







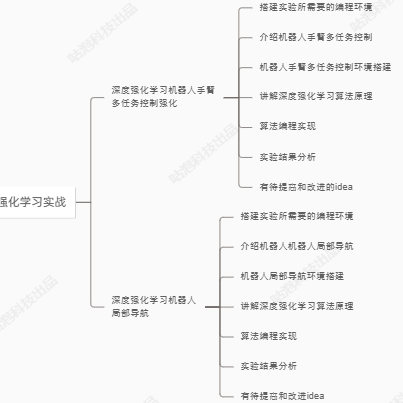
为了学习如何使用PPO算法解决两足机器人的步行问题,可以从以下几个方面逐步深入:
强化学习基础
强化学习基本概念
状态(State) : 表征环境的一个向量,可以是关节角度、角速度等。
动作(Action) : 机器人可采取的行为,例如施加在关节上的力矩。
奖励(Reward) : 根据动作的效果给予的反馈,用于指导策略的优化。
环境(Environment) : 机器人与之互动的外部世界,在此环境中,机器人根据当前状态采取行动,并接收新的状态和奖励。
强化学习算法
Q-Learning : 使用Q表存储状态-动作对的价值,适合离散状态和动作空间。
策略梯度(Policy Gradient) : 直接优化策略参数的方法,适合连续动作空间。
深度强化学习基础
深度Q网络(DQN)
- 将深度神经网络与Q-Learning结合,用于处理高维状态空间,如图像输入。
深度确定性策略梯度(DDPG)
- 结合Actor-Critic框架,适用于连续动作空间,通过确定性策略输出连续动作。
PPO算法详解
PPO基本原理

实现细节
- 重要性采样 : 用于估计新旧策略间的差异,决定是否接受更新。
- 策略裁剪 : 限制概率比的变化范围,防止策略更新幅度过大。
两足机器人步行控制
动态模型
- 线性倒立摆(LIP)模型 : 用于简化两足机器人步行控制,假设质心高度不变,将复杂的非线性动力学简化为线性方程。
- 五连杆模型 : 更准确地模拟两足机器人,可用于直接求解关节力矩。
控制方法
- 混合零动力(HZD) : 基于虚拟约束的反馈控制方法,常用于全模型和五连杆模型。
- 模型预测控制(MPC) : 结合DRL预测干扰,提高鲁棒性。
实践案例
Mujoco仿真平台
- 环境搭建 : 使用Mujoco物理引擎创建两足机器人模型,定义状态、动作和奖励函数。
- PPO算法实现 : 利用OpenAI Baselines或其他RL库实现PPO算法,训练机器人学习步行策略。
Matlab算例
- DDPG和TD3算法 : 通过Matlab内置的强化学习工具箱,使用DDPG和TD3算法训练两足机器人沿直线行走。
- 环境和智能体交互 : 通过Simulink模型实现环境与智能体的交互,进行训练和测试。
分层控制策略
高级控制策略
- PPO算法 : 用于优化策略,结合课程学习(Curriculum Learning)提升泛化能力。
- 优势型演员-评论家框架 : 使用Advantage函数评估动作价值,提高训练稳定性。
低级控制器
- PD控制器 : 将期望的关节位置转化为实际的关节力矩,频率高达1000Hz。
总结
通过以上步骤,从基础理论到实践案例,逐步掌握使用PPO算法解决两足机器人步行问题的关键技术和实现方法。结合仿真平台和现有工具,进行实践操作,进一步深化理解和应用能力。

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









