






RAG知识库的核心评估指标包含召回率(Recall Rate),它直接反映检索系统能否全面捕捉与用户查询相关的上下文信息,是衡量RAG系统检索能力的关键维度。

一、召回率在RAG中的核心作用
-
定义与公式
召回率衡量检索系统从知识库中成功找到的相关文档数量占总相关文档数的比例,计算公式为:
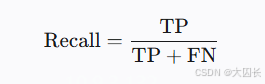
- TP(True Positives):正确检索到的相关文档数
- FN(False Negatives):未被检索到的相关文档数
例如:知识库中有10篇相关文档,系统检索到8篇,召回率为80%。
-
对生成质量的影响
- 信息完整性:高召回率确保生成模型获得充分的上下文支持,避免遗漏关键信息(如法律案例中的关键判例或医疗诊断中的治疗方案)。
- 用户体验:低召回率会导致生成答案不完整,降低用户信任(如企业知识管理系统遗漏内部流程文档)。
二、召回率的统计方法
1. 基于人工标注的标准答案
- 数据准备:需人工标注每个问题的真实答案(Ground Truth)及对应的相关文档列表。
- 计算步骤:
- 运行RAG系统获取检索结果(retrieved_documents)
- 对比检索结果与标注的相关文档(relevant_documents),统计TP和FN
- 代码示例:
# 已知相关文档:["doc1", "doc3", "doc5"] # 检索结果:["doc1", "doc2", "doc3"] tp = len({"doc1", "doc3", "doc5"} & {"doc1", "doc2", "doc3"}) # TP=2 fn = len({"doc1", "doc3", "doc5"} - {"doc1", "doc2", "doc3"}) # FN=1 recall = tp / (tp + fn) # Recall=66.7%
2. 自动化评估框架(如RAGAS)
- 上下文召回率(Context Recall):
RAGAS框架通过对比检索到的上下文与人工标注的参考答案,计算召回率。需输入:question:用户查询contexts:检索到的上下文ground_truths:标注的标准答案。
- 优点:避免全人工统计,适合大规模测试集。
三、提升召回率的实战策略
-
检索算法优化
- 语义增强模型:用DPR(Dense Passage Retrieval)替代传统TF-IDF或BM25,通过向量空间捕捉语义相似性。
- 混合检索:结合关键词匹配(召回广度)与向量检索(语义深度),覆盖更多相关文档。
-
参数调优与索引优化
- 扩大Top-K值:增加候选文档数量(如从Top-5增至Top-10),但需权衡计算成本。
- 高效索引结构:使用FAISS或HNSW加速向量检索,减少因索引误差导致的FN。
-
领域自适应训练
- 微调嵌入模型:在特定领域语料(如法律文本、医疗文献)上训练,提升对专业术语的敏感性。
- 动态查询扩展:利用知识图谱或同义词库扩展查询关键词(如将“AI医疗应用”扩展为“人工智能+医疗+诊断辅助”)。
四、召回率与其他指标的权衡
- 召回率 vs. 准确率:扩大检索范围(提高召回率)可能引入更多无关文档(降低准确率),需通过F1分数(调和平均数)或Fβ分数(β>1时侧重召回率)综合评估。
- 业务场景适配:
- 高召回优先:法律咨询、医疗诊断等容错率低的场景。
- 高准确优先:客服机器人等需快速响应的场景。
总结
召回率是RAG系统的核心指标,直接影响生成答案的完整性与可靠性。通过人工标注、自动化框架(如RAGAS)统计,并结合算法优化与参数调优,可针对性提升召回率。实际应用中需根据业务需求平衡召回率与准确率,并持续迭代检索模块以适配不同场景。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









