 深度学习车道线检测技术全解析
深度学习车道线检测技术全解析








一、车道线检测的核心价值
车道线检测是自动驾驶和辅助驾驶(ADAS)的基础任务,其目标是通过图像或视频识别道路中的车道边界,为车辆提供路径规划和方向控制的关键信息。传统方法(如边缘检测、霍夫变换)在复杂场景(阴影、雨天、车道线磨损)下鲁棒性较差,而深度学习通过自适应特征提取和端到端学习,显著提升了检测精度和环境适应性。
论文有救了?翻遍B站精心整理的【车道线检测实战】教程,基于深度学习的车道线检测算法论文解读及从车道线检测入门OpenCV!
二、深度学习车道线检测的技术路径
1. 基于语义分割的方法
- 核心思想:将车道线检测转化为像素级语义分割任务,为图像中每个像素判断是否属于车道线。
- 典型模型:
- U-Net:编码器 - 解码器结构,通过跳跃连接保留细节,适合车道线的精细分割。
- DeepLab:采用空洞卷积(Atrous Convolution)扩大感受野,捕捉长距离车道线特征。
- ERFNet:轻量级网络,通过高效残差块设计,平衡精度与实时性(适合嵌入式设备)。
- 优势:对复杂车道线(弯道、分叉)适应性强,可同时检测多条车道。
- 案例:LaneNet 模型通过嵌入向量(Embedding Vector)将分割结果聚类为不同车道线。
2. 基于回归的方法
- 核心思想:直接预测车道线的坐标参数(如多项式系数),将问题转化为回归任务。
- 典型模型:
- PolyLaneNet:通过 CNN 直接回归车道线的多项式参数,输出车道线的数学表达式。
- SCNN(Spatial CNN):引入空间卷积,模拟车道线的连续性,增强长距离依赖建模。
- 优势:计算效率高,适合实时场景(如高速公路直线车道)。

3. 基于锚点(Anchor-based)的方法
- 核心思想:借鉴目标检测中的锚点机制,预设车道线形状,通过分类和回归确定车道线位置。
- 典型模型:
- LaneATT:结合注意力机制,聚焦关键区域(如车道线拐点),提升复杂场景检测能力。
- Ultra-Fast-Lane-Detection:通过行方向锚点预测,大幅减少计算量,实现超实时检测(300+ FPS)。
4. 新兴技术:Transformer 架构
- 核心思想:利用自注意力机制(Self-Attention)建模车道线的全局依赖关系。
- 案例:LSTR(Lane-Structure-Transformer) 通过 Transformer 捕捉车道线的长距离结构,在弯曲车道检测中表现优异。
三、技术流程与关键步骤
1. 数据预处理
- 图像增强:亮度调整、对比度增强、噪声过滤,提升模型对不同光照的适应性。
- 透视变换:将图像转换为鸟瞰图(Bird's Eye View),简化车道线的几何表示。
- 标注方法:人工标注车道线像素坐标或关键点,常用数据集包括 KITTI、CULane、TuSimple。
2. 模型训练与优化
- 损失函数:
- 分割任务:交叉熵损失(Cross-Entropy Loss)、Dice 损失(处理类别不平衡)。
- 回归任务:均方误差(MSE)、Huber 损失(对异常值鲁棒)。
- 数据增强:旋转、缩放、添加雨雪噪声,模拟多样化场景。
3. 后处理
- 聚类与平滑:对分割结果进行连通域分析,通过滑动平均或卡尔曼滤波消除抖动。
- 逻辑校验:基于车道线物理约束(如平行、曲率连续)过滤错误检测。

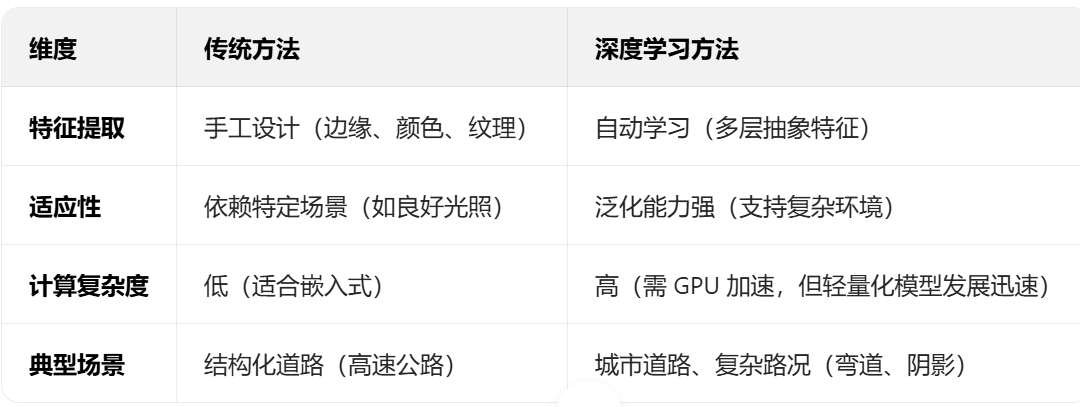
四、传统方法与深度学习方法对比
 五、应用场景与挑战
五、应用场景与挑战
1. 核心应用场景
- 高速公路自动驾驶:特斯拉 Autopilot、百度 Apollo 的车道保持功能。
- 城市道路辅助驾驶:应对路口、环岛、无明确车道线的复杂场景。
- 特殊环境:雨天、夜间、隧道等低光照条件下的安全驾驶。
2. 技术挑战
- 环境鲁棒性:阴影、积水、车道线磨损导致检测失效。
- 实时性要求:自动驾驶需达到 30 FPS 以上,轻量化模型设计(如 MobileNet、ShuffleNet)是关键。
- 多车道与复杂结构:高速公路分叉、城市道路多车道并行时的语义理解。
- 无监督 / 半监督学习:减少对大规模标注数据的依赖(当前主流模型仍需数万张标注图像)。
六、典型数据集与评估指标
1. 常用数据集
- TuSimple:高速公路场景,包含 3626 张训练图像,侧重直线车道检测。
- CULane:城市道路场景,包含 13323 张图像,覆盖拥堵、阴影、弯道等复杂工况。
- KITTI Road:自动驾驶基准数据集,包含标注的车道线和路况信息。
2. 评估指标
- 准确率(Accuracy):正确检测的车道线像素占比。
- 召回率(Recall):实际车道线被检测到的比例。
- F1 分数:准确率与召回率的调和平均。
- 实时性(FPS):模型每秒处理的图像帧数。
七、未来发展趋势
- 多传感器融合:结合激光雷达(LiDAR)、毫米波雷达(Radar)提升恶劣天气下的可靠性。
- 轻量化与边缘计算:通过模型压缩(剪枝、量化)和神经架构搜索(NAS),适配车载芯片(如 NVIDIA Orin、地平线征程系列)。
- 动态环境理解:结合车道线与交通标志、障碍物的联合建模,实现更全面的道路语义理解。
- 无监督学习与迁移学习:利用仿真数据或跨域数据(如合成图像到真实场景)降低标注成本。
八、实践案例:特斯拉车道线检测技术
特斯拉 FSD(Full Self-Driving)系统采用多任务神经网络,通过同一模型同时处理车道线检测、车辆识别、行人预测等任务。其车道线检测模块具有以下特点:
- 多尺度特征融合:结合浅层网络的细节信息和深层网络的语义信息,捕捉不同距离的车道线。
- 时序信息利用:通过递归神经网络(RNN)或 3D 卷积,融合连续帧的信息,提升动态场景稳定性。
- 端到端优化:直接将摄像头图像映射到方向盘控制信号,减少中间处理环节的误差累积。
总结
基于深度学习的车道线检测已从实验室研究走向实际应用,但仍需在鲁棒性、实时性和泛化能力上持续突破。随着自动驾驶技术的发展,车道线检测将与更多环境感知技术融合,成为智能驾驶系统的关键基础模块。
有以下论文写作问题的可以扫下方名片详聊
前沿顶会、期刊论文、综述文献浩如烟海,不知道学习路径,无从下手?
没时间读、不敢读、不愿读、读得少、读不懂、读不下去、读不透彻一篇完整的论文?
CVPR、ICCV、ECCV、ICLR、NeurlPS、AAAI……想发表顶会论文,找不到创新点?
读完论文,仍旧无法用代码复现……
然而,导师时常无法抽出时间指导,想写论文却无人指点…

















 3960
3960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









