







通过针对图像分类使用场景训练和评估模型的动手指南,深入了解神经网络中反向传播的基本知识。
反向传播是现代神经网络训练的重要组成部分,它使这些复杂的算法能够从训练数据集中学习并随着时间的推移而改进。
理解和掌握反向传播算法对于神经网络和深度学习领域的任何人都至关重要。本教程深入探讨了反向传播。
它首先解释了什么是反向传播及其工作原理,以及它的优点和局限性,然后深入探讨了将其应用于广泛使用的数据集的实践经验。
最强动画解释卷积神经网络中的反向传播!一小时跟着计算机博士搞懂神经网络反向传播及神经网络过拟合解决方法!—深度学习算法
什么是反向传播?
反向传播算法于 1970 年代推出,是一种根据前一次迭代或纪元中获得的误差率微调神经网络权重的方法,这是训练人工神经网络的标准方法。
你可以把它看作是一个反馈系统,在每一轮训练或 “纪元” 之后,网络都会审查其在任务上的表现。它计算其输出与正确答案之间的差异,称为错误。然后,它会调整其内部参数或 'weights' 以减少下次的误差。这种方法对于调整神经网络的准确性至关重要,并且是学习做出更好预测或决策的基础策略
反向传播是如何工作的?
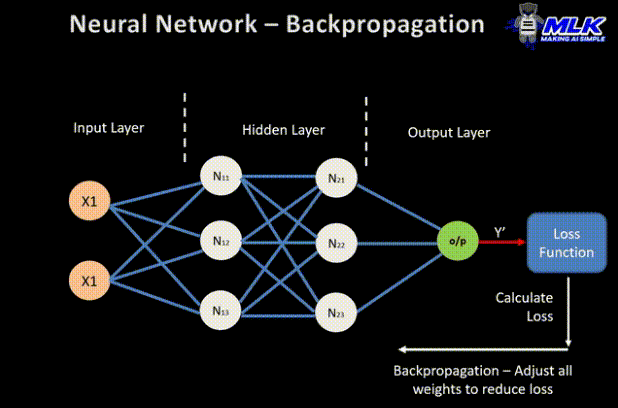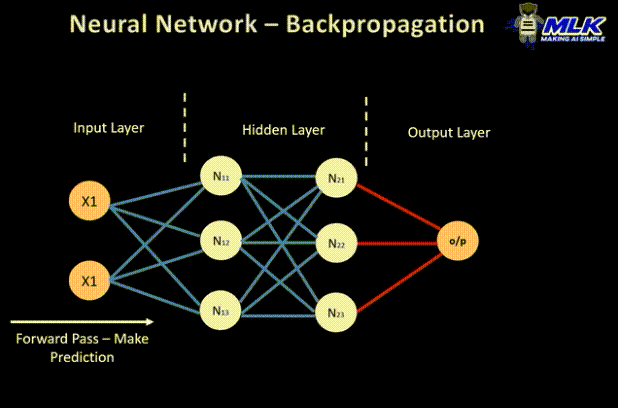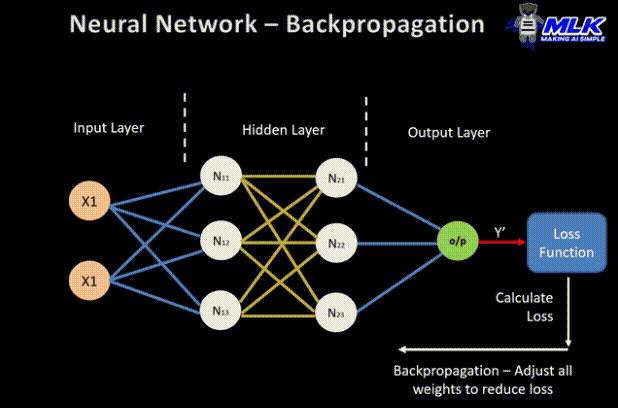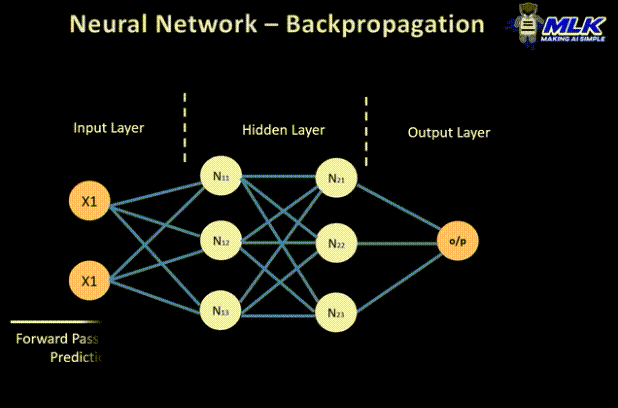
现在您知道什么是反向传播,让我们深入了解它是如何工作的。以下是应用于神经网络的反向传播算法的图示:
- 两个输入 X1 和 X2
- 两个隐藏层 N1X 和 N2X,其中 X 取值 1、2 和 3
- 一个输出层
反向传播图示
反向传播算法通常有四个主要步骤:
- 前向传球
- 误差计算
- 向后传递
- 权重更新
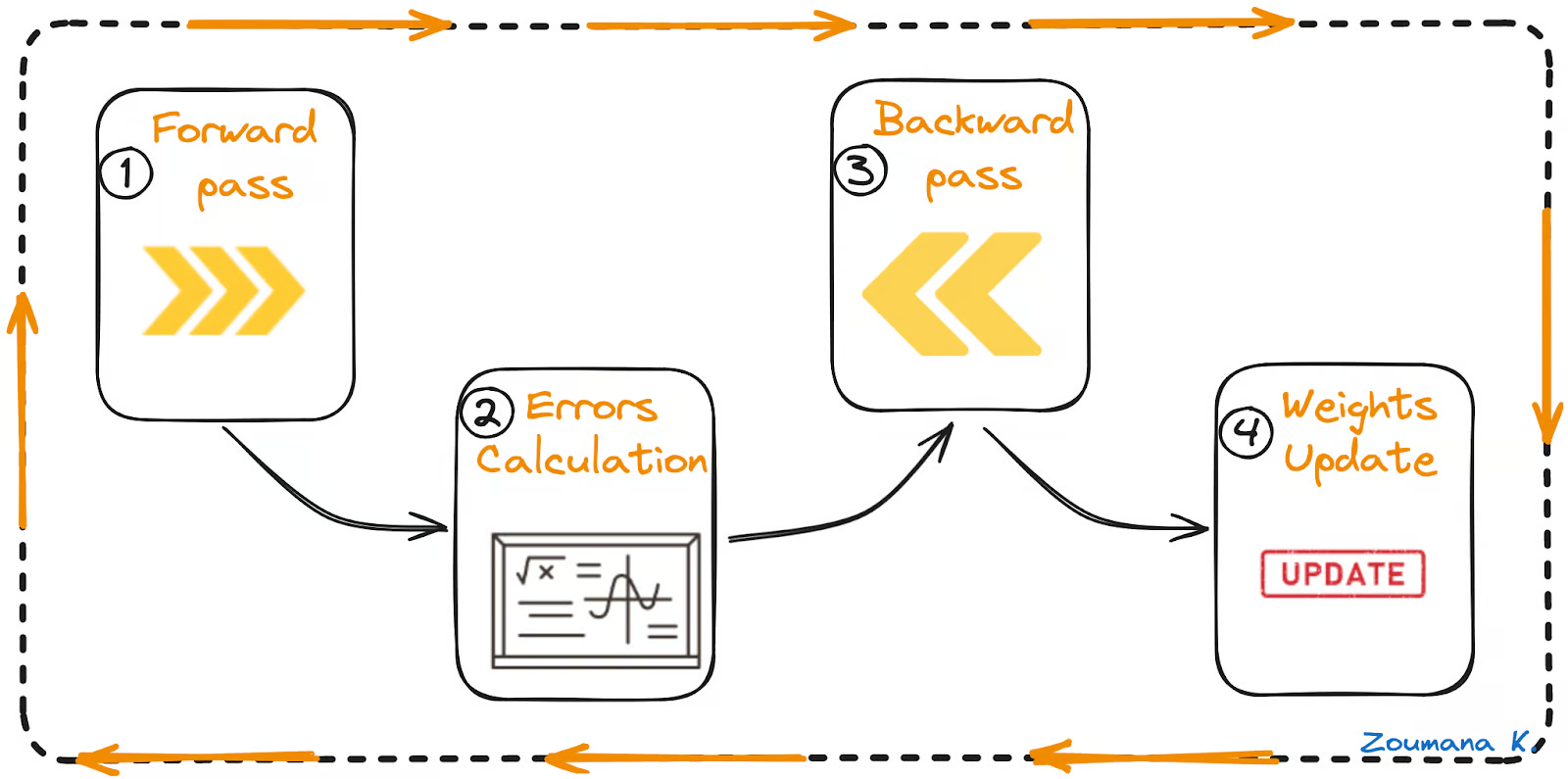
前向传递、误差计算、后向传递和权重更新
让我们从上面的动画中了解每个步骤。
前向传球
这是反向传播过程的第一步,如下所示:
- 数据(输入 X1 和 X2)被馈送到输入层
- 然后,将每个输入乘以其相应的权重,并将结果传递给隐藏层的神经元 N1X 和 N2X。
- 这些神经元将激活函数应用于它们接收到的加权输入,结果传递到下一层。
误差计算
- 该过程一直持续,直到输出层生成最终输出 (o/p)。
- 然后将网络的输出与真实值(所需输出)进行比较,并计算差值,从而得出误差值。
向后传递
这是一个实际的反向传播步骤,如果没有上述前向和误差计算步骤,则无法执行。以下是它的工作原理:
- 先前获得的误差值用于计算损失函数的梯度。
- 误差的梯度通过网络传播回去,从输出层开始到隐藏层。
- 随着误差梯度的传播,权重(由连接节点的线表示)将根据它们对误差的贡献进行更新。这涉及对每个权重的误差进行导数,这表示权重的变化会改变误差的程度。
- 学习率决定了权重更新的大小。较小的学习率意味着比权重更新的量更小,反之亦然。
权重更新
- 权重在梯度的相反方向上更新,因此得名 “梯度下降”。它旨在减少下一次前向传递中的错误。
- 前向传递、误差计算、后向传递和权重更新的过程将持续多个 epoch,直到网络性能达到令人满意的水平或停止显著改善。
反向传播的优点
反向传播是神经网络训练中的一项基础技术,因其简单的实现、编程的简单性和跨多个网络架构的多功能应用而广受赞誉。
现在,让我们详细说明前面提到的每个好处:
- 易于实施:可通过多个深度学习库(如 Pytorch 和 Keras)访问,从而促进其在各种应用程序中的使用。
- 编程简单性:使用框架抽象简化编码,减少对复杂数学的需求。
- 灵活性:适应不同的架构,适合各种 AI 挑战。
限制和挑战
尽管反向传播算法取得了成功,但它并非没有限制,这可能会影响神经网络训练过程的效率和有效性。让我们来探讨一下其中的一些约束:
- 数据质量:数据质量差,包括噪声、不完整或偏差,会导致模型不准确,因为反向传播会准确地学习给定的内容。
- 训练持续时间:反向传播通常需要大量的训练时间,这在处理大型网络时可能不切实际。
- 基于矩阵的复杂性:反向传播中的矩阵运算随网络大小而扩展,这增加了计算需求,并可能超过可用资源。
实现反向传播
有了关于反向传播算法的所有这些见解,现在是时候深入研究它在实际场景中的应用了,通过实施神经网络来识别 MNIST 数据集中的手写数字。
关于数据集
MNIST 数据集在图像识别领域应用广泛。它由 70000 张从 0 到 9 的手写数字灰度图像组成,每张图像的尺寸为 28x28 像素。
该数据集在 Keras.datasets 模块的 mnist 函数中可用,在导入 mnist 库后加载如下:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()探索性数据分析
探索性数据分析是构建任何机器学习或深度学习模型之前的重要步骤,因为它有助于更好地了解手头数据的性质,从而指导您选择要使用的模型类型。
主要任务包括:
- 确定训练和测试数据集中的数据总数。
- 训练数据集中一些数字的随机可视化。
- 可视化训练数据集中标签的分布。
整个数据集由 70000 张图像组成。原始数据集的典型拆分如下,没有具体的经验法则:
- 训练数据集为 70% 或 80%
- 30% 或 20% 用于测试数据集
有些分割甚至可以是 90% 用于训练,10% 用于测试。
在我们的场景中,训练数据集和测试数据集都已加载,因此无需拆分。让我们观察一下这些数据集的大小。
print("Training data")
print(f"- X = {train_images.shape}, y = {train_labels.shape}")
print(f"- Hols {train_images.shape[0]/70000* 100}% of the overall data")
print("\n")
print("Testing data")
print(f"- X = {test_images.shape}, y = {test_labels.shape}")
print(f"- Hols {test_images.shape[0]/70000* 100}% of the overall data")
- 训练数据集有 60000 张图像,相当于原始数据集的 85.71%。
- 另一方面,测试数据集有剩余的 10000 张图像,因此占原始数据集的 14.28%。
现在,让我们可视化一些随机数字。这是通过 helper 函数 plot_images 实现的,该函数采用两个主要参数:
- 要绘制的图像数量,以及
- 要考虑用于可视化的数据集
def plot_images(nb_images_to_plot, train_data):
# Generate a list of random indices from the training data
random_indices = random.sample(range(len(train_data)), nb_images_to_plot)
# Plot each image using the random indices
for i, idx in enumerate(random_indices):
plt.subplot(330 + 1 + i)
plt.imshow(train_data[idx], cmap=plt.get_cmap('gray'))
plt.show()我们希望可视化来自训练数据的 9 张图像,这与以下代码片段相对应:
nb_images_to_plot = 9
plot_images(nb_images_to_plot, train_images)成功执行上述代码会生成以下 9 位数字。

第二次运行相同的函数后显示以下数字,我们注意到它们并不相同;这是由于 helper 函数的随机性。

数据分析的最终任务是使用 plot_labels_distribution 辅助函数可视化训练数据集中标签的分布。
- 在 X 轴中,我们有所有可能的数字
- 在 Y 轴中,我们有此类数字的总数
import numpy as np
def plot_labels_distribution(data_labels):
counts = np.bincount(data_labels)
plt.style.use('seaborn-dark-palette')
fig, ax = plt.subplots(figsize=(10,5))
ax.bar(range(10), counts, width=0.8, align='center')
ax.set(xticks=range(10), xlim=[-1, 10], title='Training data distribution')
plt.show()该函数通过证明其标签来应用于训练数据集,如下所示:
plot_labels_distribution(train_labels)下面是结果,我们注意到所有 10 位数字几乎均匀分布在整个数据集中,这是个好消息,这意味着不需要进一步的作来平衡标签的分布。
数据预处理
真实世界的数据通常需要一些预处理,以使其适合训练模型。有三个主要的预处理任务适用于训练和测试图像:
- 图像标准化:这包括将所有像素值从 0-255 转换为 0-1。这与训练过程中更快的收敛有关
- 重塑图像:我们不是为每个图像使用 28 x 28 的平方矩阵,而是将每个图像展平为 784 个元素的向量,以使其适合神经网络输入。
- Label encoding:将标签转换为 one-hot 编码的 vector。这将避免我们在数字层次结构中可能遇到的问题。这样,模型将偏向于较大的数字。
整体预处理逻辑在下面的 helper 函数中实现:preprocess_data
from keras.utils import to_categorical
def preprocess_data(data, label,
vector_size,
grayscale_size):
# Normalize to range 0-1
preprocessed_images = data.reshape((data.shape[0],
vector_size)).astype('float32') / grayscale_size
# One-hot encode the labels
encoded_labels = to_categorical(label)
return preprocessed_images, encoded_labels该函数使用以下代码片段应用于数据集:
# Flattening variable
vector_size = 28 * 28
grayscale_size = 255
train_size = train_images.shape[0]
test_size = test_images.shape[0]
# Preprocessing of the training data
train_images, train_labels = preprocess_data(train_images,
train_labels,
vector_size,
grayscale_size)
# Preprocessing of the testing data
test_images, test_labels = preprocess_data(test_images,
test_labels,
vector_size,
grayscale_size)现在,让我们观察两个数据集的当前最大和最小像素值:
print("Training data")
print(f"- Maxium Value {train_images.max()} ")
print(f"- Minimum Value {train_images.min()} ")
print("\n")
print("Testing data")
print(f"- Maxium Value {test_images.max()} ")
print(f"- Minimum Value {test_images.min()} ")代码的结果如下所示,我们注意到规范化已成功执行。

与标签类似,我们最终得到了一个 1 和 0 的矩阵,它们对应于这些标签的 one-hot 编码值。
# One hot encoding of the test data labels
test_images结果如下:

# One hot encoding of the train data labels
train_labels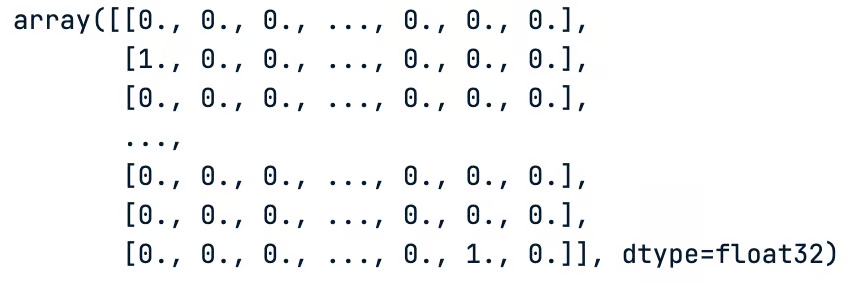
网络结构
由于我们使用的是图像分类任务,因此卷积神经网络更适合这种情况。在编写任何内容之前,定义模型的架构很重要,这就是本节的全部意义所在。
此使用案例的架构结合了不同类型的图层,以实现有效的图像分类。以下是该模型的关键组成部分:
- 卷积层:从一个使用 3x3 小滤波器大小和 32 个滤波器的层开始处理图像。
- Max Pooling Layer:在卷积层之后,包含一个 max pooling 层以减小特征图的大小。
- 展平:将池化层的输出展平为单个向量,为分类过程做好准备。
- 密集层:在展平的输出和最终层之间添加一个具有 100 个节点的密集层,以解释提取的特征。
- Output Layer (输出图层):使用具有 10 个节点的输出图层,对应于 10 个图像类别。每个节点都计算图像属于这些类别之一的概率。
- Softmax 激活:在输出层中,将 softmax 激活函数应用于多类分类。
- ReLU 激活函数:在所有层中使用 ReLU(修正线性单元)激活函数进行非线性处理。
- 优化器:使用学习率为 0.001、动量为 0.95 的随机梯度下降优化器在训练过程中调整模型。
- 损失函数:使用分类交叉熵损失函数,非常适合多类分类任务。
- Accuracy Metric (准确率指标):关注分类 Accuracy Metric (分类准确率) 指标,同时考虑类的均衡分布。
所有这些信息都在 define_network_architecture 帮助程序函数中实现。但在此之前,我们需要导入所有必要的库:
from keras import models
from keras import layers
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import BatchNormalization 这是 helper 函数的实现。
hidden_units = 256
nb_unique_labels = 10
vector_size = 784 # Assuming a 28x28 input image for example
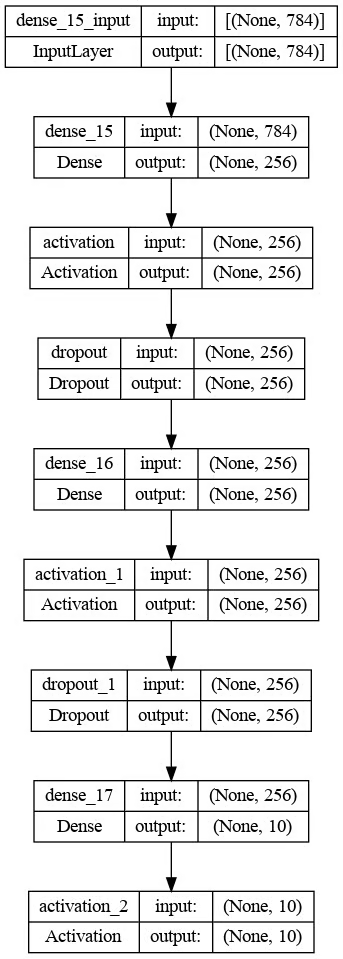
def define_network_architecture():
network = models.Sequential()
network.add(Dense(vector_size, activation='relu', input_shape=(vector_size,))) # Input layer
network.add(Dense(512, activation='relu')) # Hidden layer
network.add(Dense(nb_unique_labels, activation='softmax'))
return network源代码实现很好,但如果我们可以拥有网络的图形可视化就更好了,这是使用模块中的函数实现的。plot_modelkeras.utils.vis_utils
首先,从 helper 函数生成网络。
network = define_network_architecture()然后,显示图形表示。在显示结果之前,我们首先将结果保存到 PNG 文件中;这使得与他人共享变得更加容易。
import keras.utils.vis_utils
from importlib import reload
reload(keras.utils.vis_utils)
from keras.utils.vis_utils import plot_model
import matplotlib.image as mpimg
plot_model(network, to_file='network_architecture.png', show_shapes=True, show_layer_names=True)
img = mpimg.imread('network_architecture.png')
plt.imshow(img)
plt.axis('off')
plt.show()结果如下所示。
计算 delta
在深入研究模型的训练过程之前,我们先了解一下如何使用网络架构计算增量误差分布。
delta 误差分布是损失函数相对于每个节点的激活函数的导数,它表示每个节点的激活对最终误差的贡献程度。
上述架构由三个主要层组成:
- 对应于 28x28 输入图像的 784 个单元的输入层
- 隐藏层 512 与 ReLU 激活相结合
- 具有 10 个单元的输出层,对应于具有 softmax 激活函数的唯一标签的数量
现在,让我们进一步计算每一层的 delta 误差。
输出层
让我们将 softmax 层的输出视为大 O (O),将真实标签视为 Y。通过使用 cross-entropy loss δ output ,delta 误差变为:
δ 输出 = O - Y
该公式来自对 softmax 输出变化时交叉熵损失如何变化的基本计算。
隐藏层
对于隐藏层,增量误差变得δ隐藏,并取决于后续层的误差,对应于输出层,以及激活 ReLU 函数的导数。
ReLU 的导数为 1 表示正输入,0 表示负输入,如下所示。
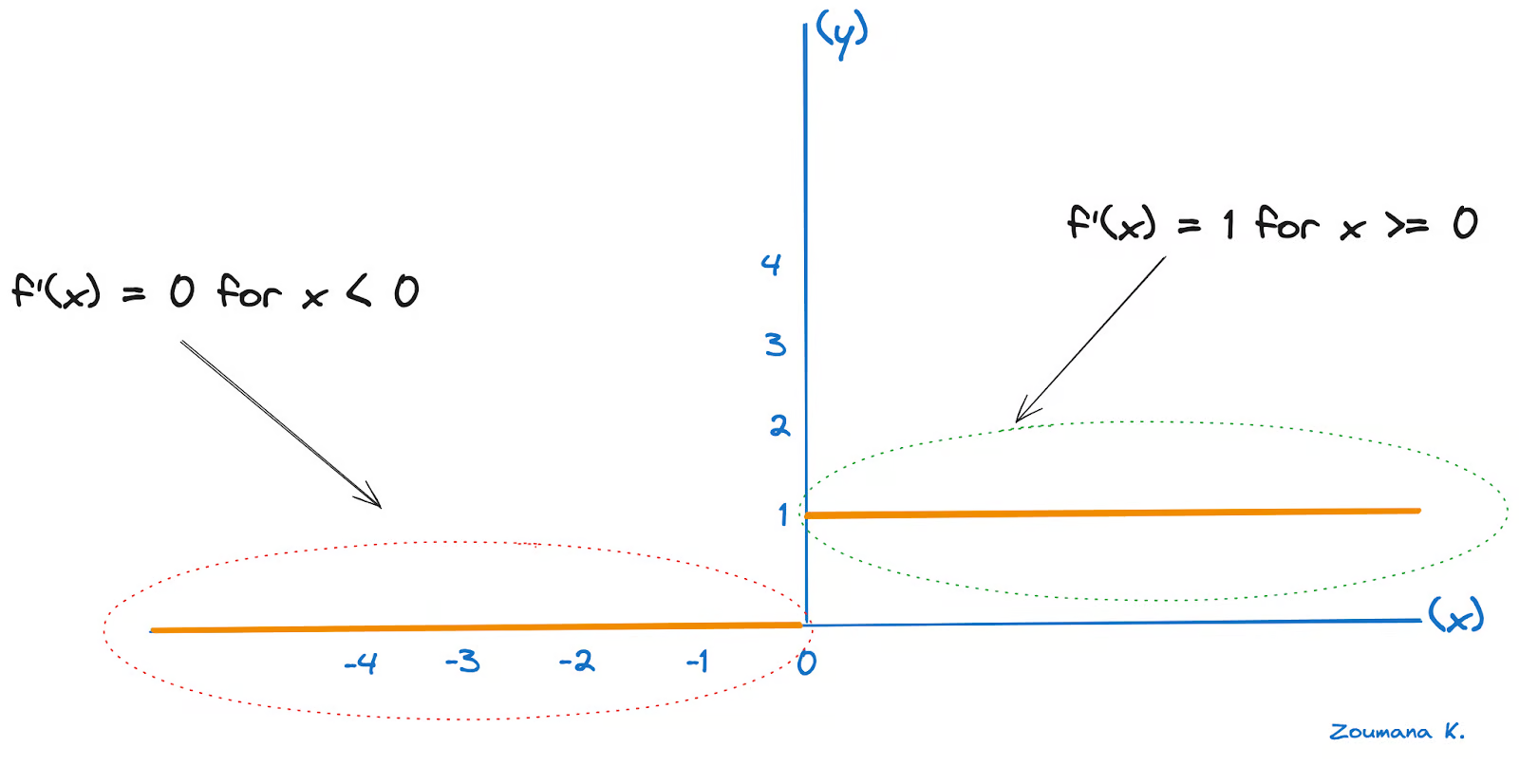
让我们将 Zhidden 视为隐藏层中 ReLU 函数的输入,将 Woutput 视为将隐藏层连接到输出层的权重。在这种情况下,隐藏层的 delta 误差变为:
δ hidden = (δ output . W输出) ⊙ ReLU'(Z隐藏))
- 点符号 “.” 表示矩阵乘法
- 符号 ⊙ 对应于元素乘法
- ReLU'(Z隐藏)对应于 ReLU 在 Z隐藏处的导数
输入层
同样,如果我们有更多的隐藏层,这个过程将向后继续,每个层的 delta 误差取决于后续层的 delta 误差及其激活函数的导数。
在更一般的情况下,对于网络中的任何给定层 k(输出层除外),增量误差计算的公式为:
δ k = (δ k+1 .WTk+1) ⊙ f'(Zk)
- WTk+1 对应于下一层权重矩阵的转置
- f' 是层 k 的激活函数的导数,
- Zk 是层 k 中激活函数的输入
网络编译
了解了误差计算后,我们来编译网络以优化其训练过程的结构。
在编译过程中,我们需要做出几个关键的选择:
- Choice of Optimization Algorithm:这涉及选择梯度下降优化的算法。有多个选项,例如本文中使用的随机梯度下降 (SGD)、Adagrad 和 RMSprop。
- 损失函数的选择: 损失函数,也称为成本函数,是训练的重要组成部分。它量化了网络的性能,损失函数的选择应与分类或回归问题的性质保持一致。由于问题的多类性质,因此重点放在分类交叉熵上。
- 性能指标的选择:虽然与损失函数类似,但性能指标主要用于评估模型在测试数据集上的有效性,我们正在使用准确性
以上三个选项的代码如下:
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])网络训练
训练模型的最大问题之一是过度拟合,在训练过程中监控模型以确保它具有更好的泛化至关重要,其中一种方法是提前停止的概念。
完整的 logic 如下所示:
# Fit the model
batch_size = 256
n_epochs = 15
val_split = 0.2
patience_value = 5
# Fit the model with the callback
history = network.fit(train_images, train_labels, validation_split=val_split,
epochs=n_epochs, batch_size=batch_size)该模型使用 256 的批量大小训练 15 个 epoch,其中 20% 的训练数据用于验证模型。
训练模型后,训练和验证性能历史记录绘制在下面。
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()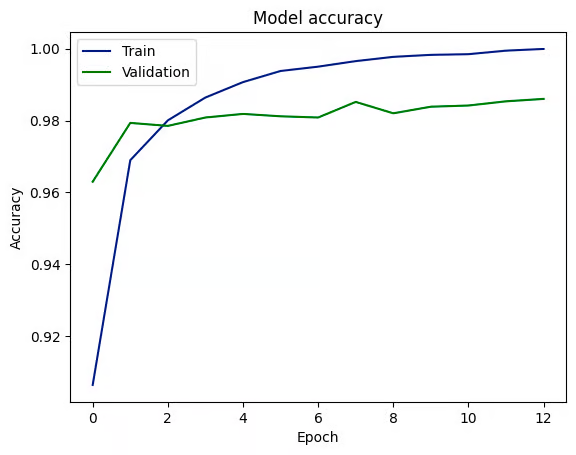
测试数据评估
现在,我们可以使用模型的 evaluate 函数在测试数据上评估模型的性能。
loss, acc = network.evaluate(test_images,
test_labels, batch_size=batch_size)
print("\nTest accuracy: %.1f%%" % (100.0 * acc))
该图表明,该模型已经学会了以高准确度预测结果,在验证和测试数据集上都达到了 98% 左右。这表明从训练到不可见数据具有良好的泛化。但是,训练和验证准确性之间的差距可能是过度拟合的迹象,尽管验证和测试准确性之间的一致性可能会缓解这种担忧。
建议
尽管该模型显示出很高的准确性和泛化能力,但仍有改进的余地,以下是一些进一步提高性能的可行步骤。
- 正则化:集成正则化方法以减少过拟合。
- Early Stopping:在训练期间利用 Early Stopping 来防止过度拟合。
- 错误分析:分析错误预测以识别和纠正潜在问题。
- 多样性测试:在各种数据集上测试模型以确认其稳健性。
- 更广泛的指标:使用精确率、召回率和 F1 分数进行完整的性能评估,尤其是在数据不平衡的情况下。
结论
总之,本文对反向传播进行了全面的探索,反向传播是机器学习领域的一项基本技术。我们首先明确了什么是反向传播,并概述了它在人工智能发展中的关键作用。
接下来,我们深入研究了反向传播的工作原理及其一些优势,例如提高学习效率,同时也承认它面临的局限性和挑战。
然后,它提供了有关设置和构建神经网络的详细指导,强调了前向传播的重要性。
在最后各节中,我们探讨了计算增量和更新网络权重的步骤,这些步骤对于优化学习过程至关重要。
总的来说,本文对于任何旨在理解和有效实现神经网络中的反向传播的人来说都是宝贵的资源。

















 8037
8037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









