







在机器学习领域,有许多形式简单却非常巧妙的想法(idea)。这些想法往往能够在保证算法简洁性的同时,解决复杂的问题。下面列出了一些典型的例子:
1、异常检测算法:Isolation Forest(孤立森林)
原理:Isolation Forest通过递归地将数据空间分割成子空间,来识别异常点。异常点通常更容易被孤立,因为在空间中与其他点的距离更远。通过构建多棵随机分割的二叉树(隔离树),那些在少数几步分割中就被孤立的点更可能被标记为异常点。
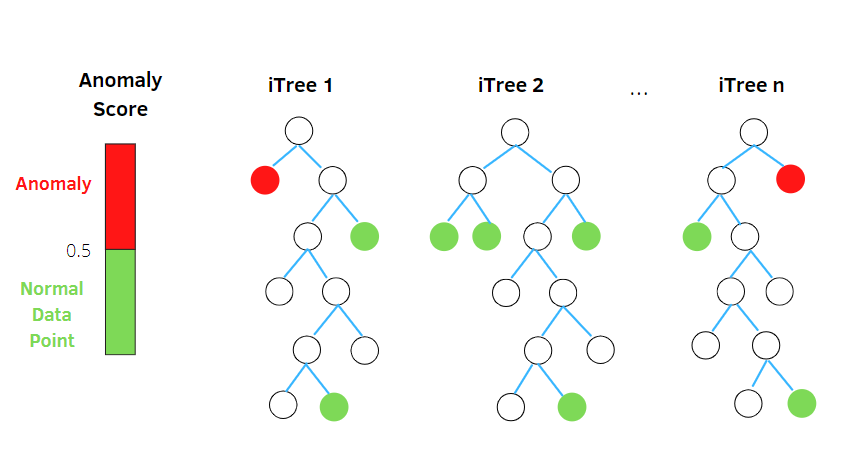
应用场景:异常检测在金融欺诈识别、网络安全等领域有着广泛应用。
2、Word2Vec
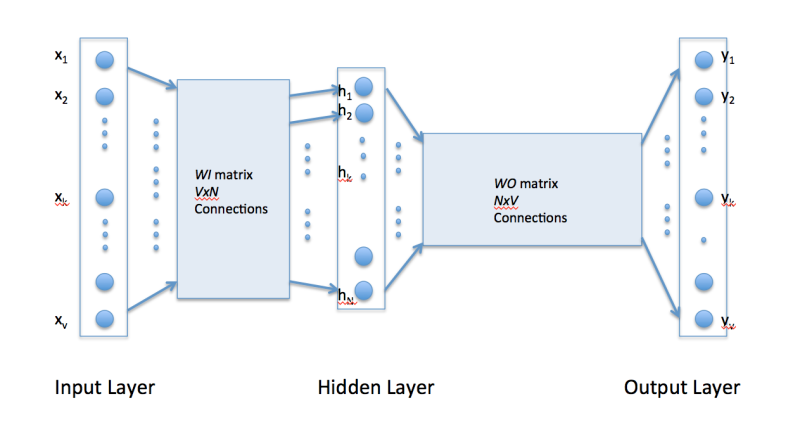
原理:Word2Vec通过训练神经网络来预测词语在句子中的出现概率,从而将词语转化为稠密向量(词嵌入)。Skip-Gram和CBOW是两种常用的模型架构,前者根据给定词语预测其上下文词语,后者则是根据上下文词语预测给定词语。
应用场景:词嵌入技术在自然语言处理(NLP)任务中几乎成为了标准做法,如情感分析、命名实体识别等。
3、成分分析(Principal Component Analysis, PCA)
原理:PCA通过线性变换将原始数据转换到一个新的坐标系,使得数据在第一个坐标轴(主成分)上有最大的方差,依次类推。通过这种方式,可以在减少数据维度的同时保留大部分的信息。
应用场景:广泛应用于数据降维、可视化以及特征提取等领域。
4、Residual Learning(残差学习)
原理:在深层神经网络中,随着网络深度增加,会出现梯度消失或爆炸问题,导致训练效果变差。Residual Learning提出了一种残差块(Residual Block)结构,通过在网络中添加捷径连接(Shortcut Connection),使网络可以直接学习残差映射,从而解决了这个问题。
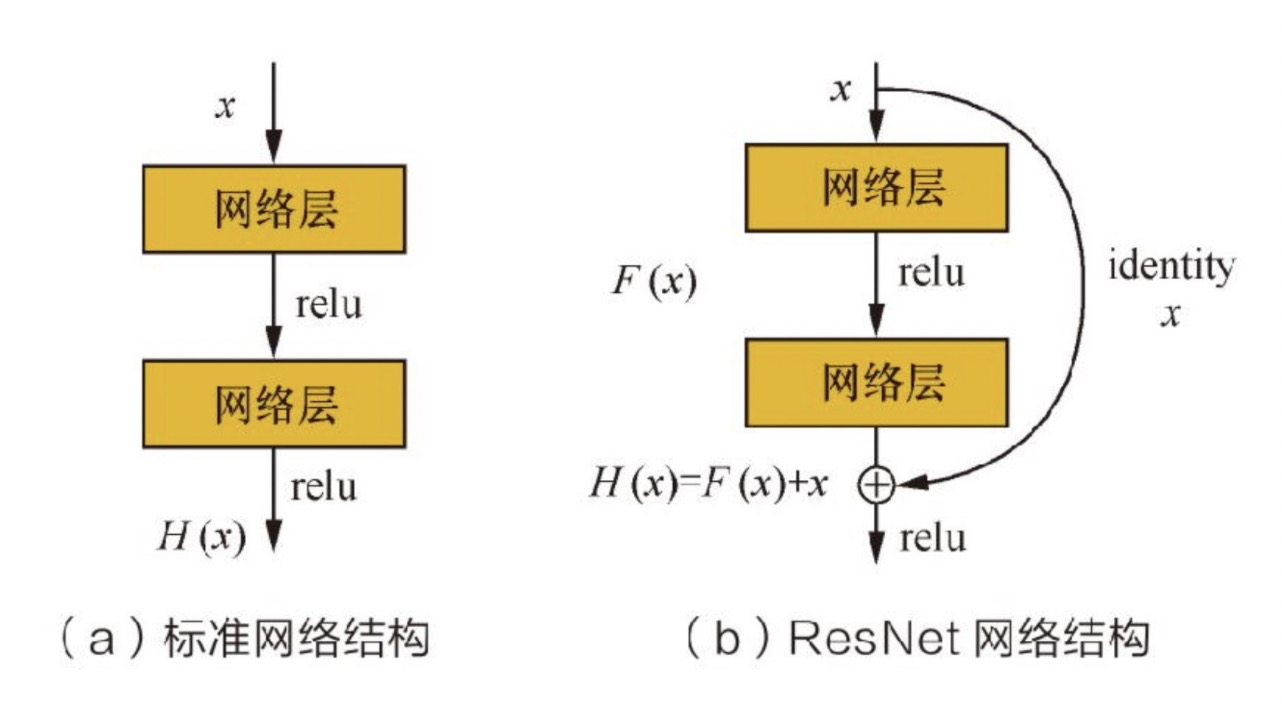
应用场景:残差网络(ResNet)在图像识别、目标检测等多个计算机视觉任务中取得了巨大的成功。
5、Support Vector Machine(支持向量机,SVM)
原理:SVM通过找到一个最佳的超平面来分割不同类别的数据点,使得各类别之间的间隔最大化。通过使用核技巧(Kernel Trick),SVM还可以有效地处理非线性可分的数据。
应用场景:SVM在生物信息学、手写数字识别等领域有广泛的应用。
6、Dropout
原理:Dropout是一种防止神经网络过拟合的技术,通过在每次训练迭代中随机丢弃一部分神经元,强制网络学习更多的独立表示,增加了模型的泛化能力。
应用场景:广泛应用于各种类型的神经网络中,特别是在大规模深度学习模型中。
7、Mixup
原理:Mixup通过对输入样本及其标签进行线性插值,生成虚拟的训练样本,从而增强了模型的泛化能力和鲁棒性。 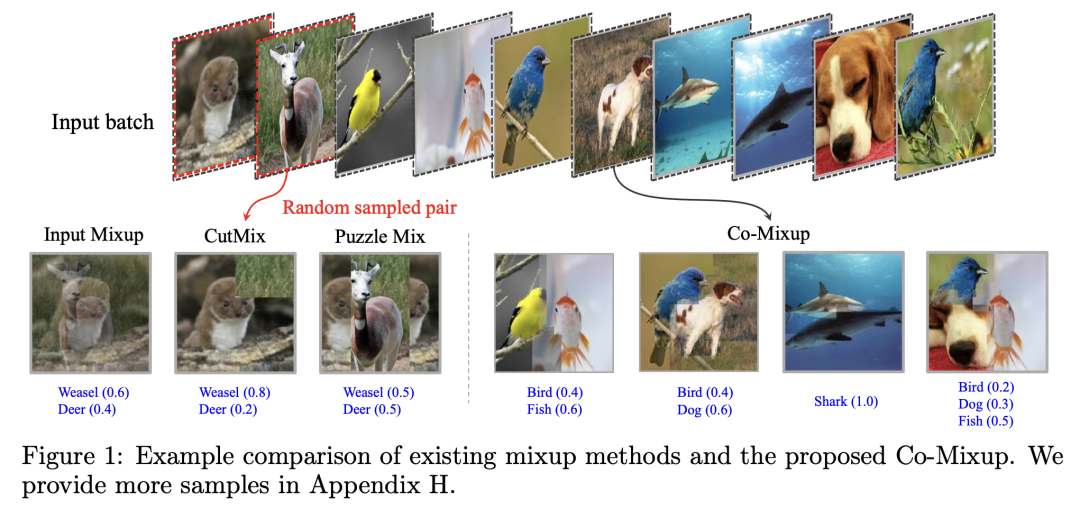
应用场景:图像分类、语音识别等任务中均有应用。
8、Contrastive Learning(对比学习)
原理:对比学习通过拉近相同类别的样本表示,推开不同类别的样本表示,从而学习到更好的数据表示。
应用场景:在自监督学习和无监督学习中表现优异,如SimCLR、MoCo等模型。
这些想法不仅在理论上具有创新性,而且在实践中也得到了广泛验证和应用,推动了机器学习领域的发展。

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









