 使用LangChain和LlamaIndex实现RAG系统
使用LangChain和LlamaIndex实现RAG系统








大型语言模型 (LLM) 展示了重要的能力,但有时在缺乏信息时会产生不正确但可信的响应,这被称为“幻觉”。这意味着他们自信地提供听起来可能准确但由于知识过时而不正确的信息。
Retrieval-Augmented Generation 或 RAG 框架通过将信息检索系统集成到 LLM 管道中来解决这个问题。RAG 允许模型在生成响应时从外部知识源动态获取信息,而不是依赖预先训练的知识。这种动态检索机制确保 LLM 提供的信息不仅与上下文相关,而且准确和最新。
使用外部数据库提供其他或特定于域的信息是一种更有效的方法,而不是根据更新的数据重复重新训练或微调模型。
在本文中,我们将了解 RAG 的工作原理,并使用 LangChain 和 LlamaIndex 创建我们自己的基本和高级 RAG 系统。
现在让我们开始了解 RAG 的工作原理。
RAG 如何运作?
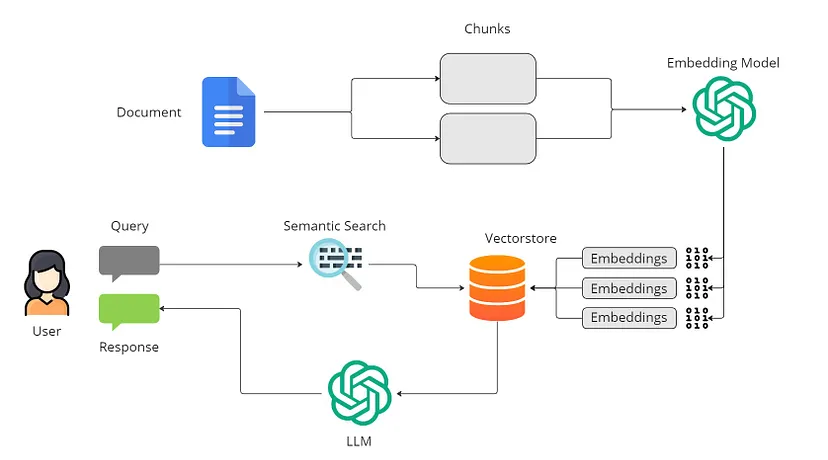
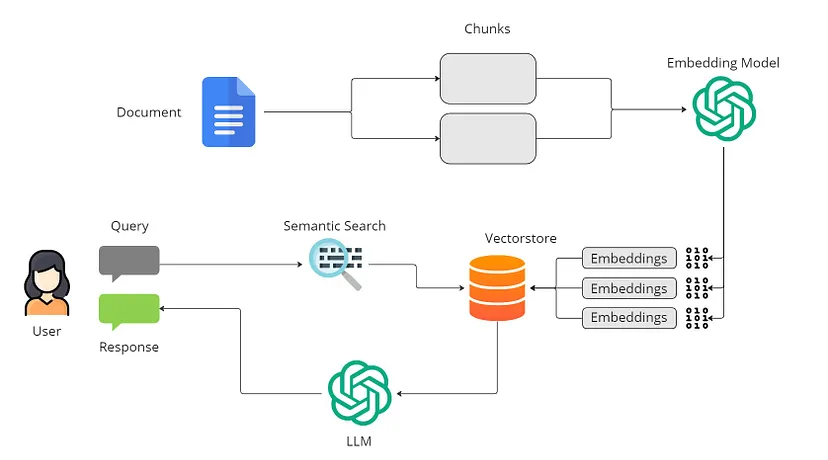
基本的 RAG 工作流程如下所示:
索引
索引过程是为语言模型准备数据的关键第一步。原始数据经过清理,转换为标准化的纯文本,并分割成更小的块,以便进行高效处理。这些块通过嵌入模型转换为向量表示,从而在检索过程中促进相似性比较。最终索引存储这些文本块及其向量嵌入,从而实现高效且可扩展的搜索功能。
检索
当用户提出问题时,系统会使用索引阶段的编码模型对其进行转码。接下来,它计算索引语料库中查询向量和矢量化块之间的相似性分数。系统对显示最高相似度的前 K 个数据块进行优先级排序和检索,将它们用作扩展的上下文基础来满足用户的请求。
代
用户的问题和选择的文档将合并为大型语言模型的清晰提示。然后,模型制作一个响应,根据特定于任务的标准调整其方法。
现在让我们看看如何使用 LangChain 和 LlamaIndex 实现基本的 RAG 技术。
使用 LangChain 和 LlamaIndex 的基本 RAG 实现
Google Colab
1. LangChain
步骤1: 首先安装并加载所有必要的库。
!pip install sentence_transformers pypdf faiss-gpu
!pip install langchain langchain-openai
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
# For openai key
import os
os.environ["OPENAI_API_KEY"] = "Your Key"
步骤2: 接下来,使用 PyPDFLoader 加载 PDF 文档以从 PDF 文件中提取文本。
# load a PDF
loader = PyPDFLoader("/content/qlora_paper.pdf")
documents = loader.load()
步骤3:加载 PDF 后,使用 TextSplitter 将文档拆分为多个块。
# Split text
text = RecursiveCharacterTextSplitter().split_documents(documents)
步骤4:现在,加载嵌入模型以将文本转换为数字嵌入。在这里,我们使用的是 “BAAI/bge-small-en-v1.5” 嵌入模型,但您可以从 Hugging Face 嵌入模型中选择任何模型。
# Load embedding model
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en-v1.5",
encode_kwargs={"normalize_embeddings": True})
步骤5: 使用 FAISS 创建 Vector Store 来存储嵌入和文本块。如果需要,可以保存这些嵌入以供以后使用。
# Create a vectorstore
vectorstore = FAISS.from_documents(text, embeddings)
# Save the documents and embeddings
vectorstore.save_local("vectorstore.db")
步骤6: 现在,使用 vector store 创建一个检索器。此步骤为基于向量相似性的信息检索奠定了基础。
# Create retriever
retriever = vectorstore.as_retriever()
步骤7: 加载要用于检索的语言模型 (LLM) 并创建文档链。
# Load the llm
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
# Define prompt template
template = """
You are an assistant for question-answering tasks.
Use the provided context only to answer the following question:
<context>
{context}
</context>
Question: {input}
"""
# Create a prompt template
prompt = ChatPromptTemplate.from_template(template)
# Create a chain
doc_chain = create_stuff_documents_chain(llm, prompt)
chain = create_retrieval_chain(retriever, doc_chain)
步骤8: 最后,通过组合检索器和文档链来创建检索链。使用用户查询调用链以获取相关响应。
# User query
response = chain.invoke({"input": "what is Qlora?"})
# Get the Answer only
response['answer']
Output:
QLoRA is an efficient finetuning approach that allows for the finetuning of
quantized language models without any performance degradation.
It reduces memory usage enough to finetune a 65B parameter model on a single
48GB GPU while preserving full 16-bit finetuning task performance.
现在让我们继续使用 LlamaIndex 进行基本的 RAG
2. 骆驼指数
步骤1: 首先从 llamaIndex 安装并加载所有必要的库。
! pip install -U llama_hub llama_index pypdf
from llama_index import SimpleDirectoryReader
from llama_index import Document
from llama_index.node_parser import SimpleNodeParser
from llama_index.schema import IndexNode
from llama_index.llms import OpenAI
from llama_index import ServiceContext
from llama_index import VectorStoreIndex
from llama_index.query_engine import RetrieverQueryEngine
# For openai key
import os
os.environ["OPENAI_API_KEY"] = "Your Key"
步骤2: 加载 PDF 文档并将文档的每一页合并到一个文档对象中。
# load pdf
documents = SimpleDirectoryReader(
input_files=["/content/qlora_paper.pdf"]).load_data()
# combine documents into one
doc_text = "\n\n".join([d.get_content() for d in documents])
text= [Document(text=doc_text)]
步骤3:现在,将文档拆分为文本块。这些块在 LlamaIndex 中称为 “Nodes”。此外,请重置默认节点 ID 以便更好地理解。
# set up text chunk
node_parser = SimpleNodeParser.from_defaults()
# split doc
base_nodes = node_parser.get_nodes_from_documents(text)
# reset node ids
for idx, node in enumerate(base_nodes):
node.id_ = f"node-{idx}"
步骤4: 加载嵌入模型和语言模型 (LLM)。我们使用的是与 LangChain 相同的模型。
# load embedding model
embed_model = resolve_embed_model("local:BAAI/bge-small-en")
# load llm
llm = OpenAI(model="gpt-3.5-turbo")
步骤5:通过捆绑 LLM 和嵌入模型来为索引和查询阶段创建服务。
# set up service
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
步骤6: 创建并存储节点 (块) 的嵌入,并将其存储在 vector store 索引中。
# create & store in embeddings vectorstore index
index = VectorStoreIndex(base_nodes, service_context=service_context)
步骤7:使用向量存储索引创建检索器,以检索用户查询的相关信息。
# create retriever
retriever = index.as_retriever()
步骤8: 最后,通过组合检索器和服务上下文来设置查询引擎,并添加用户查询以获取相关响应。
# set up query engine
query_engine = RetrieverQueryEngine.from_args(retriever,
service_context=service_context)
# query
response = query_engine.query("What is Qlora?")
print(str(response))
Output:
QLORA is an efficient finetuning approach that allows for the reduction of
memory usage while preserving the performance of a pretrained language model.
It achieves this by backpropagating gradients through a frozen, 4-bit
quantized pretrained language model into Low Rank Adapters (LoRA). QLORA
introduces several innovations to save memory, including the use of a new
data type called 4-bit NormalFloat (NF4), Double Quantization to reduce
memory footprint, and Paged Optimizers to manage memory spikes. QLORA has
been used to finetune more than 1,000 models and has shown state-of-the-art
results in chatbot performance.
现在让我们看看如何使用 Advanced RAG 改善 LLM 响应。
使用 LangChain 和 LlamaIndex 的高级 RAG 实现
基本 RAG 技术的问题在于,随着文档大小的增加,嵌入会变得更大、更复杂,这会降低文档的特异性和上下文含义。为了解决这个问题,我们使用称为 Parent Document Retriever 的高级 RAG 技术。
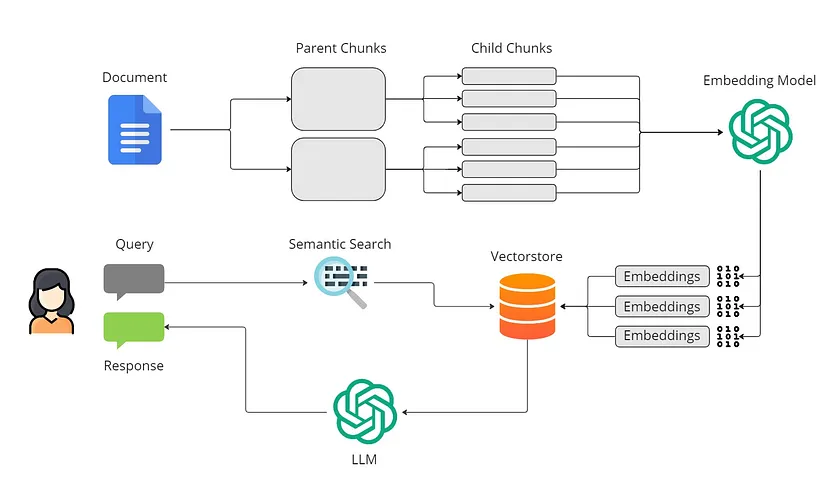
Parent Document Retriever 可创建更小且更准确的嵌入,同时保留大型文档的上下文含义。父文档检索器通过使用子文档中的详细信息进行准确检索并在生成过程中从父文档获取其他上下文来帮助 LLM。这使得语言模型更擅长提供详细而全面的答案。
让我们看看如何使用 LangChain 和 LlamaIndex 实现 Parent Document Retriever 技术。
1. LangChain
父文档检索器 LangChain 文档。
更新基本 RAG 流程中的以下步骤。
步骤3:使用 TextSplitter 将文档拆分为父块和子块。
# split pages content
from langchain.text_splitter import RecursiveCharacterTextSplitter
# create the parent documents - The big chunks
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# create the child documents - The small chunks
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The storage layer for the parent chunks
from langchain.storage import InMemoryStore
store = InMemoryStore()
步骤5: 使用 Chromadb 创建 Vector Store 来存储新的嵌入和文本块。
# create vectorstore using Chromadb
from langchain.vectorstores import Chroma
vectorstore = Chroma(collection_name="split_parents",
embedding_function=embeddings)
步骤6: 创建一个 Parent doc retriever(父文档检索器),然后将文档添加到检索器中。
# create retriever
from langchain.retrievers import ParentDocumentRetriever
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
# add documents to vectorstore
retriever.add_documents(documents)
步骤8: 最后,创建一个检索链,类似于前面的链,并使用用户查询调用它以获取响应。
# User query
response = chain.invoke({"input": "what is Qlora?"})
# Get the Answer only
response['answer']

正如您在输出中看到的,与基本的 RAG 方法相比,我们得到了更详细的响应。
2. 骆驼指数
父文档 Reteriver LlamaIndex 文档。
更新基本 RAG 中的以下步骤。
步骤3: 在本节中,我们在 'sub_chunk_sizes' 中设置子块大小 (128, 256, 512) 并为子块创建解析器 ('sub_node_parsers')。这些具有特定大小的解析器将用于解析原始文档中的子块。
然后,我们迭代每个原始文档块 ('base_node')。对于每个基本节点,我们使用解析器生成链接到其父节点的子节点。父节点和子节点将添加到 'all_nodes' 列表中。
最后,创建一个字典 ('all_nodes_dict'),以便根据节点的 ID 轻松访问节点。这有助于有效地检索信息。
# add this code after base node
# set up child chunk
sub_chunk_sizes = [128, 256, 512]
sub_node_parsers = [
SimpleNodeParser.from_defaults(chunk_size=c,chunk_overlap=20) for c in sub_chunk_sizes
]
all_nodes = []
for base_node in base_nodes:
for n in sub_node_parsers:
sub_nodes = n.get_nodes_from_documents([base_node])
sub_inodes = [
IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes
]
all_nodes.extend(sub_inodes)
# also add original node to node
original_node = IndexNode.from_text_node(base_node, base_node.node_id)
all_nodes.append(original_node)
all_nodes_dict = {n.node_id: n for n in all_nodes}
步骤6: 创建所有节点(包含父节点和子节点)的嵌入,并将它们存储在向量存储索引中。
# create and store embedding in vectorstore
index = VectorStoreIndex(all_nodes, service_context=service_context)
步骤7:在 Retriever 进程中,我们使用 RecursiveRetriever,它根据 “引用” 导航节点连接。此检索器探索从节点到其他检索器的链接。如果检索到的节点包括 IndexNodes,则它会进一步探索链接的检索器并执行查询。这种递归方法有助于有效地收集信息。
# create retriever
vector_retriever_chunk = index.as_retriever()
from llama_index.retrievers import RecursiveRetriever
retriever_chunk = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever_chunk},
node_dict=all_nodes_dict,
verbose=True,
)
步骤8: 最后,通过组合检索器和服务上下文来设置查询引擎,并添加用户查询。
# create retriever query
from llama_index.query_engine import RetrieverQueryEngine
query_engine_chunk = RetrieverQueryEngine.from_args(retriever_chunk,
service_context=service_context)
# query
response = query_engine_chunk.query("What is Qlora?")
print(str(response))

与基本 RAG 相比,这里我们还得到了更详细的响应。
总结
在本文中,我们探讨了 RAG 的基本原理,并使用 LangChain 和 LlamaIndex 成功开发了基础和高级 RAG 系统。我希望这篇文章对您有所帮助。我建议探索其他高级 RAG 技术并使用不同的数据类型(如 CSV)以获得更多经验。


















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









