







南科大机器人控制与学习实验室(CLEAR Lab),致力于人形机器人控制,强化学习,与具身智能等方面的研究。
传统强化学习的痛点:奖励函数设计调试耗时费力
在足式机器人控制领域,强化学习(RL)尽管能够生成灵活且鲁棒的控制策略,但其训练过程高度依赖于奖励工程(Reward Engineering)。工程师通常需要设计数十个奖励项,并通过大量试验不断调节各项权重,才能引导策略学习出期望的运动行为。这一过程不仅耗时费力,而且所设计的奖励项往往具有任务或平台的特定性,难以在不同机器人之间迁移,导致每当引入新的硬件平台时,往往需要重新构建奖励体系。

不只有奖励,还有约束
韩国KAIST的团队在论文《Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion》中提出了一种新型的足式机器人强化学习框架:将物理限制直接建模为约束(Constraint),而非通过奖励项的软惩罚间接控制,并且通过带约束强化学习方法(IPO)进行策略训练。这一方法带来了以下的优势:
-
• 减轻奖励工程任务量:仅需3个核心奖励(如速度跟踪、能耗),其余关节角度、扭矩限制等均转为约束,且约束无需调试权重,大幅简化调参。
-
• 策略安全性提升:约束的物理意义明确,工程师可直观地设定安全边界,同时,将关节位置、速度等物理限制设计成约束形式,能够更有效地避免违反限制。
-
• 跨机器人通用性:关节约束可直接从机器人URDF文件读取,同一框架能适配不同质量/形态的足式机器人(见图2)。

约束强化学习算法对比
约束强化学习的潜力引起了学界的关注。在论文《Evaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion》中,ETH Zurich团队对比了五种主流的约束强化学习算法,并以四轮足机器人的运动控制任务为实验测试基础,实验结论如下:
-
• N-P3O算法胜出:在对比的几种算法中,N-P3O在设置中需要调整的参数最少,且能够有效减少约束违例。尽管N-IPO算法在奖励方面表现最好,并且约束违例表现相似,但其对阈值参数的高度敏感性使其在实验中显得不够适用。
-
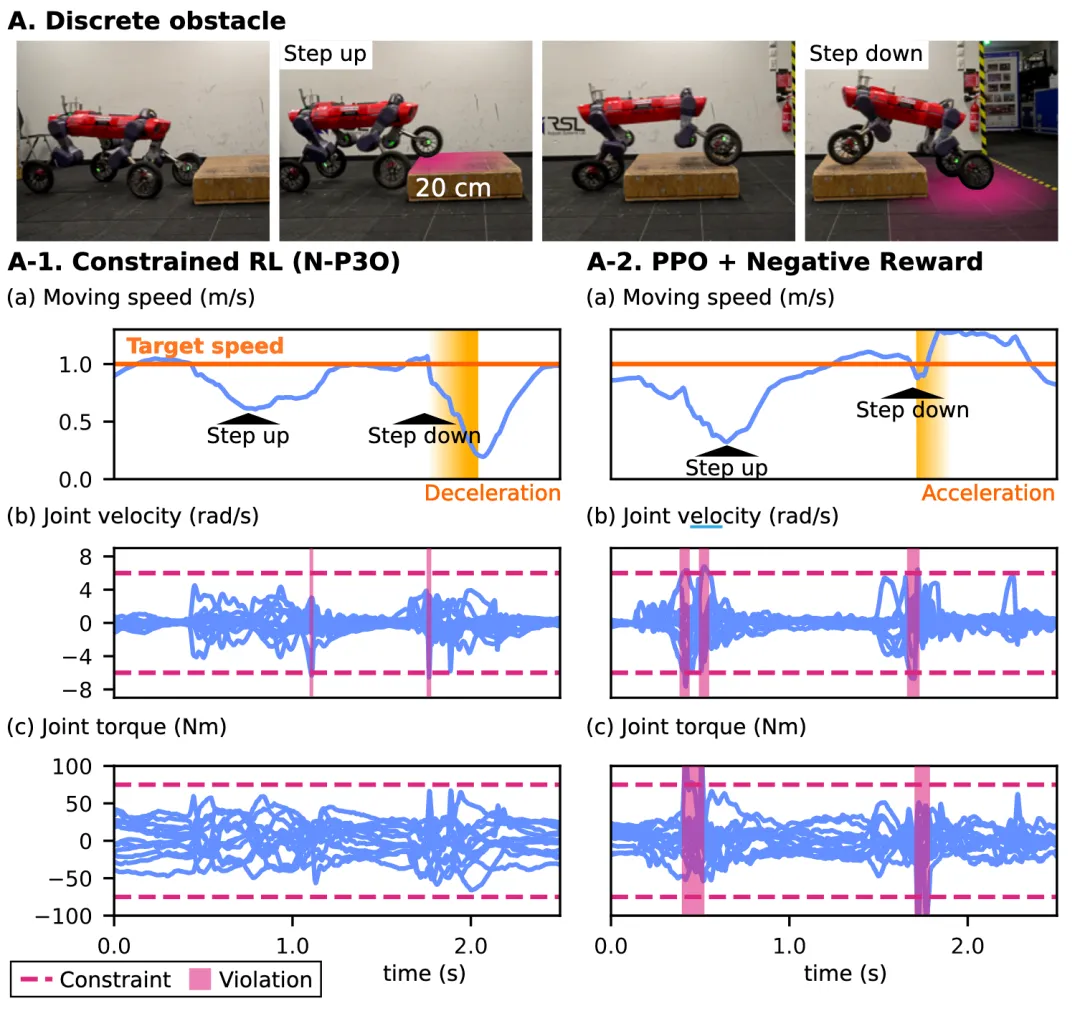
• 真实机器人验证:采用约束策略的机器人在跨越20cm障碍时,会主动降低速度以进行缓冲,避免过快冲击。而传统PPO则因奖励驱动机制导致机器人全力冲刺,从而增加了关节超限的风险(见图3)。
强化学习资源+AI学习路线可以下图扫码获取
资料包:一、 人工智能学习路线及大纲
二、计算机视觉OpenCV【视频+书籍】
三、AI基础+ 深度学习 + 机器学习 +NLP+ 机器视觉 教程
四、李飞飞+吴恩达+李宏毅合集
五、自动驾驶+知识图谱等资料
六、人工智能电子书合集【西瓜书、花书等】
七、各阶段AI论文攻略合集【论文带读/代码指导/本硕博/SCI/EI/中文核心】

















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









