




电商实时数据分析与即席查询
基于 Kafka、Flink 和 ClickHouse 的 Kappa 架构实践
实时处理
毫秒级
数据从产生到分析延迟
查询性能
秒级
复杂即席查询响应时间
1. 引言
1.1 案例背景与目标
电商行业面临着日益激烈的市场竞争和快速变化的用户需求,实时数据分析和即席查询能力已成为企业提升运营效率、优化用户体验和驱动业务增长的关键。 传统的批处理数据分析模式难以满足实时决策的需求,例如实时监控销售业绩、即时洞察用户行为、快速响应市场变化等。
本案例旨在通过一个模拟的电商场景,展示如何利用现代大数据技术栈构建一个高效的实时数据分析与即席查询平台。 我们将重点关注如何设计一个端到端的数据流,从数据源的模拟生成,到通过消息队列进行数据采集与缓冲,再到利用流处理引擎进行实时计算与转换,最终将处理结果存储到高性能的 OLAP 数据库中,支持复杂的即席查询。核心目标是提供一个可实践的技术方案,帮助读者理解 Kappa 架构的核心思想,并掌握 Kafka、Flink 和 ClickHouse 等关键组件的应用与集成。
1.2 技术选型:Kappa 架构与核心组件
Lambda 架构是早期应对大数据实时处理需求的经典方案,它包含批处理层(Batch Layer)和速度层(Speed Layer),分别处理全量数据和增量数据,最终在服务层合并结果。然而,Lambda 架构的维护成本较高,需要维护两套代码和数据处理链路,这带来了开发和运维的复杂性 [2]。
为了解决这些问题,Kappa 架构应运而生。Kappa 架构的核心思想是简化数据处理流程,只保留流处理层,所有数据都通过流处理引擎进行处理,无论是实时数据还是历史数据的回溯处理 [33]。这种架构试图通过统一的计算引擎和单一的数据处理链路来降低系统的复杂度和维护成本。
核心组件选择
Kafka
高吞吐、可持久化的分布式消息队列,负责数据的接入和缓冲
Flink
强大的流处理引擎,具备高吞吐、低延迟、精确一次处理语义
ClickHouse
高性能的列式 OLAP 数据库,支持快速的即席查询
这种技术组合已被业界广泛验证,例如美团和唯品会均采用了类似的架构构建其实时数仓,证明了其在处理大规模实时数据方面的有效性和可靠性 [42]。
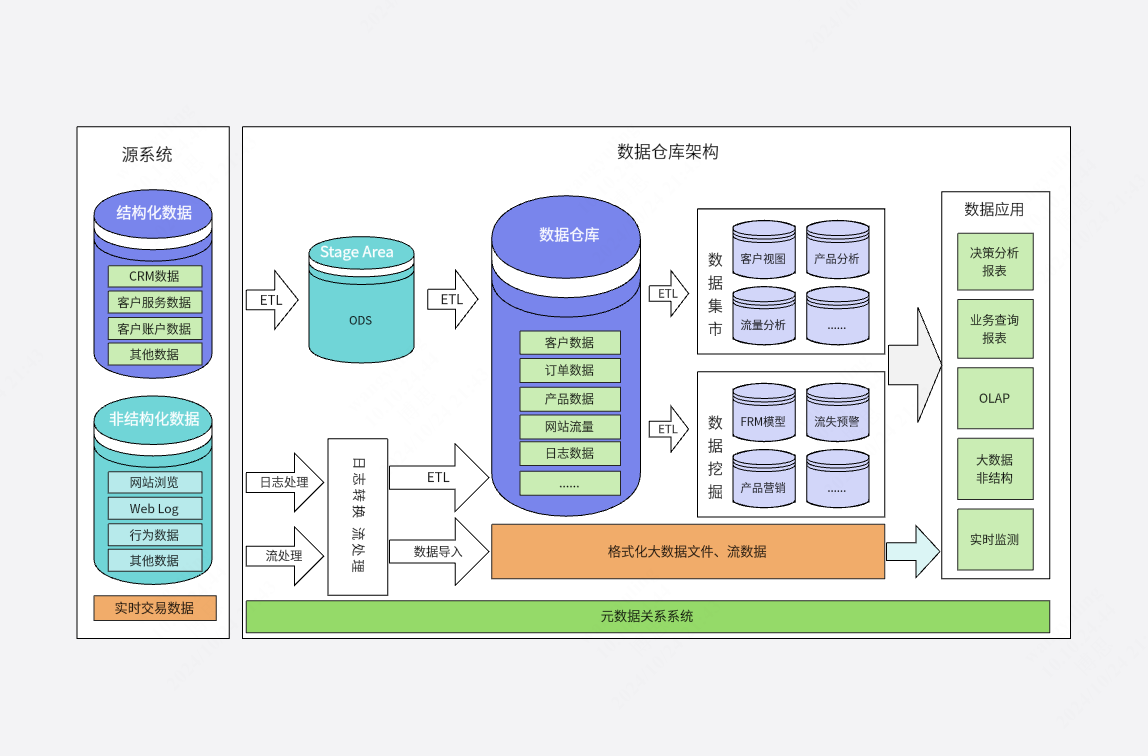
2. 整体架构设计
2.1 数据流程概览
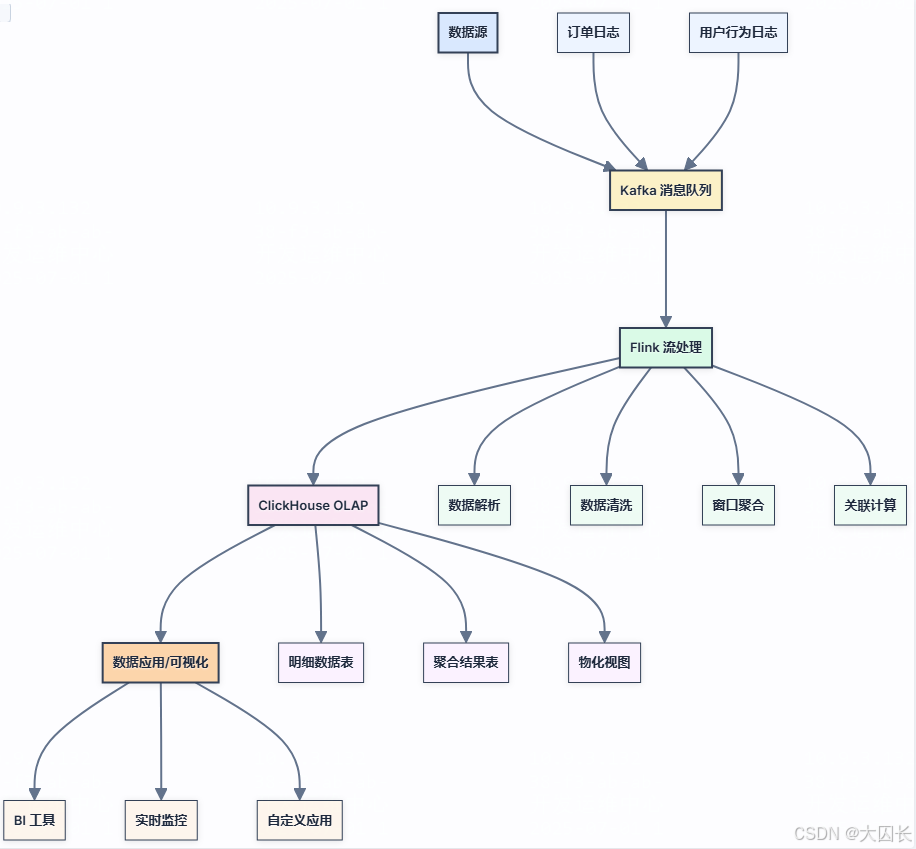
本案例的整体数据流程遵循 Kappa 架构的核心思想,以流处理为主线,实现从数据产生到实时分析与即席查询的完整链路。数据流程可以概括为以下几个主要阶段:
数据源与采集
数据源主要包括模拟的电商订单日志和用户行为日志。这些日志数据是实时产生的,包含了用户的操作行为、订单的详细信息等。
数据接入与缓冲 (Kafka)
产生的日志数据首先被发送到 Kafka 消息队列。Kafka 作为分布式、高可用的消息系统,能够有效地解耦数据生产者和消费者,并提供一个高吞吐量的数据缓冲层。
实时流处理 (Flink)
Flink 作为核心的流处理引擎,从 Kafka 中订阅相关的 Topic,消费日志数据进行实时处理。 处理逻辑包括数据的解析、清洗、转换、关联、窗口聚合等。
数据存储与 OLAP 分析 (ClickHouse)
经过 Flink 处理后的数据,将被写入 ClickHouse 数据库。ClickHouse 是一个高性能的列式 OLAP 数据库,特别适合进行快速的即席查询和复杂的数据分析 [13]。
2.2 组件职责与交互
Kafka
数据管道与持久化存储
- 数据接入与缓冲
- 数据持久化与重放
- 数据分发与负载均衡
Flink
实时数据处理与计算引擎
- 数据转换与清洗
- 窗口计算与聚合
- 数据关联与丰富
ClickHouse
OLAP 数据存储与查询引擎
- 高效列式存储
- 即席查询支持
- 聚合查询优化
3. 环境准备与配置
3.1 Kafka 集群搭建与配置

Kafka 集群的搭建和配置是构建稳定、高效数据管道的基础。以下是关键配置建议:
- 磁盘配置: 使用多块专用磁盘,通过
log.dirs配置多个目录 - 内存管理: 合理配置 JVM 堆内存,确保充足的操作系统页缓存
- Topic 规划: 根据数据特性设计合理的分区数和副本因子
3.2 Flink 环境搭建与配置
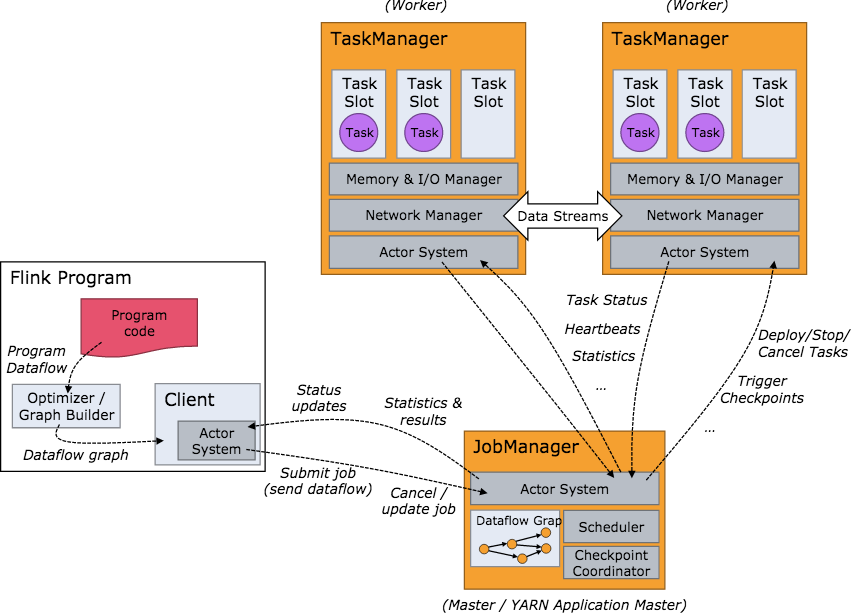
Flink 支持多种部署模式,关键组件包括 JobManager 和 TaskManager:
- 部署模式: Standalone、YARN、Kubernetes
- 状态后端: 配置 RocksDBStateBackend 支持大状态和增量 Checkpoint
- Connector 配置: 添加 Kafka 和 ClickHouse 连接器依赖
3.3 ClickHouse 集群搭建与配置

ClickHouse 采用分片和副本的分布式架构,关键配置包括:
- 表引擎选择: MergeTree 系列引擎针对 OLAP 场景优化
- 分区策略: 按时间字段合理分区减少扫描量
- 排序键设计: 基于查询模式选择合适的主键和排序键
3.4 Python 环境及相关库安装
# 安装核心依赖库
pip install confluent-kafka
pip install apache-flink
pip install clickhouse-driver
Python 作为胶水语言,用于编写数据模拟、组件交互和处理逻辑脚本,需要安装相应的客户端库。
4. 数据源与日志格式设计
4.1 模拟订单日志格式与示例
订单日志记录了用户在电商平台下单的关键信息,采用 JSON 格式进行传输,具有良好的可读性和灵活性。
{
"order_id": "ORD202305151234",
"user_id": "user789",
"order_date": "2023-05-15T11:23:45Z",
"status": "processing",
"channel": "mobile_app",
"customer_info": {
"user_name": "张三",
"user_level": "gold",
"ip_address": "192.168.1.1"
},
"items": [
{
"product_id": "SKU12345",
"product_name": "智能手机X",
"category_id": "CAT001",
"quantity": 1,
"unit_price": 549.99,
"total_price": 549.99,
"attributes": {
"color": "黑色",
"memory": "128GB"
}
}
],
"pricing": {
"subtotal": 549.99,
"shipping_fee": 9.99,
"tax": 49.50,
"discount": 20.00,
"total_amount": 589.48
},
"payment": {
"method": "credit_card",
"transaction_id": "TXN987654",
"payment_status": "completed",
"payment_time": "2023-05-15T11:25:30Z"
},
"shipping": {
"method": "standard",
"address": {
"recipient":< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









