




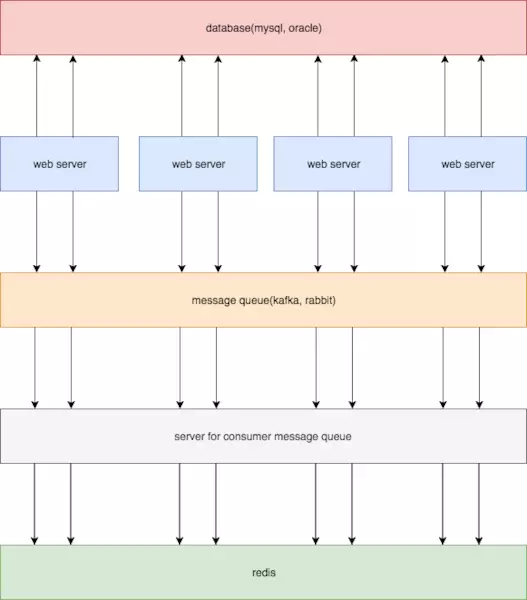
 本文探讨了数据库缓存一致性的重要性,以redis作为mysql缓存为例,提出了四种方案:1)仅依赖key过期时间;2)更新mysql时同步更新redis;3)结合消息队列异步更新;4)通过订阅binlog更新。总结指出,方案1适用于大多数场景,而方案4适合对延时要求较高的业务。
本文探讨了数据库缓存一致性的重要性,以redis作为mysql缓存为例,提出了四种方案:1)仅依赖key过期时间;2)更新mysql时同步更新redis;3)结合消息队列异步更新;4)通过订阅binlog更新。总结指出,方案1适用于大多数场景,而方案4适合对延时要求较高的业务。
背景
缓存是软件开发中一个非常有用的概念,数据库缓存更是在项目中必然会遇到的场景。而缓存一致性的保证,更是在面试中被反复问到,这里进行一下总结,针对不同的要求,选择恰到好处的一致性方案。
缓存是什么
存储的速度是有区别的。缓存就是把低速存储的结果,临时保存在高速存储的技术。
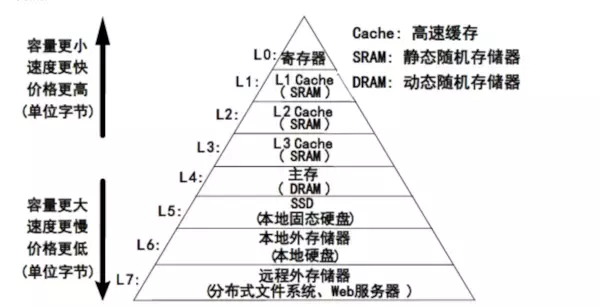
如图所示,金字塔更上面的存储,可以作为下面存储的缓存。我们本次的讨论,主要针对数据库缓存场景,将以redis作为mysql的缓存为案例来进行。
为什么需要缓存
存储如mysql通常支持完整的ACID特性,因为可靠性,持久性等因素,性能普遍不高,高并发的查询会给mysql带来压力,造成数据库系统的不稳定。同时也容易产生延迟。根据局部性原理,80%请求会落到20%的热点数据上,在读多写少场景,增加一层缓存非常有助提升系统吞吐量和健壮性。
存在问题
存储的数据随着时间可能会发生变化,而缓存中的数据就会不一致。具体能容忍的不一致时间,需要具体业务具体分析,但是通常的业务,都需要做到最终一致。
redis作为mysql缓存
通常的开发模式中,都会使用mysql作为存储,而redis作为缓存,加速和保护mysql。但是,当mysql数据更新之后,redis怎么保持同步呢。
强一致性同步成本太高,如果追求强一致,那么没必要用缓存了,直接用mysql即可。通常考虑的,都是最终一致性。
解决方案
方案一
通过key的过期时间,mysql更新时,redi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









