







我们每个人都在跟上 LLM 研究社区的步伐。似乎每天都会带来一个新的最先进的模型,打破以前的基准。如果您曾经想过是什么带来了这种创新的加速 — 基本上是研究人员能够在超大规模上进行训练和验证 — 这一切都归功于并行性。
如果您还没听说过,5D 并行这个术语最早是由 Meta AI 的论文 The Llama 3 Herd of Models 推广的。传统上,它是指结合数据、张量、上下文、管道和专家并行的技术。然而,最近,另一种范例 ZeRO (Zero Redundancy Optimizer) 出现了,它通过减少分布式计算中的冗余来优化内存。每种技术都解决了训练挑战的不同方面,当它们结合在一起时,它们能够处理具有数十亿(甚至数万亿)参数的模型。
本文的重点是提供模型作的高级组织的概念清晰度,以及 PyTorch 中的一些示例。并行性的这些基本原则是当今超大规模(想想数千万的每日活跃用户)加速迭代和部署的关键驱动因素。pytorch安装入门到实战自学教程可扫下图无偿自取
1. 数据并行
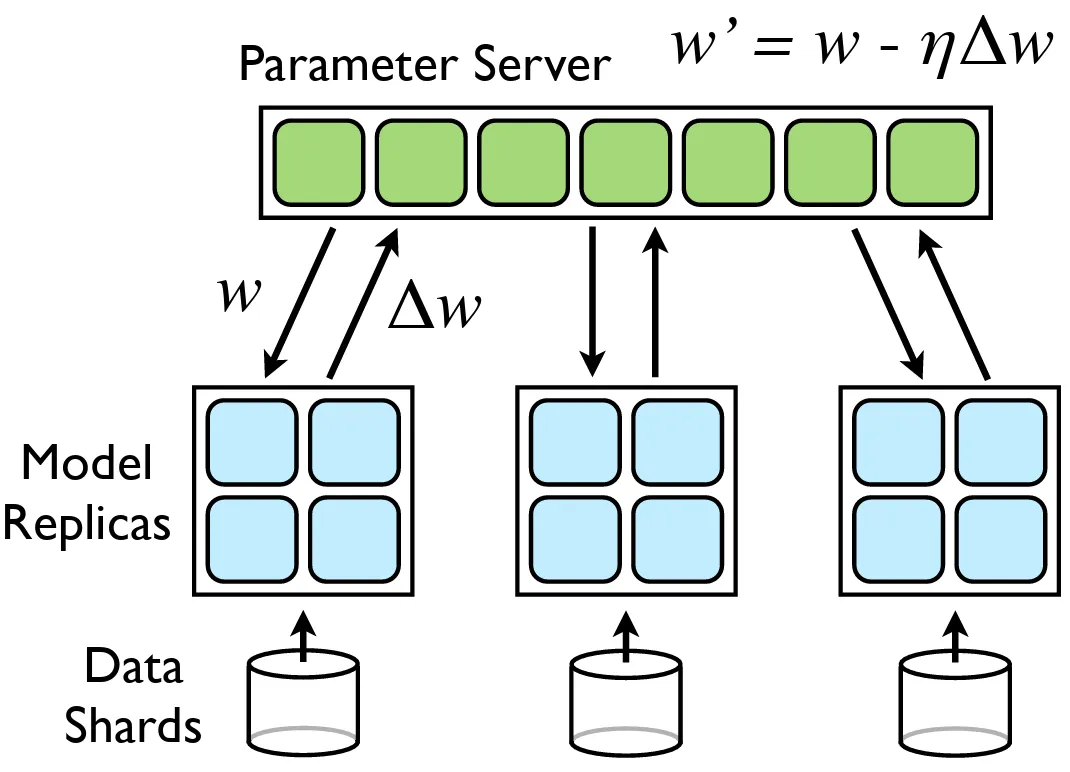
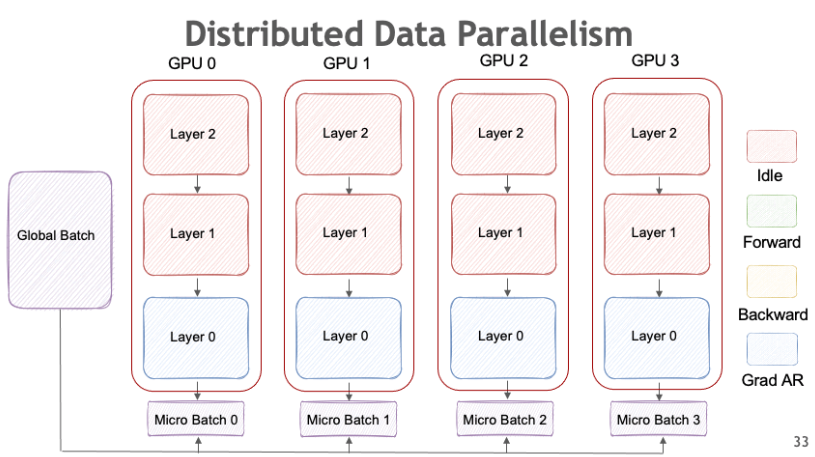
数据并行是最直接和广泛采用的并行技术。它涉及创建同一模型的多个副本,并在不同的数据子集上训练每个副本。在本地计算梯度后,梯度被聚合(通常通过 all-reduce作)并用于更新模型的所有副本。
当模型本身适合单个 GPU 的内存,但数据集太大而无法按顺序处理时,此方法特别有效。
PyTorch通过& (DDP)模块提供对数据并行性的内置支持。其中,DDP 是广泛首选的,因为它为多节点设置提供了更好的可扩展性和效率。NVIDIA 的 NeMo 框架提供了一个非常酷的例证,说明了它是如何工作的 —torch.nn.DataParalleltorch.nn.parallel.DistributedDataParallel
此实现的示例可能如下所示:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义你的模型
model = nn.Linear(10, 1)
# 用 DataParallel
包装模型 model = nn.DataParallel(model)
# 将模型移动到 GPU
中 model = model.cuda()
# 定义损失和优化器
准则 = nn.MSELoss()
optimizer = optim 的 Optimizer 中。SGD(model.parameters(), lr=0.01)
# 虚拟数据
输入 = torch.randn(64, 10).cuda()
targets = torch.randn(64, 1).cuda()
# 正向传递
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传递和优化
loss.backward()
optimizer.step()关键要点
- 小型模型/大型数据集 — 仅当模型本身适合单个 GPU 的内存(而不是数据集)时,此方法才有效。
- Model Replication (模型复制) — 每个 GPU 都保存模型参数的相同副本。
- Mini-Batch Splitting (小批量拆分) — 输入数据在 GPU 之间进行划分,确保每个设备处理单独的 min-batch。
- 梯度同步 — 在向前和向后传递后,梯度将在 GPU 之间同步以保持一致性。
优点和考虑
- 简单高效 — 易于实施,与现有代码库直接集成,并且非常适合大型数据集。
- 通信开销 — 梯度同步期间的通信开销可能成为大规模系统的瓶颈。
2. 张量并行
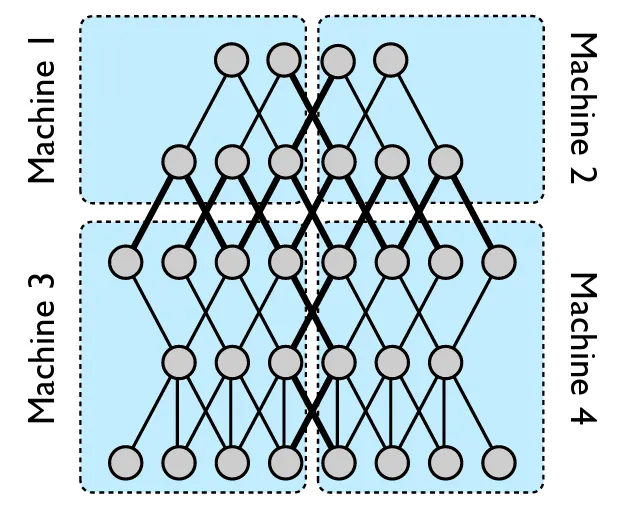
数据并行侧重于拆分数据,而张量并行(或模型并行)将模型本身划分到多个设备。此方法对大权重矩阵和中间张量进行分区,允许每个设备处理一小部分计算。张量并行不是在每个 GPU 上复制整个模型(如数据并行),而是将模型的层或张量划分到不同设备。每个设备都负责计算模型的一部分向前和向后传递。
该技术对于训练无法放入单个 GPU 内存的超大型模型(尤其是基于 transformer 的架构)特别有用。
虽然 PyTorch 不提供对张量并行性的直接开箱即用支持,但使用 PyTorch 灵活的张量作和分布式通信基元可以轻松实现自定义实现。但是,如果您想要更强大的解决方案,DeepSpeed 和 Megatron-LM 等框架扩展了 PyTorch 以启用此功能。张量并行实现的简单片段如下所示 —
import torch
import torch.distributed as dist
def tensor_parallel_matmul(a, b, devices):
# a 按行划分,b 在设备
之间共享 a_shard = a.chunk(len(devices), dim=0)
results = []
for i, dev in enumerate(devices):
a_device = a_shard[i].to(dev)
b_device = b.to(dev)
results.append(torch.matmul(a_device, b_device))
# 连接每个设备
的结果 return torch.cat(results, dim=0)
# 用法示例:
a = torch.randn(1000, 512) # 假设这个张量对于一个 GPU
来说太大了 b = torch.randn(512, 256)
devices = ['cuda:0', 'cuda:1']
result = tensor_parallel_matmul(a, b, devices)关键要点
- 较大的模型 — 当模型无法容纳单个 GPU 的内存时,此方法非常有效。
- 分片权重 — 张量并行不是在每个设备上复制完整模型,而是对模型的参数进行切片。
- Collective Computation — 向前和向后传递跨 GPU 集体执行,需要仔细编排以确保正确计算张量的所有分量。
- 自定义作 — 通常,使用专用的 CUDA 内核或第三方库来有效地实现张量并行性。
优点和考虑
- 内存效率 — 通过拆分大型张量,您可以解锁训练超过单个设备内存的模型的能力。它还显著减少了矩阵运算中的延迟。
- 复杂性 — 设备之间所需的协调会带来额外的复杂性。当扩展到两个 GPU 以上时,开发人员必须仔细管理同步。手动分区导致的潜在负载不平衡,以及为避免 GPU 长时间空闲而进行的设备间通信是这些实现中的常见问题。
- 框架增强功能— Megatron-LM 等工具为张量并行性设定了标准,许多此类框架与 PyTorch 无缝集成。但是,集成并不总是那么简单。
肝了3个月的工业级PyTorch环境配置到项目部署学习路线!UNet+YOLOv11源码debug,看完直接怼简历!(气温预测/图像识别)
3. 上下文并行
上下文并行通过针对输入数据的上下文维度来采用不同的方法,它在基于序列的模型(如 transformers)中尤其有效。主要思想是划分长序列或上下文信息,以便同时处理不同的部分。这允许模型处理更长的上下文,而不会占用大量内存或计算能力。这种方法在需要一起训练多个任务的情况下特别有用,例如在多任务 NLP 模型中。
与张量并行类似,PyTorch 本身也不支持上下文并行。但是,创造性地使用数据重组使我们能够有效地管理长序列。想象一下,有一个必须处理长文本的 transformer 模型 — 序列可以分解成更小的片段,并行处理,然后合并。
下面显示了如何在自定义 transformer 块中拆分 context 的示例。在此示例中,该模块可能会并行处理长序列的不同 segment,然后合并输出以进行最终处理。
import torch
import torch.nn as nn
class ContextParallelTransformer(nn.模块):
def __init__(self, d_model, nhead, context_size):
super(ContextParallelTransformer, self).__init__()
self.context_size = context_size
self.transformer_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead)
def forward(self, x):
# x shape: [batch, seq_len, d_model]
batch, seq_len, d_model = x.size()
assert seq_len % self.context_size == 0,
“序列长度必须能被 context_size 整除”
# 将序列维度划分为segments
segments segments = x.view(batch, seq_len // self.context_size,
self.context_size, d_model)
# 使用循环或并行映射
并行处理每个段 processed_segments = []
for i in range(segments.size(1)):
segment = segments[:, i, :, :]
processed_segment = self.transformer_layer(
segment.transpose(0, 1))
processed_segments.append(processed_segment.transpose(0, 1))
# 将处理后的 segment 连接回完整序列
return torch.cat(processed_segments, dim=1)
# 用法示例:
model = ContextParallelTransformer(d_model=512, nhead=8, context_size=16)
# [batch, sequence_length, embedding_dim]
input_seq = torch.randn(32, 128, 512)
output = model(input_seq)关键要点
- Sequence Division (序列划分) – 对 sequence 或 context 维度进行分区,从而支持对数据的不同段进行并行计算。
- 长序列的可扩展性 — 这对于处理极长序列的模型特别有用,因为在这种模型中,一次性处理整个上下文既不可能又效率低下。
- 注意力机制 — 在 transformer 中,将注意力计算划分为多个段允许每个 GPU 处理序列的一部分及其相关的自我注意力计算。
优点和考虑
- 高效的长序列处理 — 通过将长上下文划分为并行段,模型可以处理广泛的序列,而不会占用大量内存资源。
- 顺序依赖关系 — 必须特别注意跨越上下文段边界的依赖关系。可能需要使用重叠区段或其他聚合步骤等技术。
- 新兴领域 — 随着研究的继续,我们预计会出现更多标准化的工具和库,专门促进 PyTorch 中的上下文并行。
4. 管道并行
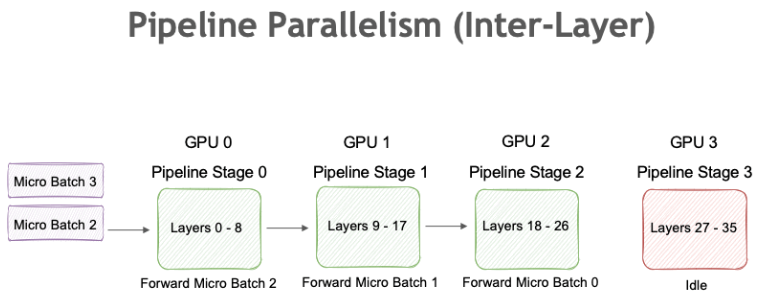
管道并行引入了将神经网络划分为多个连续阶段的概念,每个阶段都在不同的 GPU 上进行处理。当数据流经网络时,中间结果从一个阶段移动到下一个阶段,类似于流水线。这种交错执行允许重叠的计算和通信,从而提高整体吞吐量。
值得庆幸的是,PyTorch 确实有一个开箱即用的 API 来支持这一点,称为 USING 该 API 可以很容易地创建分段模型。API 会自动将顺序模型分区为流经指定 GPU 的微批次。Pipe
如何使用此 API 的一个简单示例是:
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
# 定义模型
的两个连续段 segment1 = nn.顺序 (
nn.线性(1024, 2048),
nn.ReLU(),
nn.线性(2048, 2048)
)
segment2 = nn.顺序 (
nn.线性(2048, 2048),
nn.ReLU(),
nn.Linear(2048, 1024)
)#
使用 Pipe
# 组合段# 如果提供设备分配
model = nn,则跨设备的模块放置由 Pipe
# 自动处理。Sequential(segment1, segment2)
model = Pipe(model, chunks=4)
# 现在,当你通过模型传递数据时,微批处理会以流水线的方式处理
# 。
inputs = torch.randn(16, 1024)
outputs = model(inputs)import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
# 定义模型段
segment1 = nn.顺序 (
nn.线性(1024, 2048),
nn.ReLU(),
nn.线性(2048, 2048)
)
segment2 = nn.顺序 (
nn.线性(2048, 2048),
nn.ReLU(),
nn.Linear(2048, 1024)
)
# 使用 Pipe
model = nn 将管段合并为一个模型。Sequential(segment1, segment2)
# 将模型拆分为遍历设备的微批次 'cuda:0'
# 和 'cuda:1'model
= Pipe(model, devices=['cuda:0', 'cuda:1'], chunks=4)
# 模拟输入批量
输入 = torch.randn(16, 1024).to('cuda:0')
outputs = model(inputs)关键要点
- Staged Computation (分阶段计算) – 模型被分割为一系列阶段(或“管道”)。每个阶段都分配给不同的 GPU。
- 微批处理 — 不是一次通过一个阶段给大批次,而是将批次分成多个微批次,连续流经管道。
- 提高吞吐量 — 通过确保所有设备同时工作(即使在不同的微批处理上),管道并行性可以显著提高吞吐量。
优点和考虑
- 资源利用率 — 管道并行性可以通过重叠不同阶段的计算来提高 GPU 利用率。
- 延迟与吞吐量权衡 — 虽然吞吐量增加,但由于引入的管道延迟,延迟可能会略有影响。
- 复杂调度 — 有效的微批处理调度和负载平衡对于实现跨阶段的最佳性能至关重要。
5. 专家并行
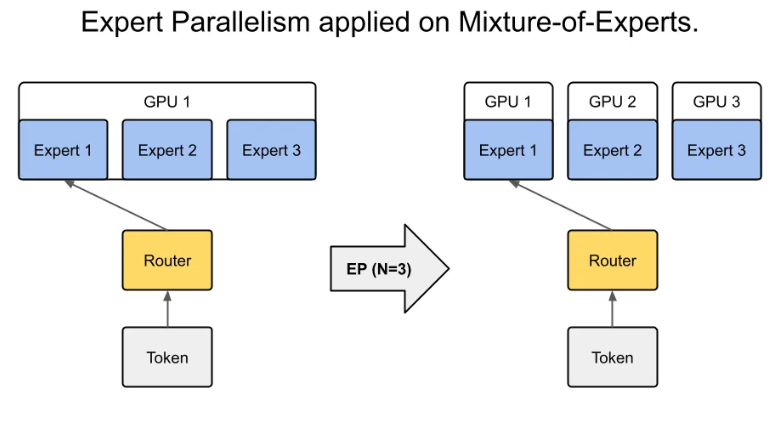
专家并行是一种受专家混合 (MoE) 模型启发的技术,旨在扩展模型容量,同时保持计算成本可控。在这种范式中,模型由多个专门的 “专家” 组成,即通过门控机制为每个输入选择性地激活的子网络。只有一小部分专家参与处理特定样本,从而允许巨大的模型容量,而不会相应地增加计算开销。
同样,PyTorch 没有为此提供直接的开箱即用解决方案,但是,它的模块化设计支持创建自定义实现。该策略通常涉及定义一组 Expert 层以及确定要激活哪些 Expert 的门。
在生产中,专家并行通常与其他并行策略结合使用。例如,您可以同时使用数据和专家并行性来同时处理大型数据集和大量模型参数,同时有选择地将计算路由给适当的专家。如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.模块):
def __init__(self, input_dim, output_dim):
super(Expert, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
返回 F.relu(self.fc(x))
class MoE(nn.模块):
def __init__(self, input_dim, output_dim, num_experts, k=2):
super(MoE, self).__init__()
self.num_experts = num_experts
self.k = k # 每个示例
要使用的智能系统数量 self.experts = nn.ModuleList([Expert(input_dim, output_dim)
for _ in range(num_experts)])
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
# x shape: [batch, input_dim]
gate_scores = self.gate(x) # [batch, num_experts]
# 为每个输入
选择top-k专家 topk = torch.topk(gate_scores, self.k, dim=1)[1]
outputs = []
for i in range(x.size(0)):
expert_output = 0
for idx in topk[i]:
expert_output += self.experts[idx](x[i])
outputs.append(expert_output / self.k)
return torch.stack(outputs)
# 用法示例:
batch_size = 32
input_dim = 512
output_dim = 512
num_experts = 4
model = MoE(input_dim, output_dim, num_experts)
x = torch.randn(batch_size, input_dim)
output = model(x)关键要点
- Mixture-of-Experts — 每个训练样本仅使用专家子集,从而大大减少了每个样本所需的计算量,同时保持了非常大的整体模型容量。
- 动态路由 — 门控功能动态决定哪些专家应处理每个输入令牌或数据段。
- 专家级别的并行性 — 专家可以分布在多个设备上,允许并行计算并进一步减少瓶颈。
优点和考虑
- 可扩展的模型容量 — Expert 并行性使您能够构建具有大量容量的模型,而无需线性增加每个输入的计算量。
- 高效计算 — 通过为每个输入仅处理选定的专家子集,您可以实现高计算效率。
- 路由复杂性 — 门控机制至关重要。设计不佳的路由会导致负载不平衡和训练不稳定。
- 研究前沿 — 专家并行性仍然是一个活跃的研究领域,正在进行的研究旨在改进设门方法和专家之间的同步。
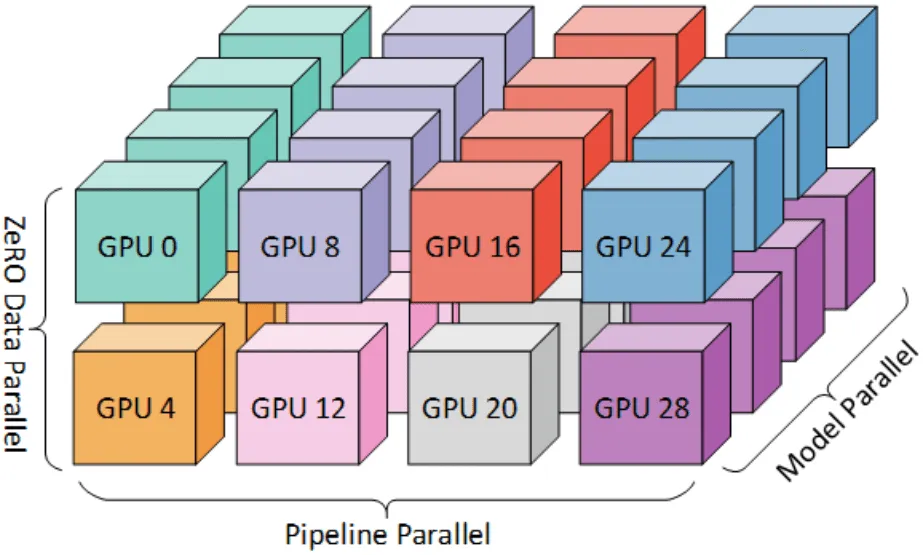
6. ZeRO:零冗余优化器
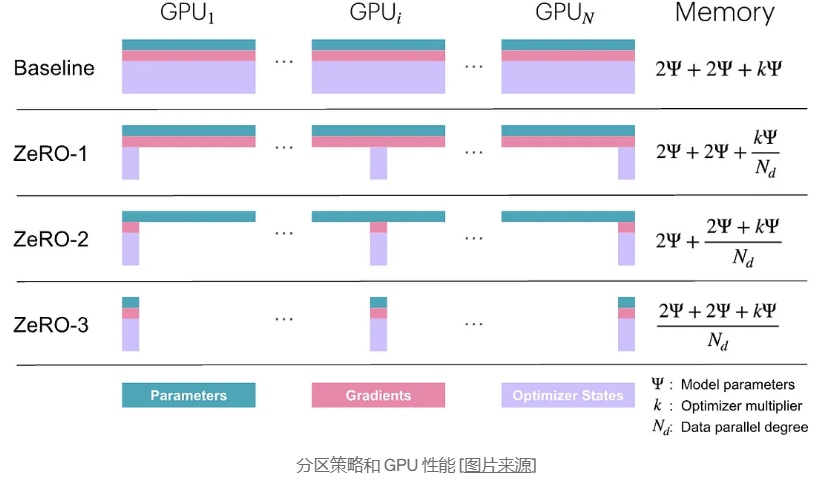
ZeRO 是 Zero Redundancy Optimizer 的缩写,代表了大规模训练内存优化的突破。ZeRO 作为 DeepSpeed 库的一部分开发,通过对优化器状态、梯度和模型参数进行分区来解决分布式训练的内存限制。从本质上讲,ZeRO 消除了每个 GPU 保存所有内容副本时出现的冗余,从而节省了大量内存。
它的工作原理是在所有参与的设备之间划分优化器状态和梯度的存储,而不是复制它们。这种策略不仅可以减少内存使用量,还可以训练模型,否则这些模型将超过单个 GPU 的内存容量。ZeRO 通常分三个不同的阶段实现,每个阶段处理内存冗余的不同方面:
ZeRO-1:优化器状态分区
- 在 GPU 之间对优化器状态(例如动量缓冲区)进行分区
- 每个 GPU 仅存储其参数部分的优化器状态
- 模型参数和渐变仍会复制到所有 GPU 上
ZeRO-2:梯度分配
- 包括所有 ZeRO-1
- 此外,还可以在 GPU 之间对梯度进行分区
- 每个 GPU 仅计算和存储其参数部分的梯度
- 模型参数仍会复制到所有 GPU 上
ZeRO-3:参数分区
- 包括所有 ZeRO-1 和 ZeRO-2
- 此外,还可以在 GPU 之间对模型参数进行分区
- 每个 GPU 仅存储一部分模型参数
- 需要在前向/后向传递期间收集参数
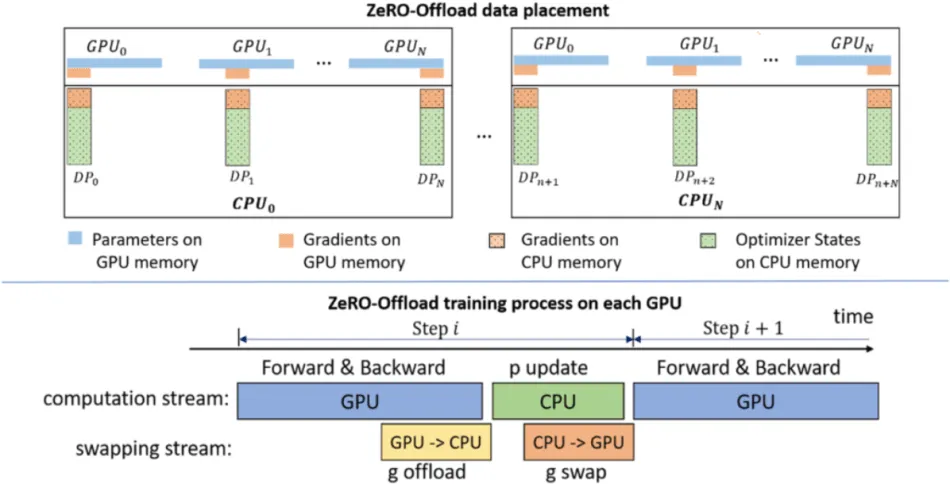
ZeRO 卸载的架构
如上所述,ZeRO 通过结合数据和模型并行性的优势来提供最大的灵活性。
虽然是 DeepSpeed 的一项功能,但它与 PyTorch 的集成使其成为训练优化库中的重要工具,可促进高效的内存管理,并使以前无法训练的模型大小在现代硬件上变得可行。此实例的虚拟实现如下:
import torch
import torch.nn as nn
import deepspeed
class LargeModel(nn.模块):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LargeModel, self).__init__()
self.fc1 = nn.线性 (input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.relu(self.fc1(x))
return self.fc2(x)
model = LargeModel(1024, 4096, 10)
# 使用 ZeRO 优化器设置
配置 DeepSpeed ds_config = {
“train_batch_size”: 32,
“optimizer”: {
“type”: “Adam”,
“params”: {
“lr”: 0.001
}
},
“zero_optimization”: {
“stage”: 2, # 阶段 2: 梯度分区
“allgather_partitions”: True,
“reduce_scatter“: True,
”allgather_bucket_size“: 2e8,
”overlap_comm“: True
}
}
# 使用 ZeRO 初始化模型
model_engine, 优化器, _, _ = deepspeed.initialize(model=model,
config=ds_config)
inputs = torch.randn(32, 1024).to(model_engine.local_rank)
outputs = model_engine(inputs)
loss = outputs.mean() # 简化的损失计算
model_engine.backward(loss)
model_engine.step()关键要点
- 阶段选择 — ZeRO 通常在多个阶段中实现,每个阶段在内存节省和通信开销之间提供不同的平衡。根据模型大小、网络功能和可接受的通信开销水平采用正确的平台至关重要。
- 与其他技术集成 — 它可以无缝地整合到一个生态系统中,该生态系统还可能包括上面讨论的并行化策略。
优点和考虑
- 通信开销 — 此策略的一个固有挑战是,减少内存冗余通常会增加 GPU 之间交换的数据量。因此,高效利用高速互连(如 NVLink 或 InfiniBand)变得更加重要。
- 配置复杂性 — 与更传统的优化器相比,ZeRO 引入了额外的配置参数。这些设置需要仔细的实验和分析,以匹配硬件的优势,从而确保优化器高效运行。设置包括但不限于 — 用于梯度聚合的适当存储桶大小,以及各种状态(优化器状态、梯度、参数)的分区策略。
- 稳健监控 — 在支持 ZeRO 的训练中调试问题可能非常具有挑战性。因此,提供 GPU 内存使用情况、网络延迟和整体吞吐量洞察的监控工具变得势在必行。
将它们汇集在一起
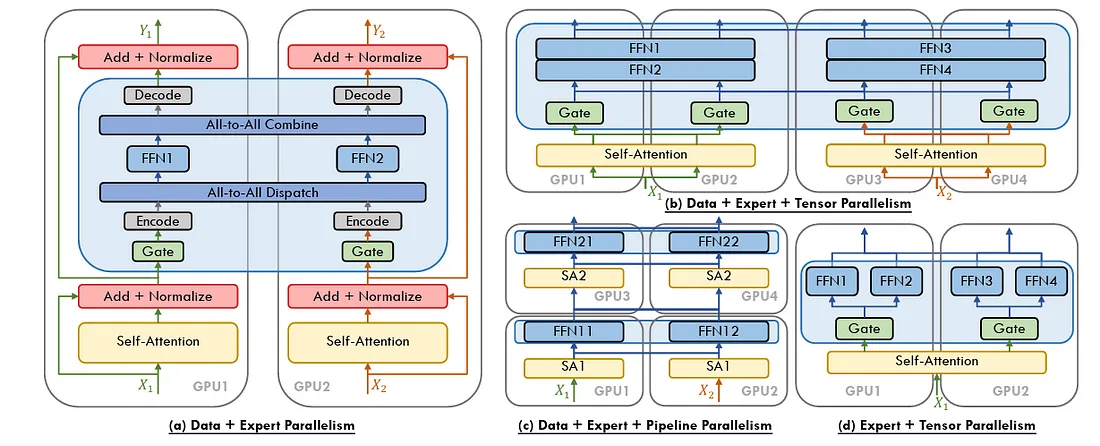
大规模训练深度学习模型通常需要混合方法,通常利用上述技术的组合。例如,最先进的 LLM 可能会使用数据并行性在节点之间分配批次,使用张量并行性来拆分大量权重矩阵,使用上下文并行性来处理冗长的序列,使用管道并行性来链接顺序模型阶段,使用专家并行性来动态分配计算资源,最后使用 ZeRO 来优化内存使用。这种协同作用确保即使是具有天文参数计数的模型也能保持可训练和高效。
了解何时、何地以及如何使用这些技术对于突破可能的界限至关重要。这与 PyTorch 的模块化和即插即用库相结合,构建了强大、可扩展的训练管道,打破了传统硬件的限制,已经越来越多地被更广泛的受众所接受。

















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









