



《Holistic Interaction Transformer Network for Action Detection
》,提出了用于动作检测的整体交互变压器网络(Holistic Interaction Transformer Network ,HIT),获得了ECCV DeeperAction Challenge - MultiSports 竞赛第二名。
原文链接:https://arxiv.org/abs/2210.12686
代码地址:https://github.com/joslefaure/HIT
- 方法
- 整体框架:输入视频后,利用3D骨干网络提取视频特征,通过ROIAlign技术裁剪出人物、物体和手部特征,同时借助姿态模型获取人物关键点。RGB和姿态子网络分别计算各自的特征,融合后学习全局上下文信息,最终经分类头输出动作预测结果。
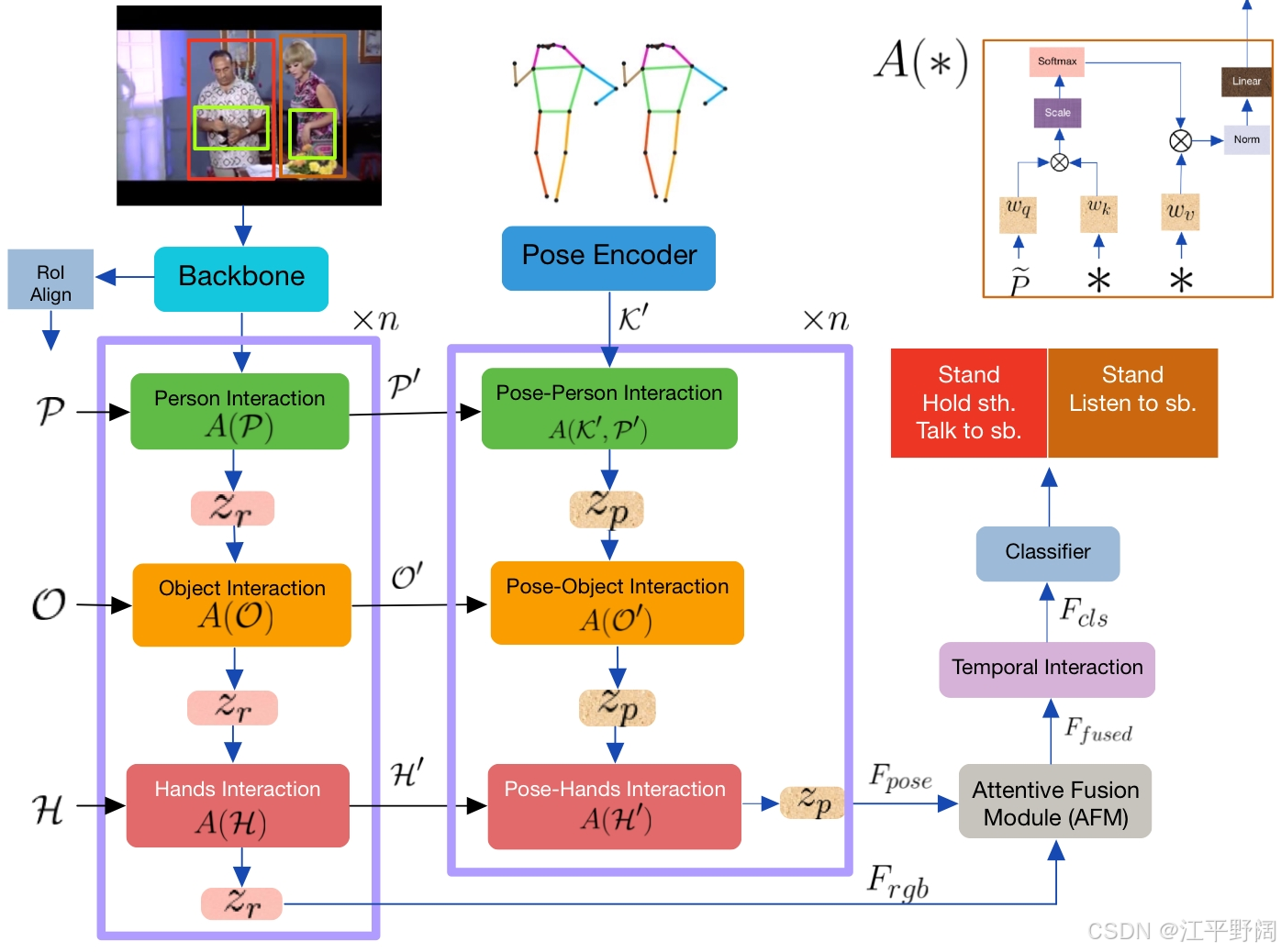
- 特征选择:人类动作很大程度上依赖于自身的姿态、手部动作以及与周围物体和其他人的互动。所以,HIT网络选择人体姿态、手部、物体和人物的边界框作为模型的实体。比如,在“拿起物体”这个动作中,人物的姿态(如身体弯曲程度、手臂伸展方向)、手部的位置和动作(如握拳、伸手),以及物体的位置和特征等信息,对于准确识别该动作至关重要。
- 利用相关检测模型确定实体位置:1)人体姿态和手部检测:采用Detectron的姿态模型来检测人体姿态。对于每个检测到的人,模型输出17个符合COCO格式的关键点。在确定手部位置时,只关注手腕的关键点,用这两个关键点创建边界框,以此突出显示手部及其相关动作区域。2)物体和人物检测:使用Faster - RCNN来计算物体的边界框。3)运用ROIAlign提取实体特征:确定实体的边界框后,使用ROIAlign技术对视频特征进行裁剪,提取出人物、物体和手部的特征。
- RGB分支和姿态分支:
- RGB分支的输入主要包括视频特征、人物特征、物体特征和手部特征。1)视频特征:给定输入视频,首先通过3D视频骨干网络提取视频特征。2)人物、物体和手部特征**:利用ROIAlign技术,从视频特征中裁剪出人物特征(P)、物体特征(O)和手部特征(H)。
- 姿态分支与 RGB 分支相似,输入为骨骼检测点,并且重用了RGB分支的部分输出。
- 注意力融合模块(AFM):将RGB和姿态流的特征进行通道拼接,再通过自注意力机制优化,进而得到融合特征。
- 时间交互单元:运用跨注意力模块,结合融合特征和记忆数据,获得包含长期上下文信息的特征,以此用于动作分类。
- 整体框架:输入视频后,利用3D骨干网络提取视频特征,通过ROIAlign技术裁剪出人物、物体和手部特征,同时借助姿态模型获取人物关键点。RGB和姿态子网络分别计算各自的特征,融合后学习全局上下文信息,最终经分类头输出动作预测结果。
- 实施细节
- 数据集:使用MultiSports数据集,其中涵盖66个细粒度动作类别,涉及4种不同运动,包含3200多个视频片段、37701个动作实例以及902k个边界框,动作标注帧率为25FPS,每个视频片段时长约22秒。
- 骨干网络:采用在Kinetics-700数据集上预训练的SlowFast R101模型。
- 检测模型:人物和物体检测分别使用特定的Faster R-CNN模型;关键点检测采用Detectron的姿态模型,并对检测到的姿态坐标进行后处理。
- 训练和评估:输入视频片段采样64帧,设置相关训练参数,采用随机抖动增强等手段。使用SGD优化器,在8个GPU上进行训练,设置学习率调整策略。推理时设定置信度阈值,使用Softmax focal loss作为分类器的激活函数,输出帧检测结果并创建动作管。
- 消融实验:在J-HMDB数据集上开展实验,验证了网络层数、AFM、模态内聚合器等组件的有效性。例如,两层网络结构效果较好,增加到三层会导致过拟合;AFM在融合特征方面优于Sum、Concat等其他方法。
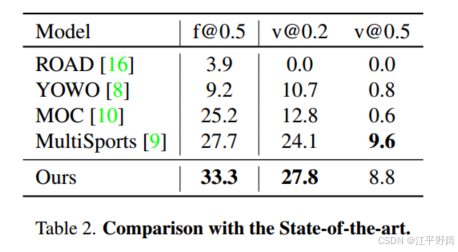
- 结果:在MultiSports数据集的验证集上,该方法在帧平均精度均值(mAP)和视频mAP指标上超越了其他方法。

















 598
598



 到【灌水乐园】发言
到【灌水乐园】发言








