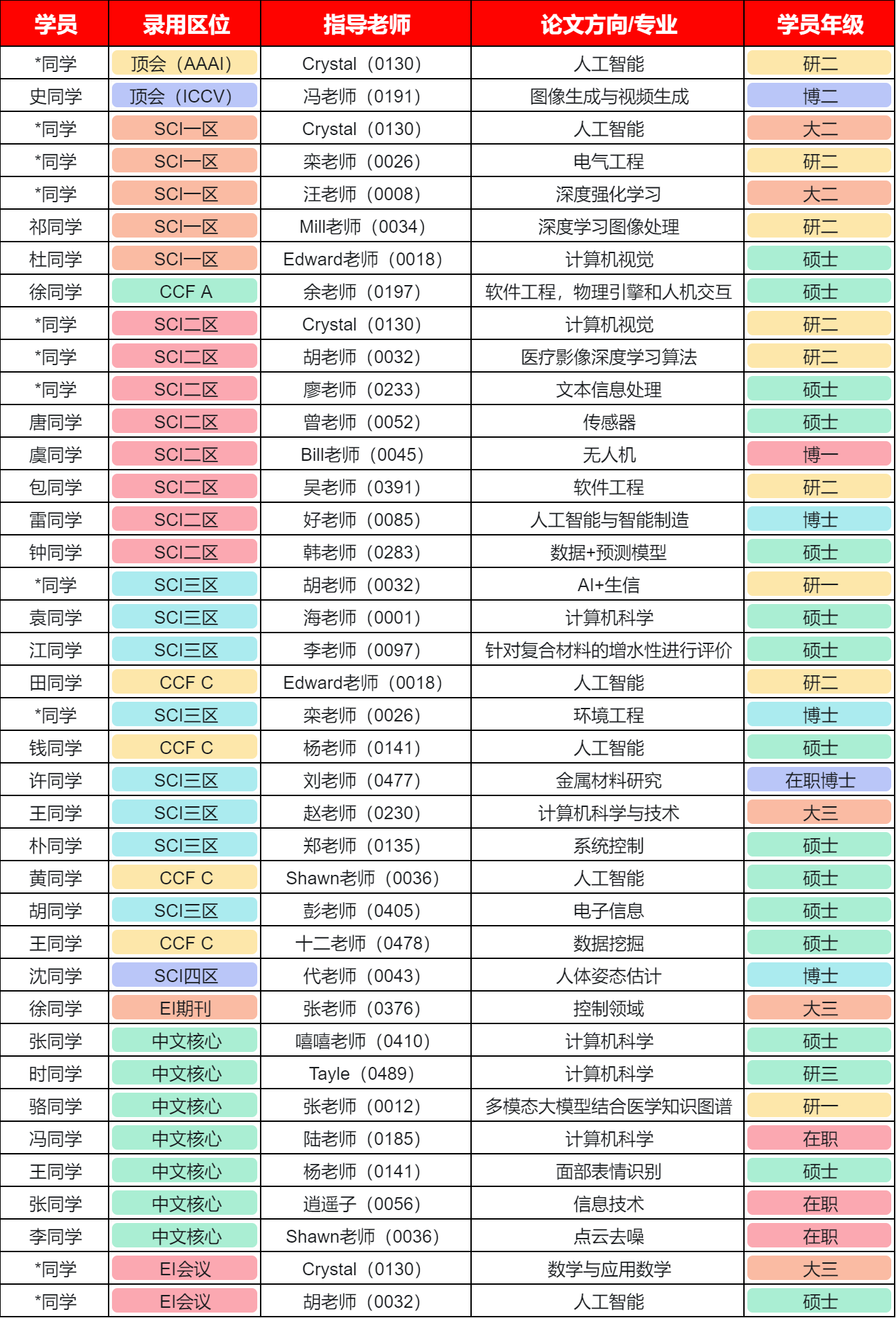
近期SCI顶会顶刊中稿的同学


















 9720
9720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









