







第二章: 机器学习与神经网络概述
第二部分:降维算法理论与实践
第一节:主成分分析(Principal Component Analysis, PCA)
内容:协方差矩阵、特征值分解、数据降维。
PCA 是一种经典的线性降维方法,通过找到数据中最重要的方向(主成分),在最大限度保留原始数据信息的前提下,降低维度、去除冗余,常用于数据压缩、可视化、去噪等任务。
一、核心思想
PCA 旨在找到一组新的正交基(主成分),使得原始数据在这些基下的投影具有最大的方差(也即信息量最大)。
二、步骤详解
数据标准化(去中心化)
确保每个特征维度均值为 0:
其中 μ 是每列(特征)的平均值。
计算协方差矩阵
该矩阵反映了各特征之间的线性相关性。
求协方差矩阵的特征值与特征向量
-
特征向量(v)是新的坐标轴方向;
-
特征值(λ)表示沿该方向的数据方差大小。
选择前 k 个最大特征值对应的特征向量
构成变换矩阵 ,用于投影降维。
变换数据
得到降维后的数据。

上图展示了 Iris 数据集标准化后特征的协方差矩阵 热力图:
-
对角线表示各特征自身的方差(均为 1,因为已标准化);
-
非对角线反映特征之间的线性相关性:
-
正值表示正相关,例如“花瓣长度”和“花瓣宽度”;
-
负值或接近 0 表示负相关或无明显线性关系;
-
-
可据此判断哪些维度信息冗余,有助于降维(如 PCA)时选择保留主成分。
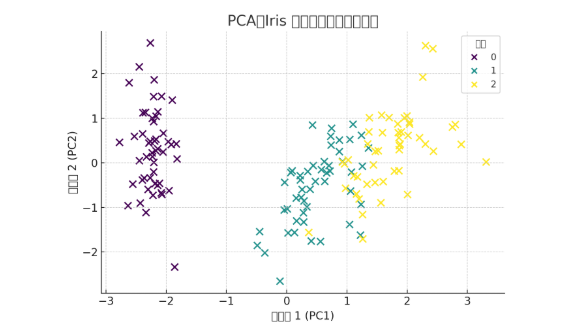
上图展示了 Iris 数据集使用 PCA 降维到二维后的投影结果:
-
不同颜色表示不同类别的花(setosa、versicolor、virginica);
-
PCA 将原始四维特征(花萼/花瓣长度与宽度)压缩到两个主成分(PC1 与 PC2);
-
我们可以清晰地看到:第一主成分很好地区分了类别,说明其携带了大量判别性信息。
三、可视化理解
-
每个主成分是一个最大化投影方差的方向;
-
第一个主成分最大化全局方差;
-
第二个主成分与第一个正交,最大化剩余方差。
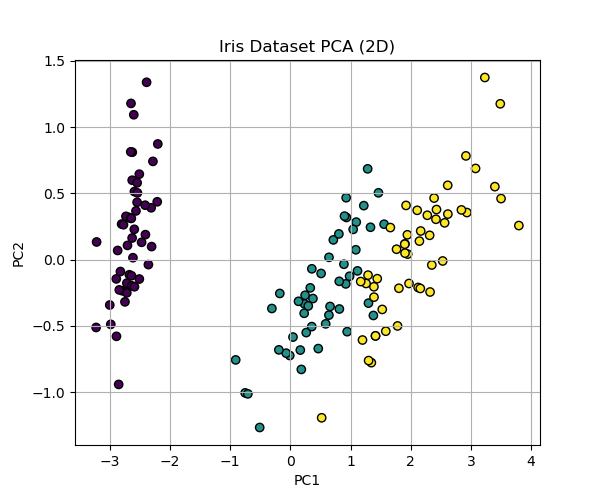
四、示例代码(基于 scikit-learn)
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载数据
data = load_iris()
X = data.data
y = data.target
# PCA降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化
plt.figure(figsize=(6, 5))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolor='k')
plt.title("Iris Dataset PCA (2D)")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.grid(True)
plt.show()
五、注意事项
-
PCA 是无监督学习方法;
-
对特征量纲敏感,必须标准化;
-
仅捕捉线性结构,对非线性结构效果差(可考虑 Kernel PCA)。
六、常见应用
-
数据压缩(例如图像压缩)
-
数据可视化(2D 或 3D 展示高维数据)
-
去噪(保留前几主成分,去掉小特征值部分)
-
特征提取(机器学习模型的前置处理)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









