




 这篇博客介绍了强化学习的基本原理,包括寻找最佳函数的过程、通过与环境互动优化策略。以视频游戏和围棋为例阐述了强化学习的应用,并详细解释了机器学习的简单步骤:定义未知函数、设定损失函数及优化目标。Policy Gradient作为强化学习的一种方法,讨论了如何通过调整策略网络来控制行为,以及如何利用交叉熵损失来指导模型学习。
这篇博客介绍了强化学习的基本原理,包括寻找最佳函数的过程、通过与环境互动优化策略。以视频游戏和围棋为例阐述了强化学习的应用,并详细解释了机器学习的简单步骤:定义未知函数、设定损失函数及优化目标。Policy Gradient作为强化学习的一种方法,讨论了如何通过调整策略网络来控制行为,以及如何利用交叉熵损失来指导模型学习。
目录
1. Machine learning ~ Looking for a Function
2. Example: Playing Video Game
3. Example: Learning to play Go
4. Machine Learning is so Simple
A. What is RL ?
1. Machine learning ~ Looking for a Function
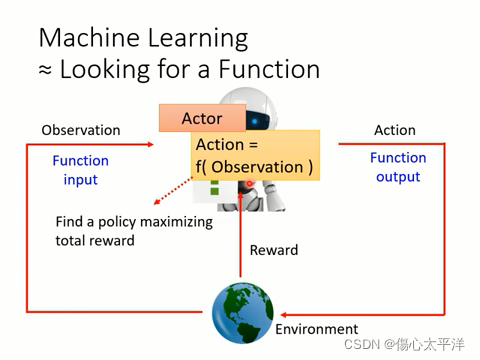
- 強化學習與一般機器學習相同,都是想找到一個最佳的函數
- 整個過程:
- Actor 從環境得到 observation
- Actor 決定根據 observation,採取 Action = f(observation)
- Action 影響了環境,使環境給予 Actor 對應的 reward
- 整個學習的過程,是希望能找到一個 policy,其在與環境互動下能得到最大的總獎勵
2. Example: Playing Video Game
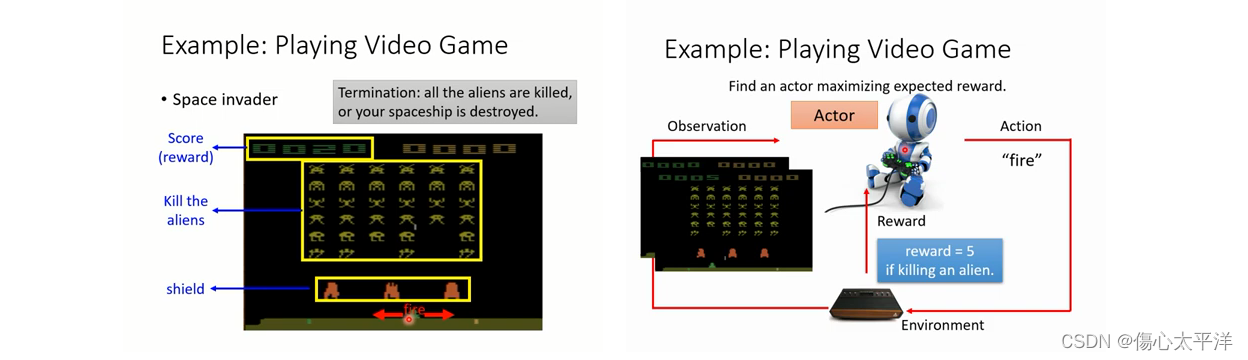
- 以 space invader 為例:
- 玩遊戲的機器人(Actor),從遊戲的畫面取得當前狀態 (observation) 後,會根據這個狀態做出操作 (action) 影響遊戲 (environment) 狀態,而遊戲也會給予相對應的獎勵 (reward)
3. Example: Learning to play Go
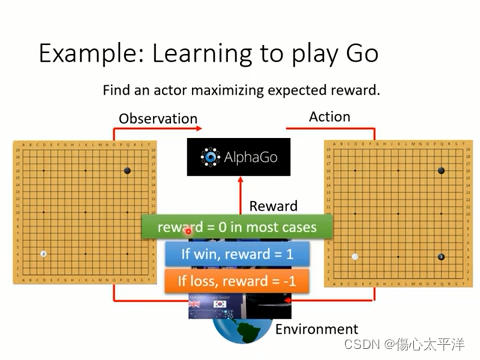
- 以下圍棋為例
- 下棋的機器人(Actor),從棋盤盤勢取得當前狀態 (observation) 後,會根據這個狀態做出下一步 (action) 影響盤勢 (environment)
- 與前面例子不同的是,每步棋的獎勵通常為 0,只在最終輸/贏時才得到相對應的獎勵 (reward)
4. Machine Learning is so Simple
Step 1. Function with unknown
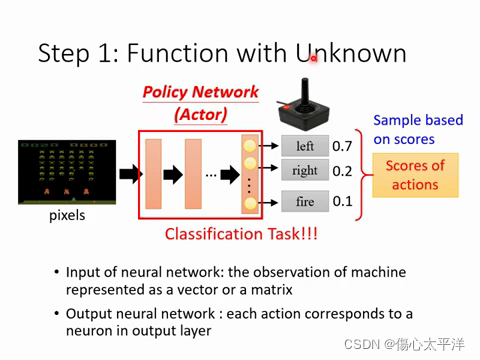
- 希望找到一個函數 (policy network),能根據輸入的遊戲觀察數據,輸出每種操作的機率分布
Step 2. Define loss
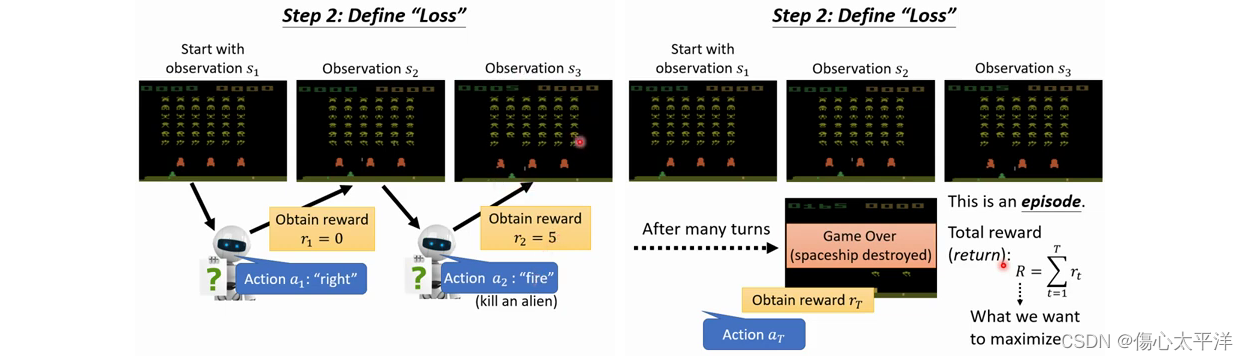
- 機器觀察畫面→產生操作→獲得獎勵,這樣的循環不斷重複著
- 直到遊戲結束,整個過程稱為一個 episode
- 機器的目標是在 episode 中,最大化獲得的獎勵
Step 3. Optimization
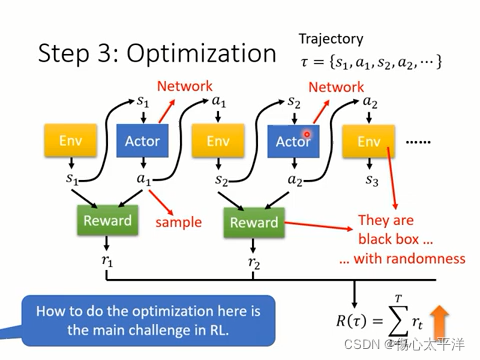
- 每個 episode 中間過程的所有 s (observation) 與 a (action),會構成 trajectory
- 整個最佳化的目標,是要最大化 trajectory 所得到的總獎勵
- 其中 a 與 s 都具有隨機性 (因為 action 是根據機率分布取樣得到,環境的狀態也具有隨機性)
- 強化學習的難點之一,在於如何最佳化函數
B. Policy Gradient
1. How to control your actor
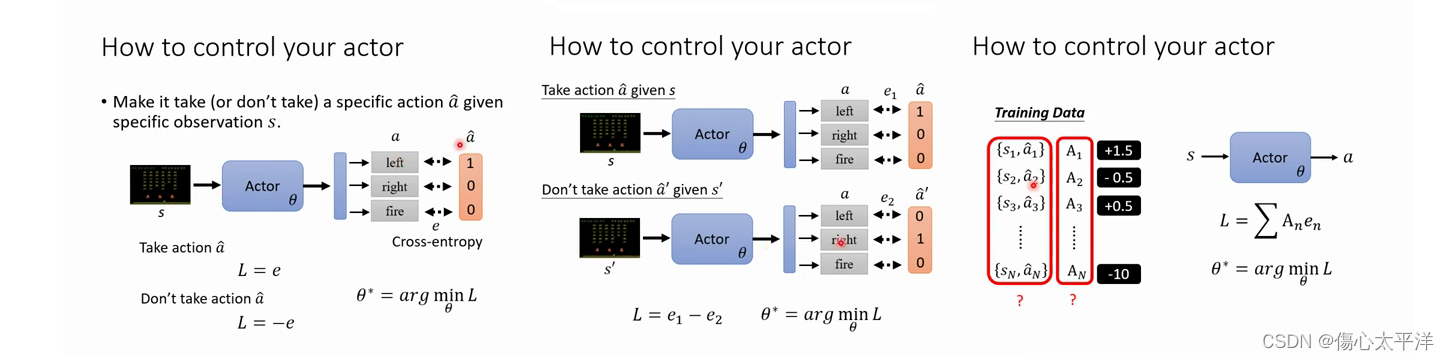
- 將 s 輸入 Actor 之後,會得到行為 a 的機率分布
- 透過我們希望 Actor 做的行為
,與 Actor 實際輸出的行為 a 機率分布,就能計算交叉熵 e
- 想利用交叉熵損失來教導 actor 要/不要做某些行為,我們可以這樣做 :
- 希望模型看到 s 時,輸出
- 希望模型看到 s 時,不要輸出
- 希望模型看到 s 時,輸出
,則令損失
即可
- 希望模型看到 s 時,輸出
- 進階一點的話,也可以考慮每個 s, a 的重要性,這時需要把
再乘上重要性



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









