




 Kafka利用页缓存技术和磁盘顺序写实现高性能磁盘写入,保证每秒写入大量数据。同时,通过零拷贝技术减少数据消费时的拷贝步骤,提升读取性能。这些设计使得Kafka能够达到每秒几十万的吞吐量。
Kafka利用页缓存技术和磁盘顺序写实现高性能磁盘写入,保证每秒写入大量数据。同时,通过零拷贝技术减少数据消费时的拷贝步骤,提升读取性能。这些设计使得Kafka能够达到每秒几十万的吞吐量。
开篇
在初识kafka 一文中讲了使用MQ(消息队列)来设计系统带来的好处:业务解耦、流量削峰、灵活扩展
当下流行的MQ有很多,因为我们公司在技术选型上选择了使用Kafka,所以我就整理了一篇关于Kafka的入门知识。通过技术选型 我们对业界主流的MQ进行了对比,Kakfa最大的优点就是吞吐量高 。
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么Kafka是如何做到这么高的吞吐量和性能的呢?在入门之后我们就来深入的扒一下Kafka的架构设计原理,掌握这些原理在互联网面试中会占据优势
持久化
Kafka对消息的存储和缓存依赖于文件系统,每次接收数据都会往磁盘上写,人们对于“磁盘速度慢”的普遍印象,使得人们对于持久化的架构能够提供强有力的性能产生怀疑。
事实上,磁盘的速度比人们预期的要慢的多,也快得多,这取决于人们使用磁盘的方式。而且设计合理的磁盘结构通常可以和网络一样快。
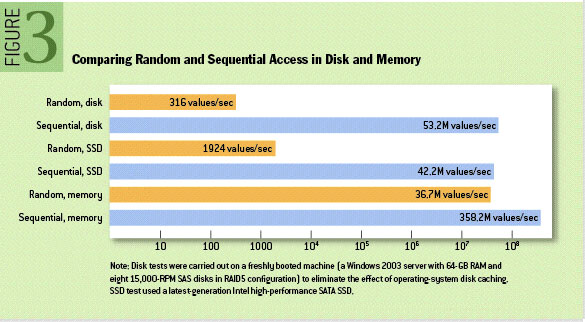
通过上图对比,我们可以看出实际上顺序磁盘访问在某些情况下比随机内存访问还要快,其实Kafka就是利用这一优势来实现高性能写磁盘
See:http://kafka.apachecn.org/documentation.html#persistence
页缓存技术 + 磁盘顺序写
Kafka 为了保证磁盘写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做page cache,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









