





项目地址:https://github.com/dataanswer/awesome-agent-benchmarks
在线导航站:https://www.dataanswer.top
随着 LLM Agent 技术从实验室走向产业落地,“如何科学评估一个 AI Agent 的真实能力?” 已成为研究者与开发者的核心命题。
然而,当前 Agent 评测生态呈现 “百花齐放,标准缺失” 的局面:
- 数据集散落在 GitHub、Hugging Face、论文附录中,难以系统检索
- 缺乏统一的能力维度划分,跨任务对比困难
- 新 benchmark 层出不穷,但质量参差不齐

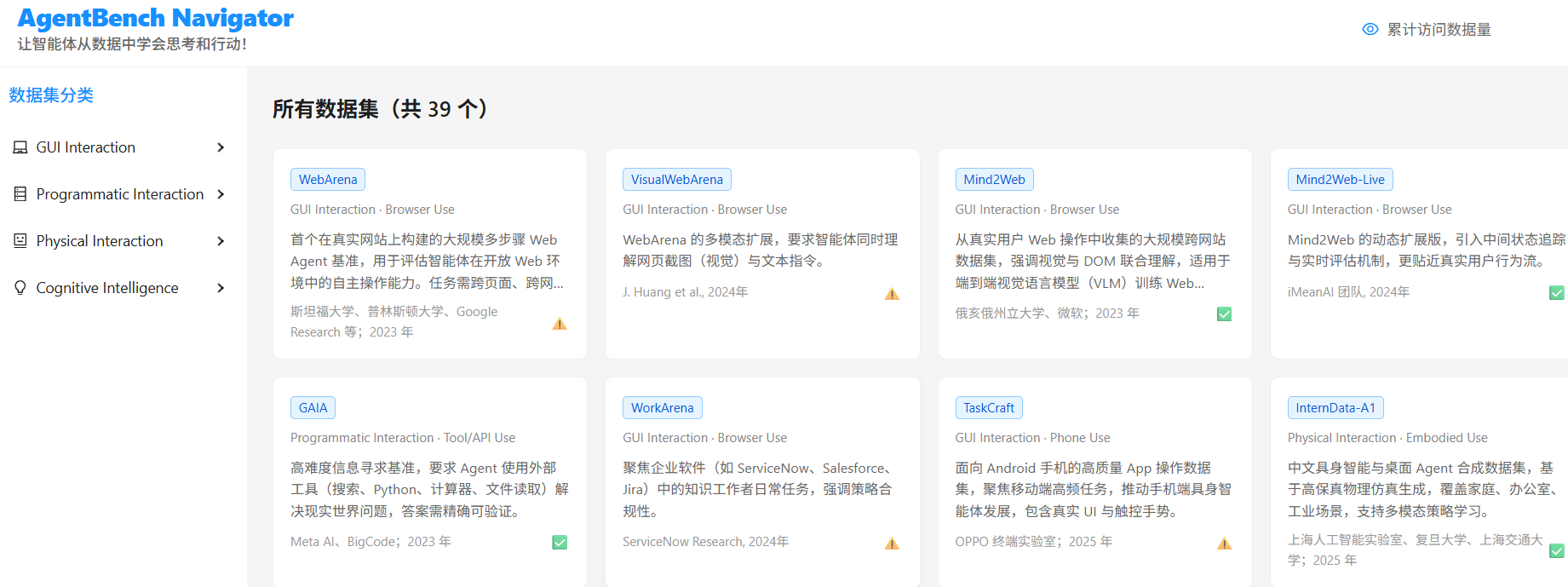
为此,我们系统梳理了 全球 39+ 主流 AI Agent 评测数据集,按 能力维度 分类整理,形成这份 《AI Agent 评测数据集全景图》,助你快速定位最适合的评估工具。

🔍 一、为什么需要结构化 Benchmark?
传统 LLM 评测(如 MMLU、HumanEval)聚焦 语言理解与代码生成,但 Agent 的核心能力远不止于此。一个真正的 Agent 需要:
| 能力维度 | 关键问题 | 对应 Benchmark |
|---|---|---|
| GUI 操作能力 | 能否像人一样点击网页按钮、填写表单? | WebArena, VisualWebArena |
| 具身智能(Embodied) | 能否在 3D 环境中导航、操作物体? | ALFWorld, VirtualHome |
| 反思与规划(Cognitive) | 能否拆解复杂任务、自我修正错误? | GAIA, SWE-bench |
| 工具调用(Tool Use) | 能否正确选择并调用 API/函数? | ToolBench, API-Bank |
| 真实世界执行 | 能否完成订票、购物等端到端任务? | WorkArena, Mind2Web |
✅ 结构化分类的意义:避免“用数学题考厨师”,确保评测任务与目标能力对齐。
🧪 二、主流 Agent 评测数据集详解
1️⃣ GUI Agent:让 Agent “看见”并操作界面
| 数据集 | 特点 | 链接 |
|---|---|---|
| WebArena | 基于真实网站(电商、Wiki)的 800+ 任务,需操作 DOM 元素 | GitHub |
| VisualWebArena (VWA) | 升级版!仅通过视觉像素操作网页,更接近人类行为 | Demo |
| Mind2Web | 从 30+ 真实网站采集的 27k 条操作轨迹,支持少样本学习 | HF Dataset |
💡 适用场景:自动化测试、RPA、浏览器 Agent 开发
2️⃣ 具身智能(Embodied Intelligence)
| 数据集 | 环境 | 任务类型 |
|---|---|---|
| ALFWorld | 家庭 3D 环境(Alfred) | “把苹果放进冰箱” |
| VirtualHome | 程序化生成的家居场景 | 多步指令执行 |
| BEHAVIOR | 高保真物理仿真 | 日常生活任务(做饭、清洁) |
⚠️ 挑战:需结合 CV + 规划 + 物理引擎,评测成本高
3️⃣ 反思规划 / 认知智能
| 数据集 | 核心能力 | 亮点 |
|---|---|---|
| GAIA | 多跳推理 + 工具调用 | 由 Meta & Hugging Face 联合发布,含 466 个现实问题 |
| SWE-bench | 软件工程修复 | 直接在 GitHub Issues 上验证 PR 是否修复 bug |
| AgentBench | 综合能力(代码/数学/游戏) | 清华大学出品,覆盖 8 类任务 |
🌟 GAIA 示例问题:
“2023 年诺贝尔物理学奖得主是谁?他/她的主要贡献是什么?”
→ 需先搜索获奖者,再检索其科研成果
4️⃣ 工具调用与 API 使用
| 数据集 | 工具数量 | 评估重点 |
|---|---|---|
| ToolBench | 16k+ APIs | 工具选择、参数生成、错误恢复 |
| API-Bank | 53 个真实 API | 医疗、金融、天气等垂直领域 |
| TaskCraft | 1.2k 复杂任务 | 多工具协同(如“查航班+订酒店+发邮件”) |
🔒 注意:部分数据集需申请权限(如 API-Bank)
🗺️ 三、如何选择合适的 Benchmark?
| 你的目标 | 推荐数据集 |
|---|---|
| 评估网页自动化能力 | WebArena 或 VisualWebArena |
| 测试复杂推理与规划 | GAIA + SWE-bench |
| 验证多工具协同 | TaskCraft 或 ToolBench |
| 构建具身 Agent | ALFWorld(轻量)或 BEHAVIOR(高保真) |
| 快速横向对比 | AgentBench(多任务集成) |
💡 建议:不要只看单一指标!结合任务成功率、步骤数、工具调用准确率综合评估。
🚀 四、开源项目推荐:Awesome Agent Benchmarks
为帮助开发者高效获取这些资源,我们开源了:
awesome-agent-benchmarks
—— 全球首个按 能力维度分类 的 Agent 评测数据集清单
✨ 项目特色:
- ✅ 覆盖 GUI / 具身 / 认知 / 工具调用 四大核心场景
- ✅ 提供 在线导航站(dataanswer.top),支持关键词搜索
- ✅ 持续更新,已收录 39+ 权威数据集
- ✅ 中英双语 README,全球开发者友好
GitHub 地址:https://github.com/dataanswer/awesome-agent-benchmarks
欢迎 Star ⭐ + 贡献新数据集!
📣 五、结语:评测驱动 Agent 进化
正如 ImageNet 推动了计算机视觉的发展,高质量、结构化的 Agent Benchmark 将是下一代 AI 突破的关键基础设施。
我们相信:
“无法测量,就无法改进。”
—— 彼得·德鲁克
希望这份全景图能成为你开发、评估、优化 AI Agent 的可靠指南。如果你有新的数据集推荐,欢迎提交 Issue 或 PR!

















 3855
3855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









