








 超级会员免费看
超级会员免费看

 本文介绍了Prometheus的Web UI界面,包括访问方式、主要页面如Alerts、Graph、Status和Help的功能详解,以及如何在Web UI上查询指标、查看告警信息和系统状态。在实际工作中,Prometheus常与Grafana结合,用于数据可视化。
本文介绍了Prometheus的Web UI界面,包括访问方式、主要页面如Alerts、Graph、Status和Help的功能详解,以及如何在Web UI上查询指标、查看告警信息和系统状态。在实际工作中,Prometheus常与Grafana结合,用于数据可视化。
平凡也就两个字: 懒和惰;
成功也就两个字: 苦和勤;
优秀也就两个字: 你和我。
跟着我从0学习JAVA、spring全家桶和linux运维等知识,带你从懵懂少年走向人生巅峰,迎娶白富美!
关注微信公众号【 IT特靠谱 】,每天都会分享技术心得~
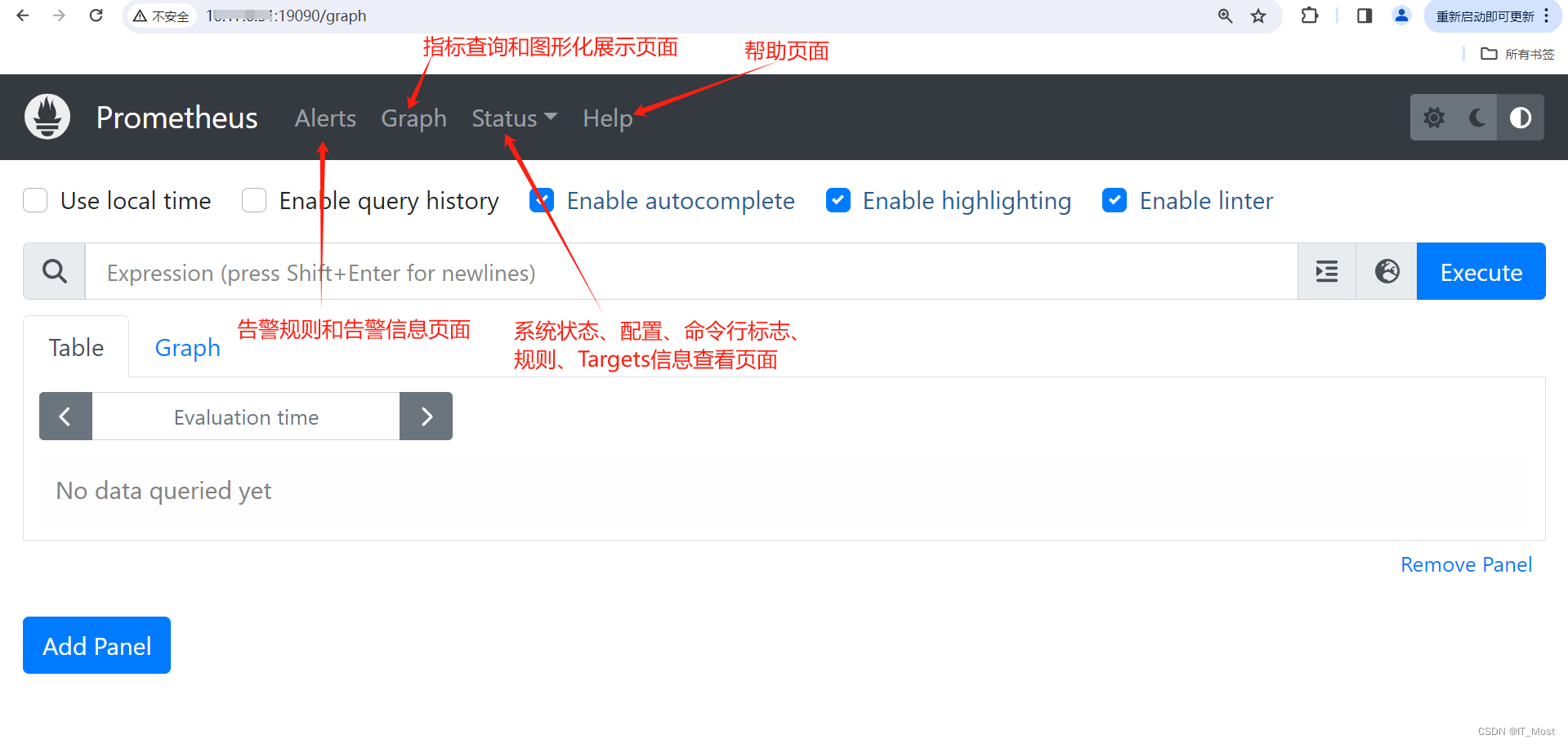
1.认识Prometheus的Web UI界面
1.1.访问Web UI界面
启动Prometheus服务后,我们可访问Prometheus自带的Web UI界面。
自带的Web UI访问地址为:http://ip:port/graph

1.2.认识Web UI界面
Prometheus内置一个简单的Web控制台。Web控制台页面主要包含4个子页面:
(1)Alerts页面
告警规则和告警信息页面。可查看告警规则和正在进行的不同状态的告警信息。
(2)Graph页面
指标查询和图形化展示页面。可查询PromeQL表达式值,以图表或折线图的方式进行可视化展示。
(3)Status页面
状态页面。可查看Prometheus运行和构建信息、TSDB时序数据库状态、命令行标志、系统配置、规则、Targets和Service Discovery等。
(4)Help页面
帮助页面。可直接打开Prometheus官方文档(Prometheus官方帮助文档)。
在Web UI控制台上,我们可以:
(1)查询指标。
(2)以图表或折线图的方式展示查询的指标值。
(3)查看告警信息。如:告警规则和告警状态。
(4)查看系统状态信息。如:Prometheus运行和构建信息、TSDB时序数据库状态、命令行标志、系统配置、规则、Targets和Service Discovery。
实际工作中,我们通常搭配Grafana或自研的Web UI作为可视化工具进行使用。Prometheus作为Grafana或自研Web UI的数据源,Gragana或Web UI可视化工具显示的指标数据通过Prometheus提供的HTTP API接口进行查询获取。
1.2.1.Alerts页面
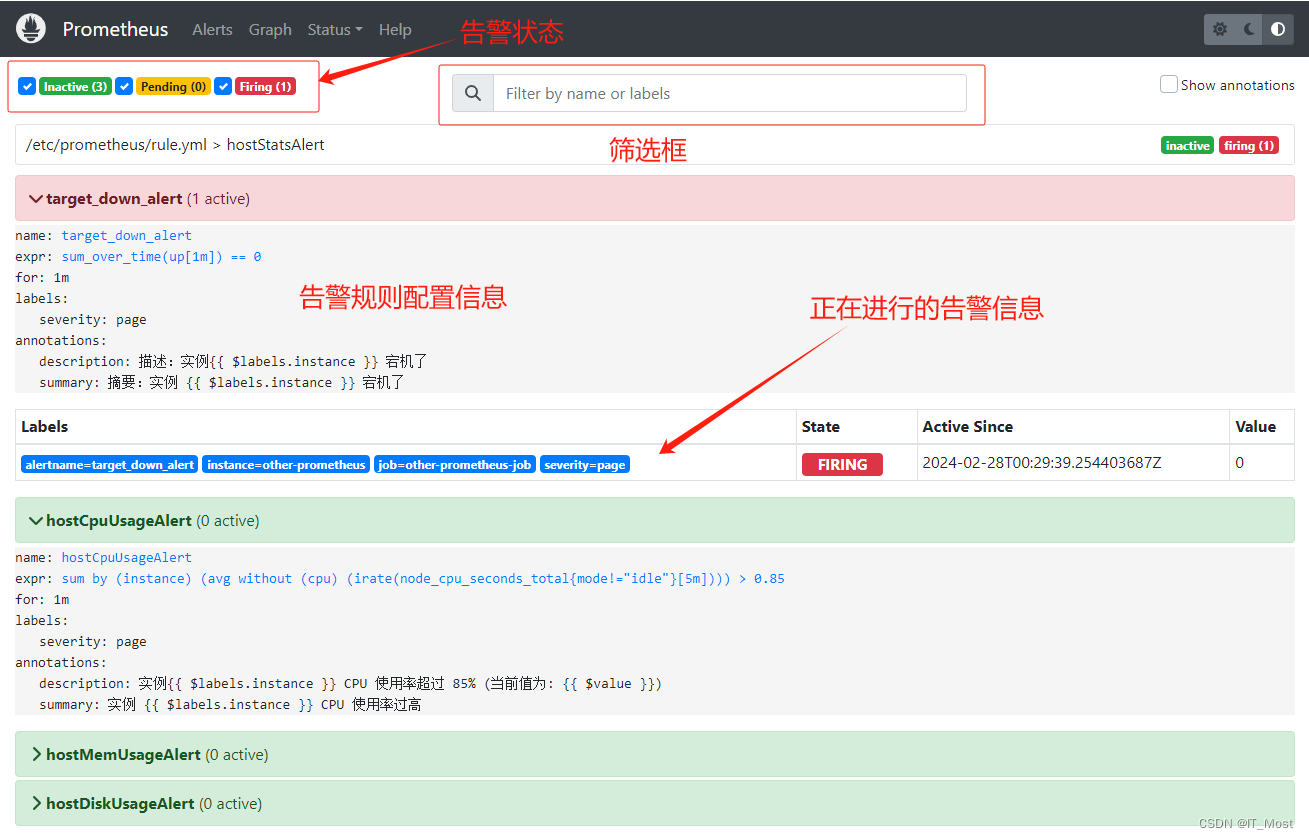
(1)告警状态
上图表示系统中总共配置有4条告警规则:target_down_alert、hostCpuUsageAlert、hostMemUsageAlert 和hostDiskUsageAlert。其中标签为{instance="other-prometheus", job="other-prometheus-job"}的target实例触发了target_down_alert告警规则。
Prometheus告警规则的状态有三种:
| 告警规则的状态 | 状态 |
| Inactive | 非活动状态。 表示正在监控,但是还未有触发任何告警。若触发告警,则将状态转为Pending。 |
| Pending | 正在告警,且暂未将警报发送到AlertManager。 由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing状态。 |
| Firing | 正在告警,且已将警报发送到AlertManager。 它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到Inactive,如此循环。 |
(2)筛选框
可以根据规则名称和标签过滤并查看告警规则。
(3)告警规则信息
展开具体的告警规则,可以查看到“/etc/prometheus/rule.yml”规则配置文件中配置的规则信息。
(4)正在进行的告警记录
若某些target满足了某告警规则的触发条件,则可展开该告警规则,查看到哪些标签的target触发了告警(Labels)、查看告警状态(State)、告警开始时间(Active Since)、告警规则表达式计算的值(Value)。
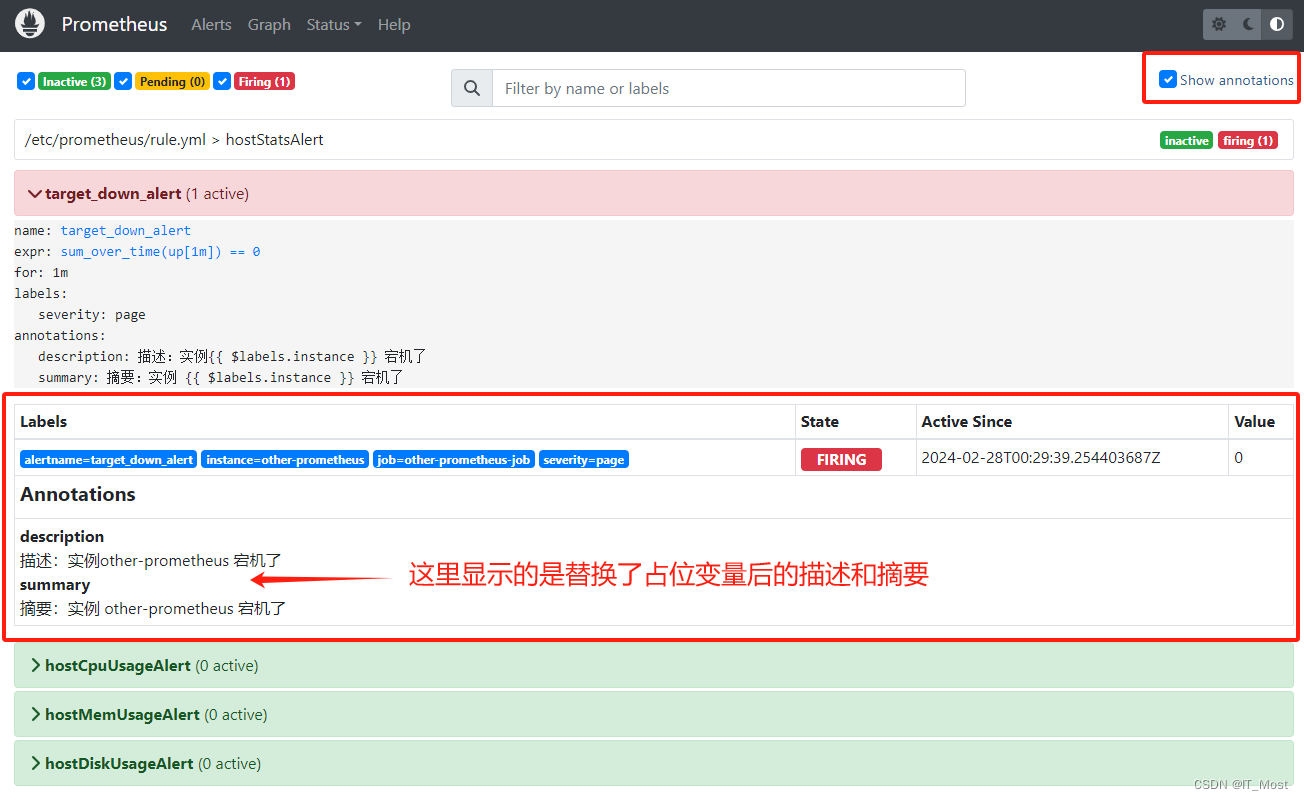
若勾选了“Show annotations”选项,则在告警下可以查看到替换占位变量(如:{{ $labels.instance }} )后的描述信息,如:
1.2.2.Graph页面
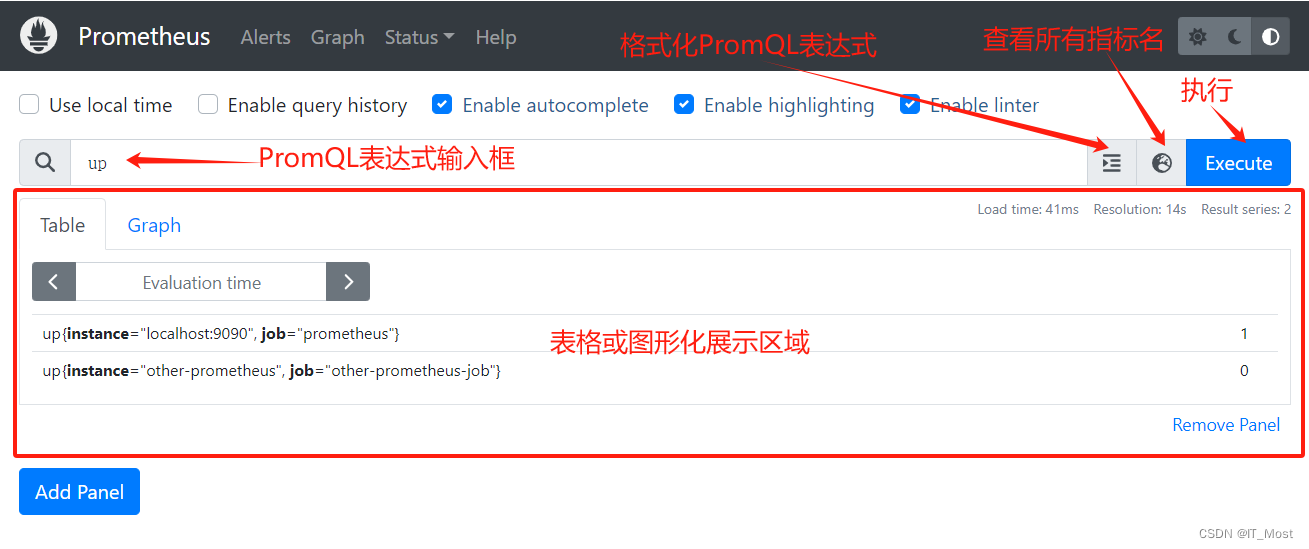
(1)功能选项开关
| 功能选项 | 描述 |
| Use local time | 使用当地时间 |
| Enable query history | 开启查询历史 |
| Enable auto complete | 开启自动提交 |
| Enable highlighting | 开启高亮显示 |
| Enable linter | 开启提示功能 |
(2)PromQl表达式输入框
可在此输入框中输入任意的PromQL表达式,点击“Execute”按钮即可查询表达式的结果。
(3)格式化PromQL表达式按钮
点击该按钮,即可格式化或美化输入的PromQL表达式。实际调用的是“/api/v1/format_query”API接口。
(4)查看所有指标名按钮
点击该按钮,即可查看Promtheus时序数据库中的所有指标名称。实际调用的是“/api/v1/label/__name__/values”API接口。
(5)表格或图形化展示区域
可对PromQL表达式的结果按表格或曲线图的方式进行展示。
Table表格可以展示PromQL表达式为即时向量和范围向量结果集;但是Graph曲线图仅能展示PromQL表达式为即时向量的结果集。
1.2.3.Status页面
Status页面可以查看系统的状态信息,包括:Prometheus运行和构建信息、TSDB时序数据库状态、命令行标志、系统配置、规则、Targets和Service Discovery。
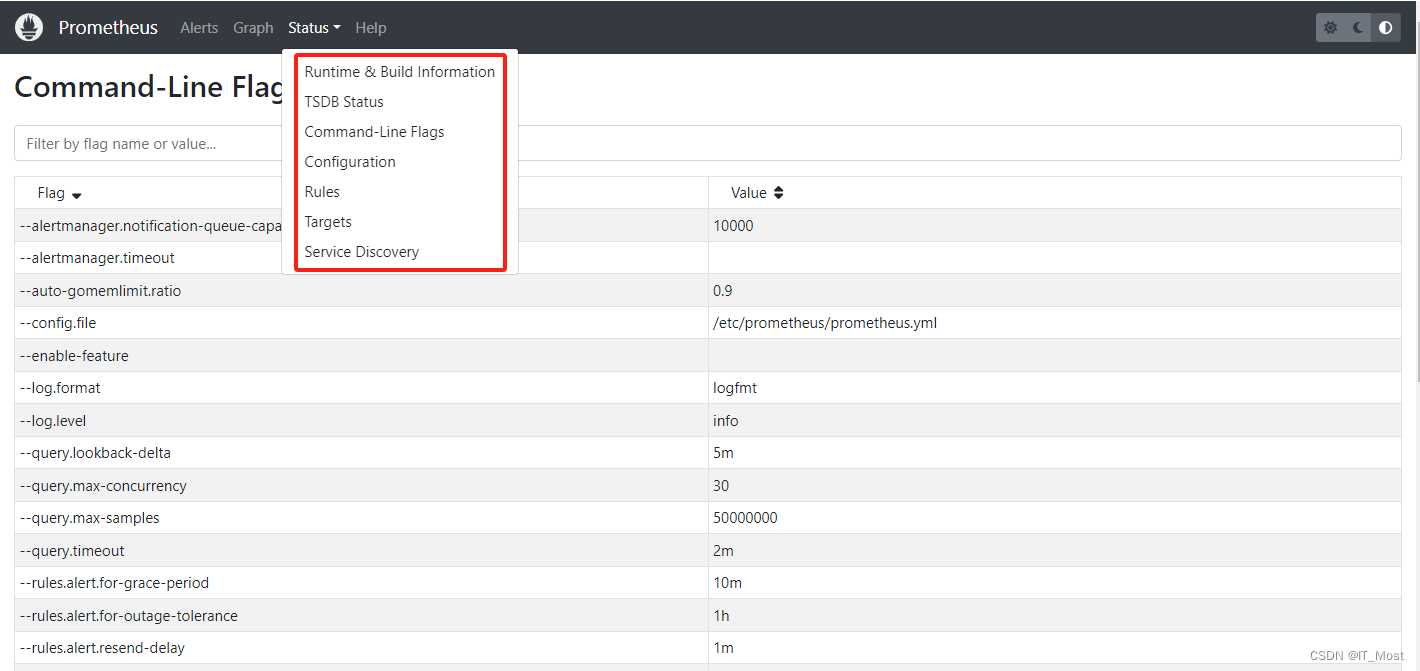
(1)Runtime & Build Information
可查看Prometheus运行时信息(Prometheus启动时间、配置加载状态和存储数据的保留天数等)、构建信息(Prometheus版本、分支和构建人信息等)、告警管理器。
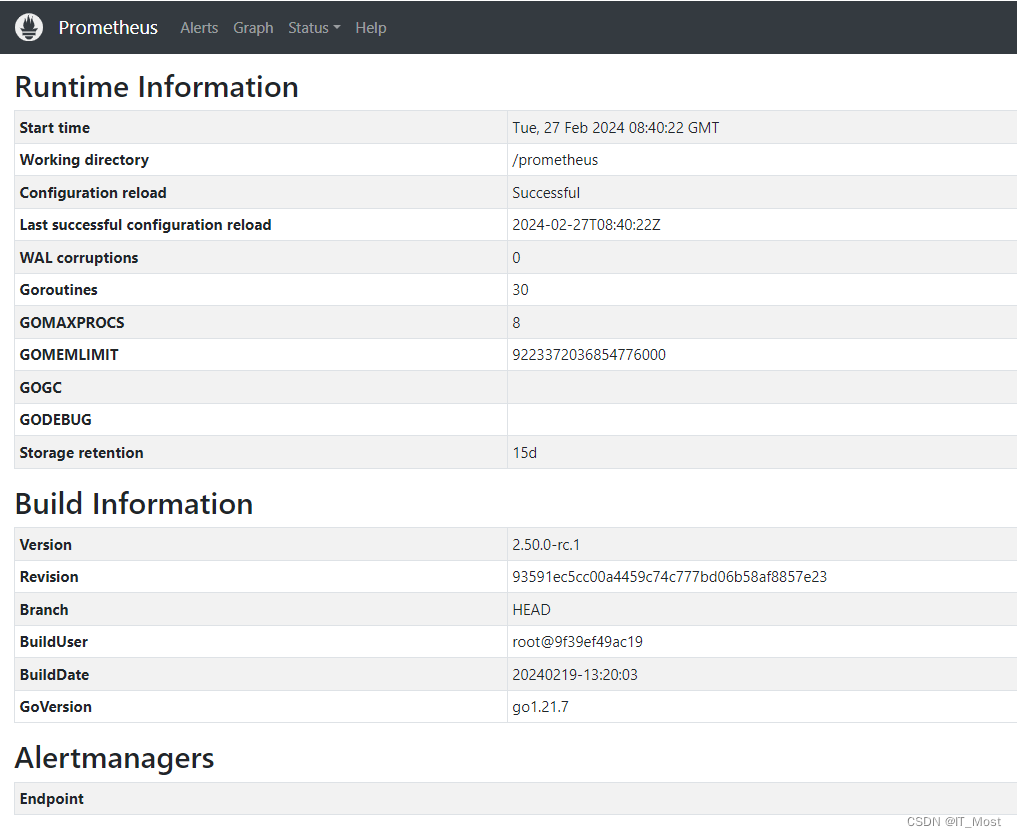
(2)TSDB Status
可查看TSDB时序数据库的状态信息(时序的数量、标签对的数量等)、对的TOP10统计信息(前10的标签名称、前10的指标名称,内存占用前10的标签、前10的标签键值对)等。
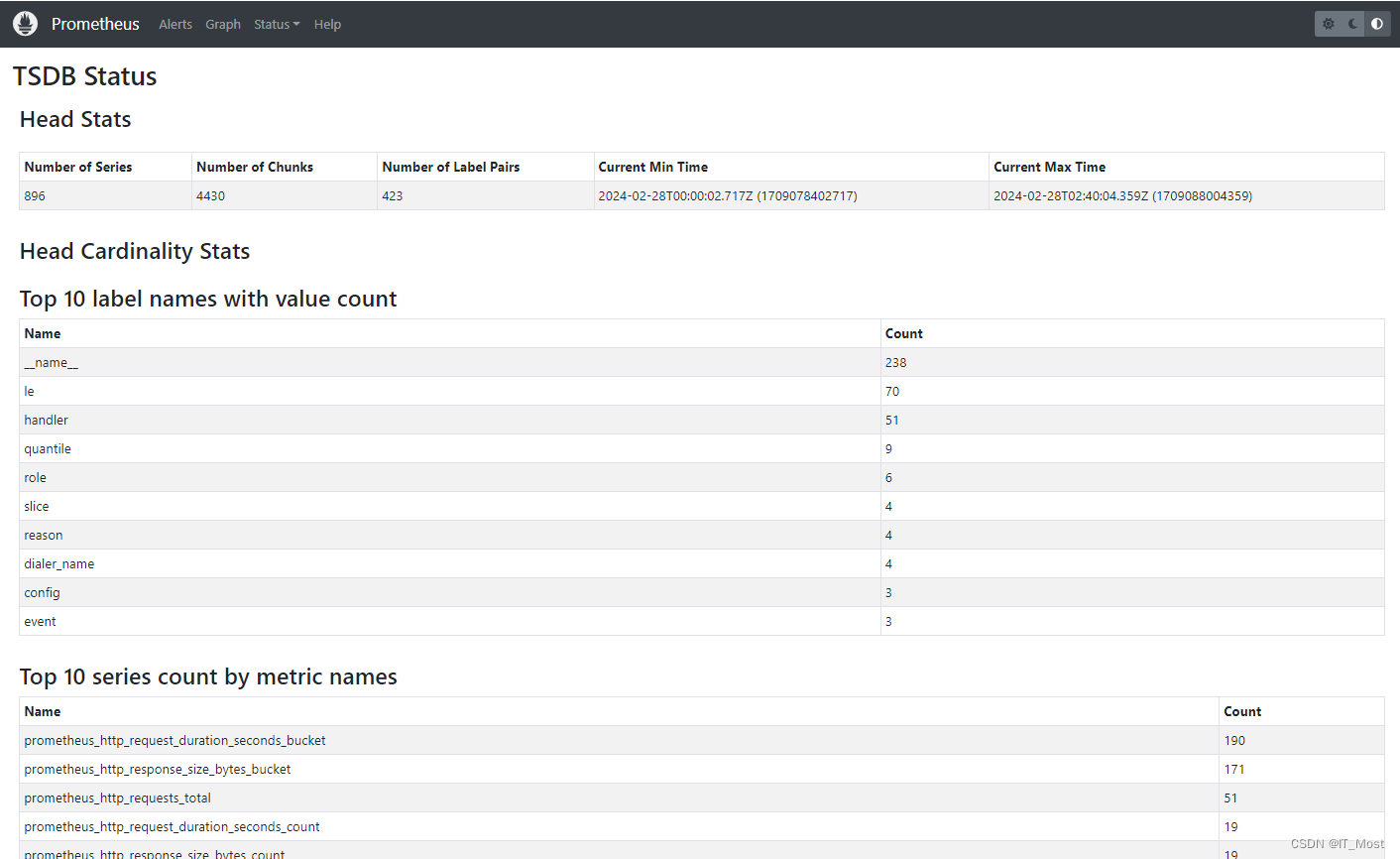
(3)Command-Line Flags
可查看系统的所有命令行标志参数值。
查看所有的命令标志的帮助命令:进入容器的“/bin”下执行“./prometheus -h”。帮助信息中可以看到所有命令行标志参数及参数描述。
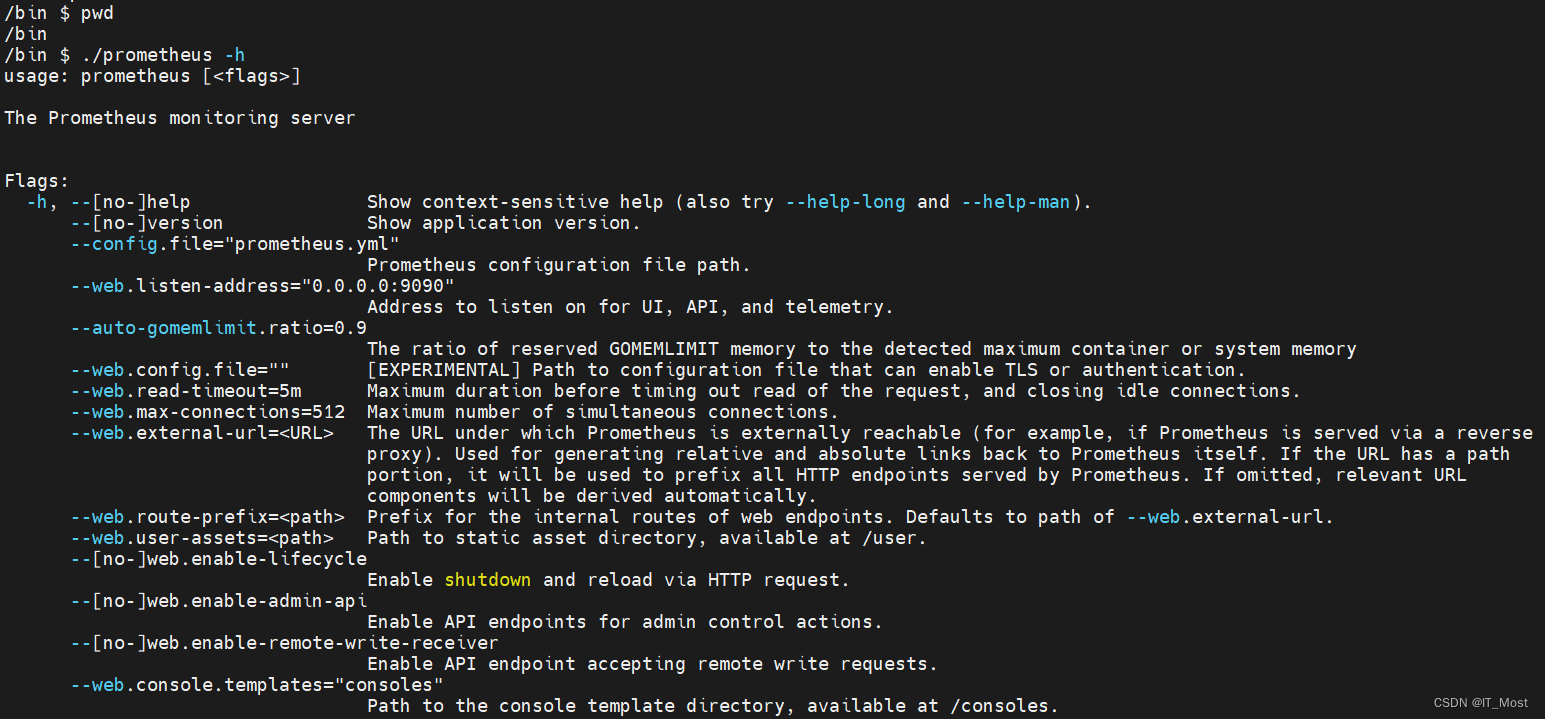
所有命令行标志参数都有一个默认值,我们可以在启动Prometheus服务的时候修改某些命令行标志参数值,如:
#启动prometheus服务
./bin/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus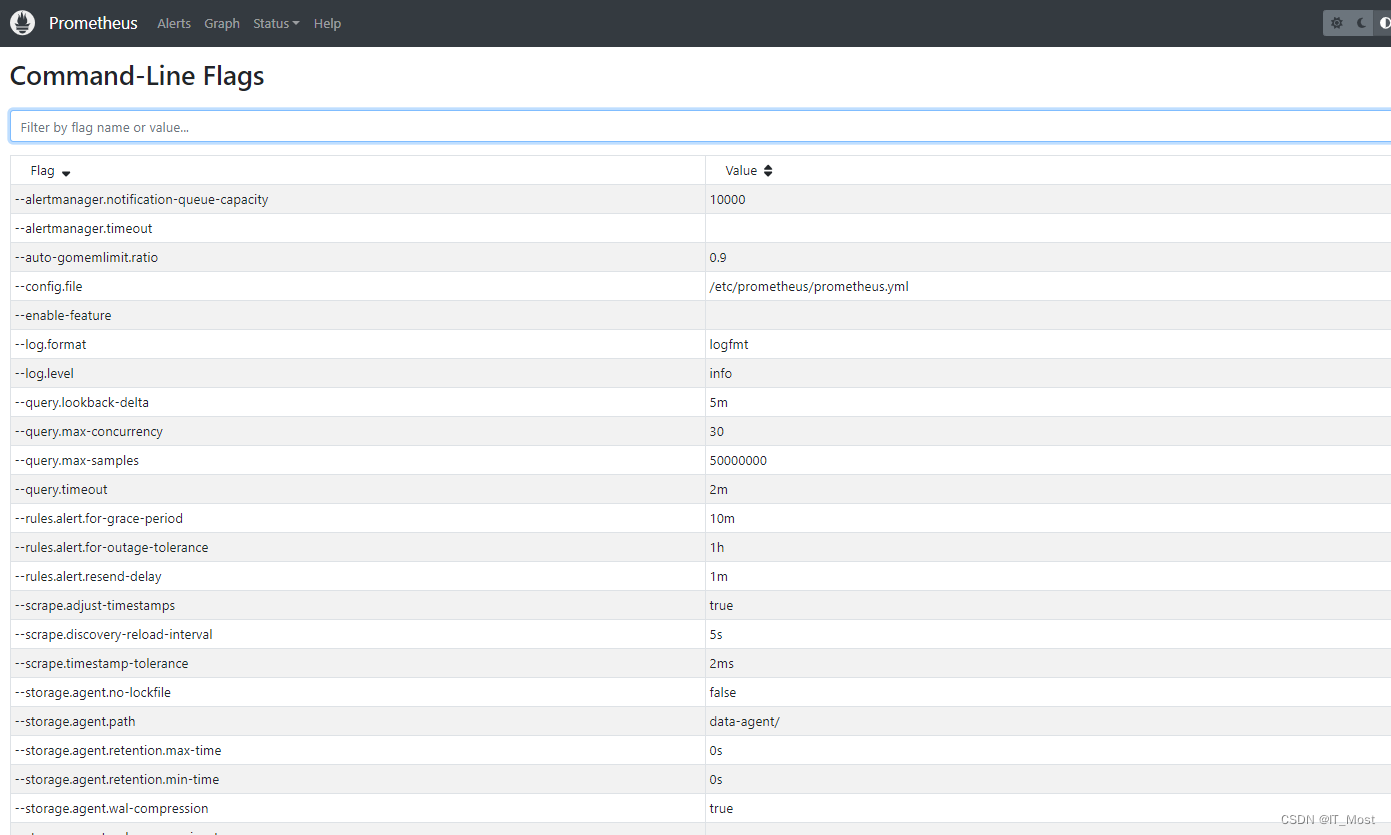
(4)Configuration
可查看所有已生效的配置信息。其中“basic_auth.password”进行了脱敏显示,其它参数原样显示。
该配置信息来源于“--config.file=/etc/prometheus/prometheus.yml”命令行标志参数指定的prometheus.yml配置文件中。具体如何配置,后面章节详细介绍!
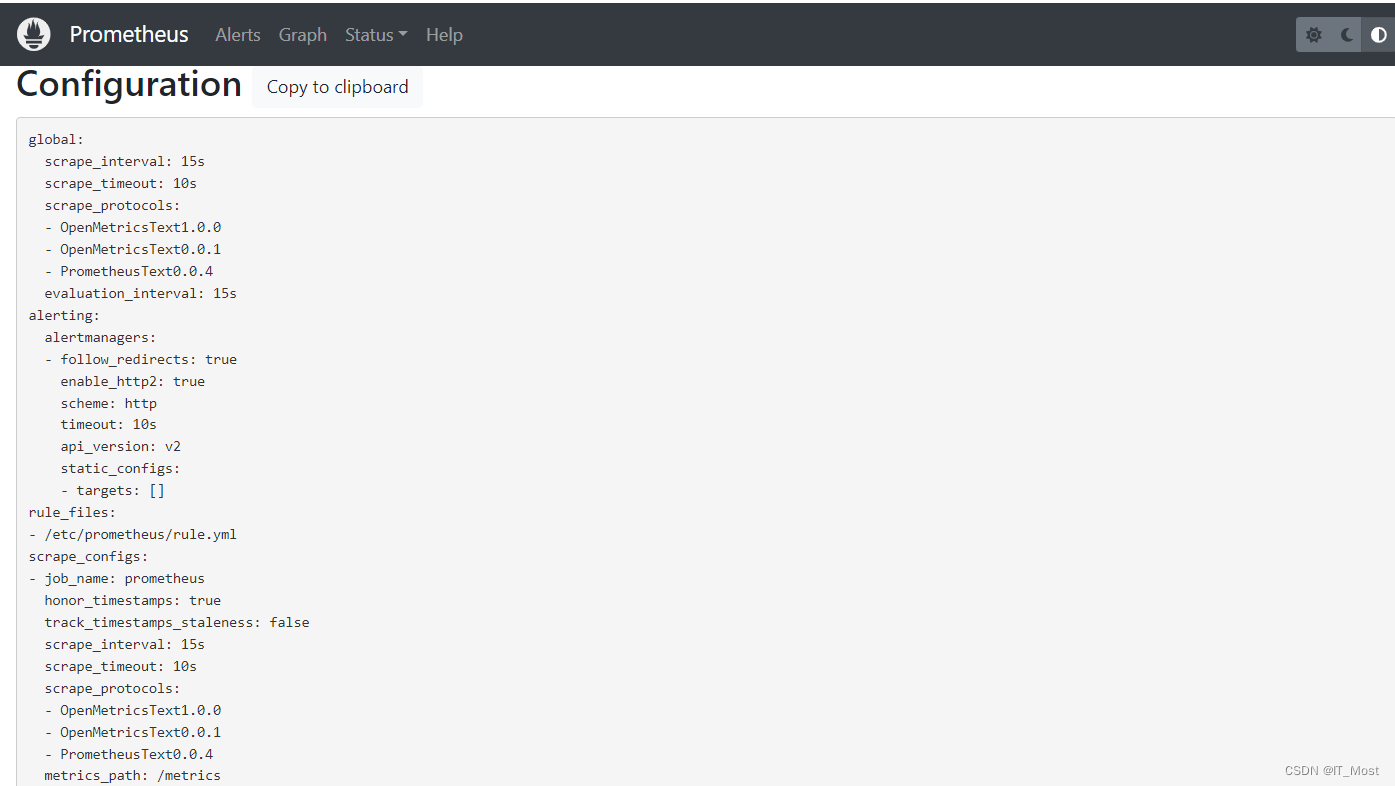

本示例中,prometheus.yml配置内容如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/etc/prometheus/rule.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
basic_auth:
username: admin
password: abc123
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: other-prometheus-job
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
basic_auth:
username: admin
password: abc123
follow_redirects: true
static_configs:
- targets:
- 10.17.0.80:39093
labels:
instance: other-prometheus(5)Rules
可查看系统中已配置的所有规则信息。
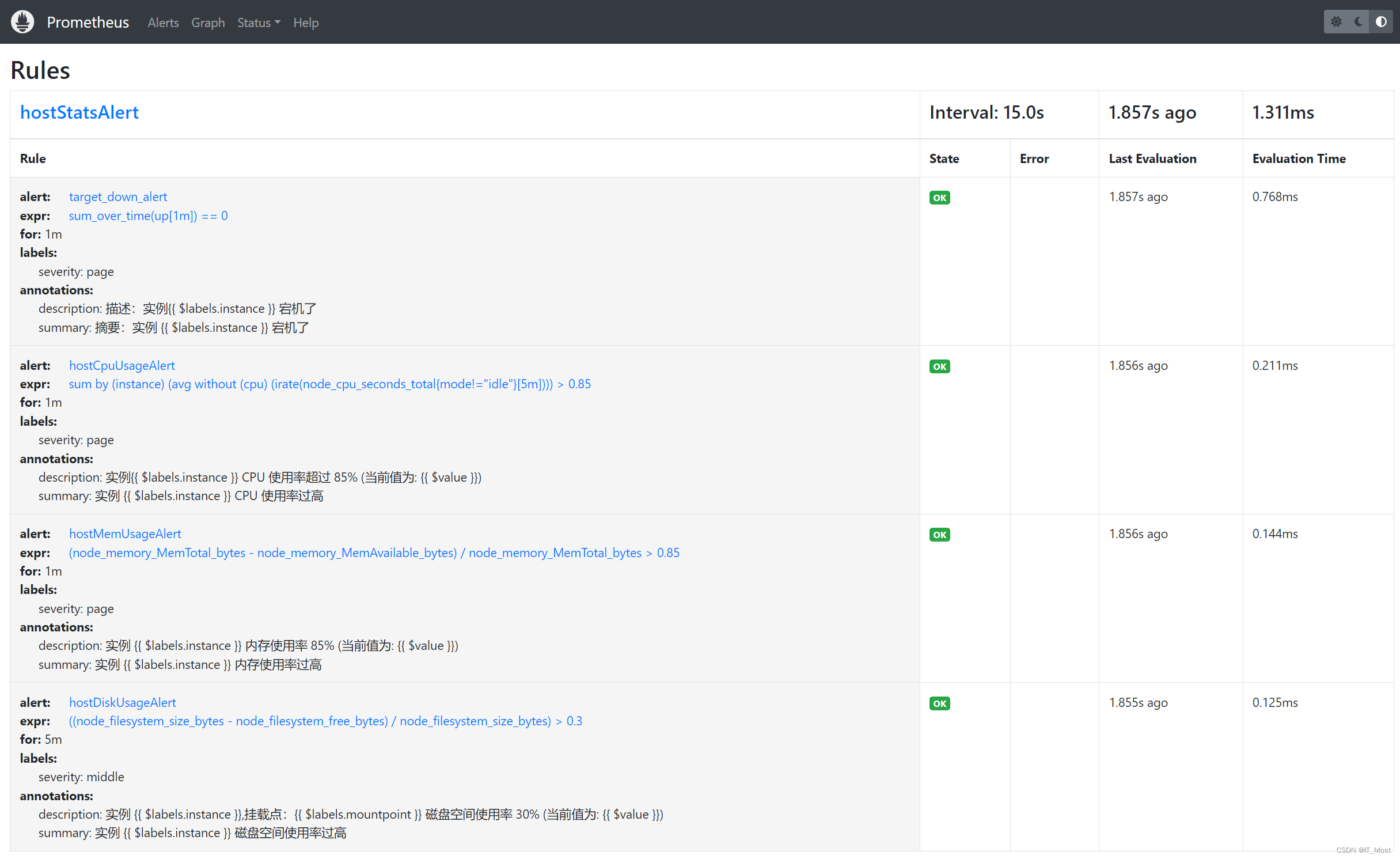
规则配置文件路径通过“/etc/prometheus/prometheus.yml”配置文件中的“rule_files”参数指定。系统会每隔“evaluation_interval”时间计算一次规则表达式值,并根据规则文件的持续时间规则判断是否触发了告警规则,判断哪些实例触发了告警规则,若触发告警规则则进行告警状态变更和告警信息通知。
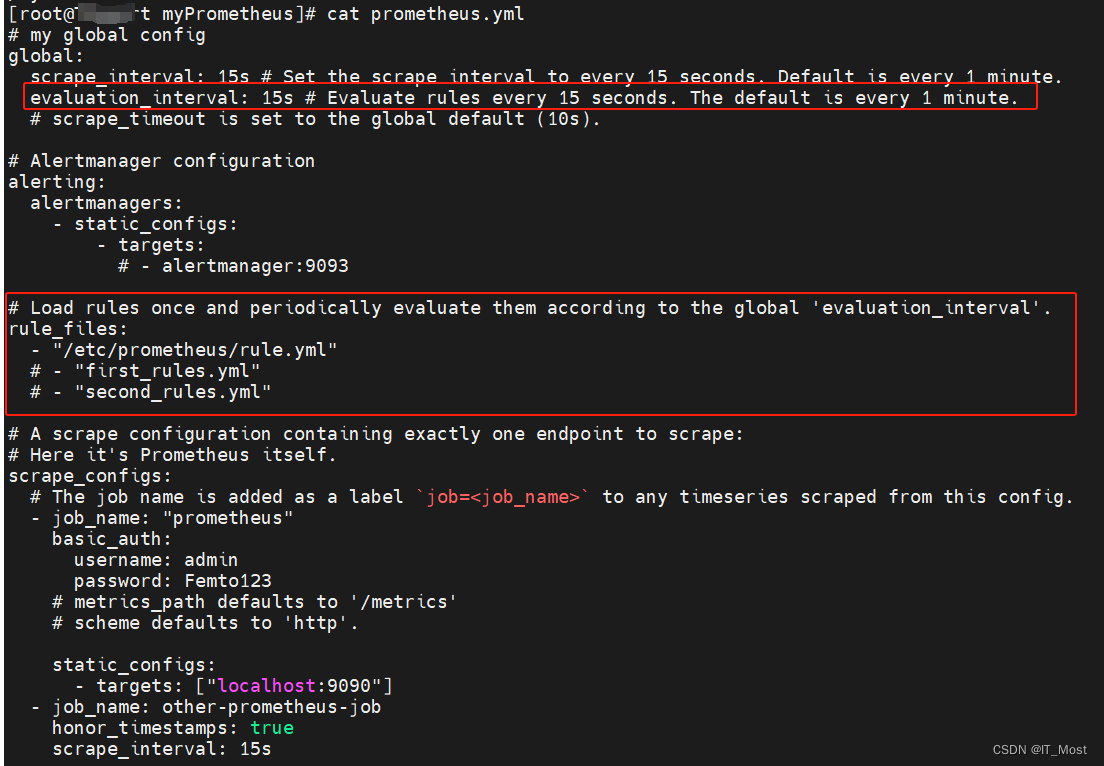
本示例的规则文件(Rule.yml)内容如下:
groups:
# 报警组组名称
- name: hostStatsAlert
#报警组规则
rules:
#告警名称,需唯一
- alert: target_down_alert
#promQL表达式
expr: sum_over_time(up[1m]) == 0
#满足此表达式持续时间超过for规定的时间才会触发此报警
for: 1m
labels:
#严重级别
severity: page
annotations:
#发出的告警标题
summary: "摘要:实例 {{ $labels.instance }} 宕机了"
#发出的告警内容
description: "描述:实例{{ $labels.instance }} 宕机了"
- alert: hostCpuUsageAlert
#promQL表达式
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.85
#满足此表达式持续时间超过for规定的时间才会触发此报警
for: 1m
labels:
#严重级别
severity: page
annotations:
#发出的告警标题
summary: "实例 {{ $labels.instance }} CPU 使用率过高"
#发出的告警内容
description: "实例{{ $labels.instance }} CPU 使用率超过 85% (当前值为: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "实例 {{ $labels.instance }} 内存使用率过高"
description: "实例 {{ $labels.instance }} 内存使用率 85% (当前值为: {{ $value }})"
- alert: hostDiskUsageAlert
expr: ((node_filesystem_size_bytes - node_filesystem_free_bytes ) / node_filesystem_size_bytes ) > 0.30
for: 5m
labels:
severity: middle
annotations:
summary: "实例 {{ $labels.instance }} 磁盘空间使用率过高"
description: "实例 {{ $labels.instance }},挂载点:{{ $labels.mountpoint }} 磁盘空间使用率 30% (当前值为: {{ $value }})"(6)Targets
可查看当前Prometheus服务监控的各个Target的信息(如:Endpoint、状态、标签、上次pull抓取数据时间,抓取数据耗时,抓取数据时异常信息等)。
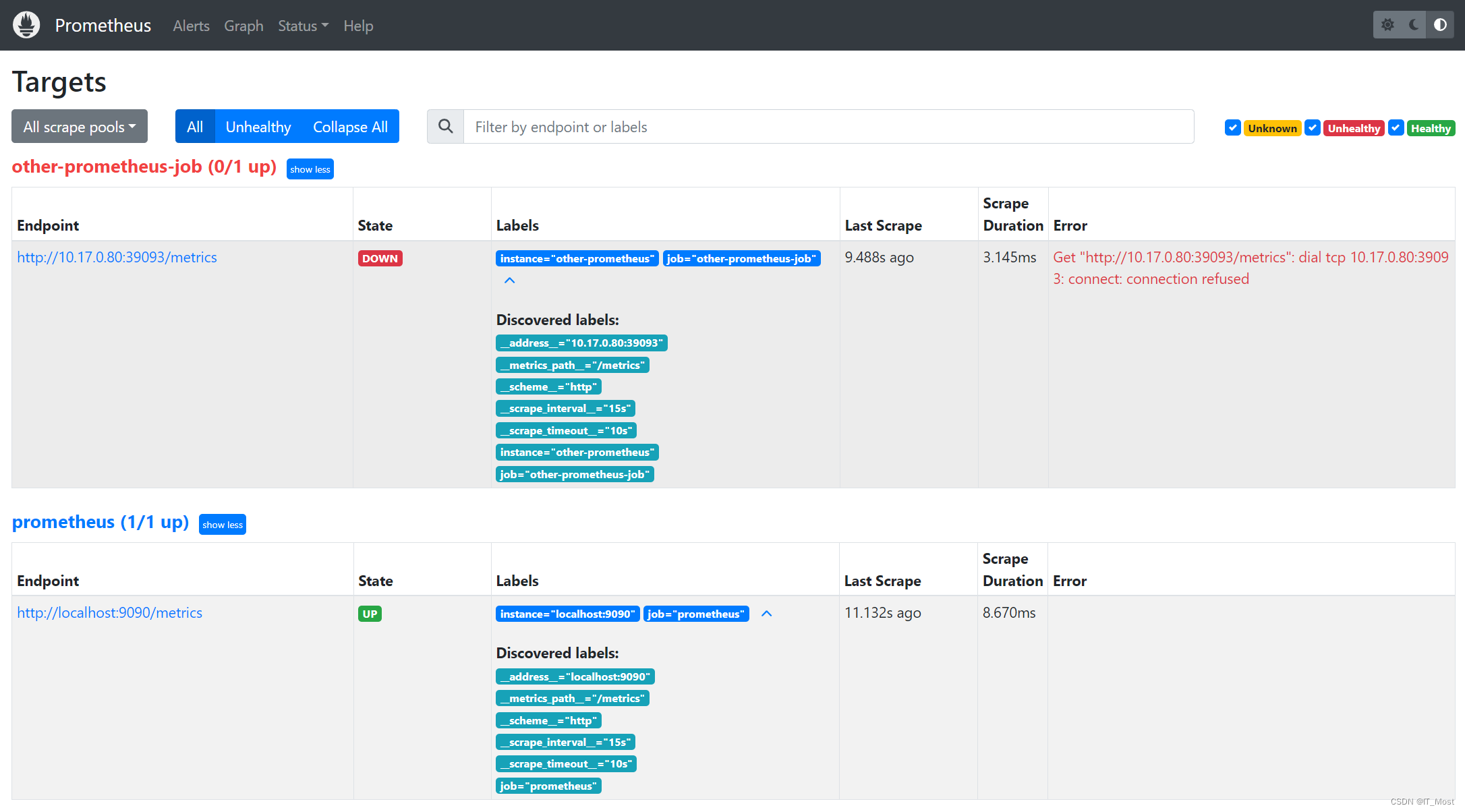
展示的所有Target均来自于prometheus.yml中的“scrape_configs”参数或“file_sd_config”参数配置targets。其中“scrape_configs”参数可配置静态的targets,“file_sd_config”参数可从其它yml或json文件中读取动态配置的targets。
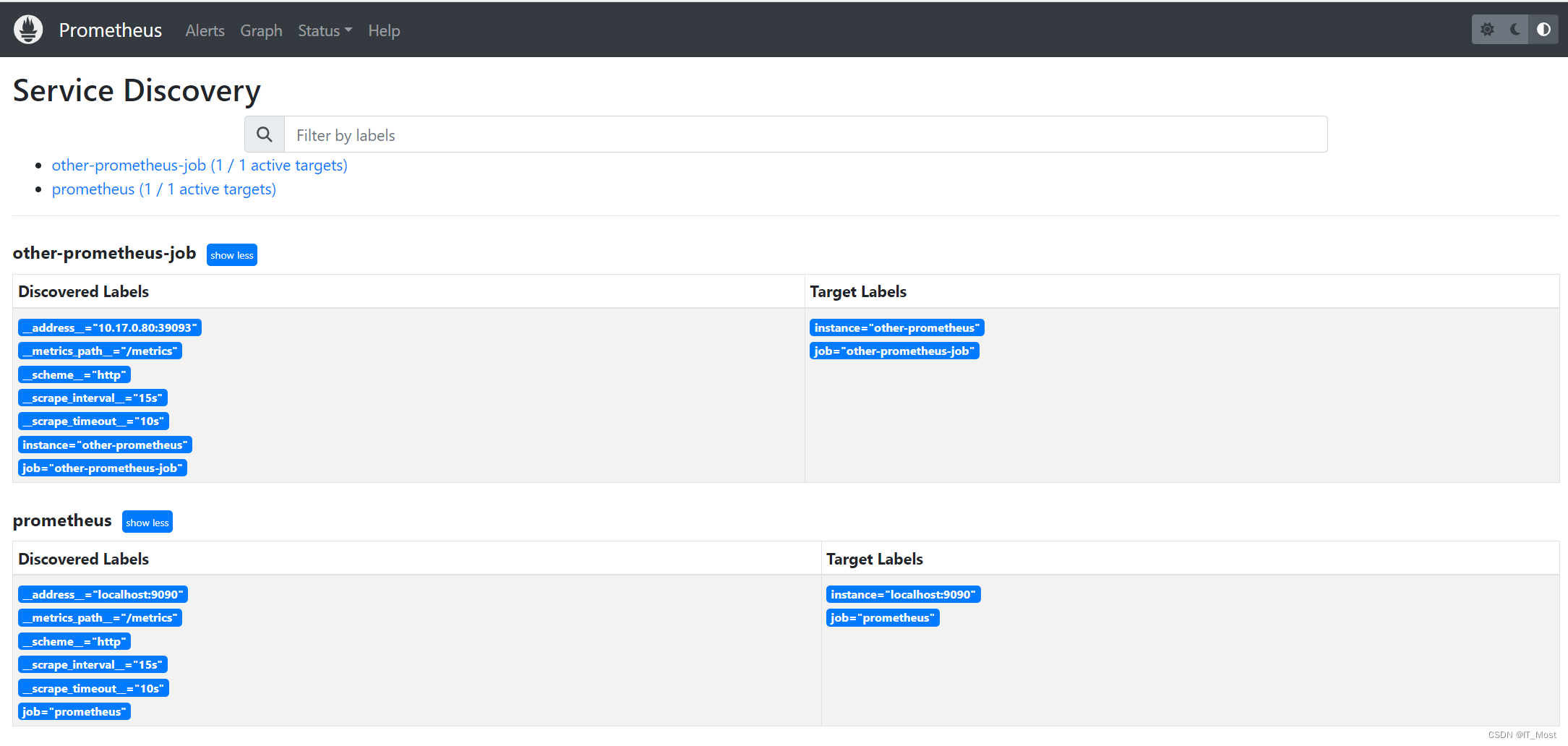
(7)Service Discovery
可查看Prometheus服务发现的所有job,和每隔job下的targets信息。
1.2.4.Help页面
点击“Help”图标,即可跳转至Prometheus官网文档(Prometheus官网文档)。
可在官网文档中找到如何安装Prometheus、如何配置Prometheus、PromQL语法规则和HTTP API信息等。


















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











