



核心问题
多关节物体(如门、抽屉)操作是机器人泛化能力落地的关键瓶颈,其挑战显著区别于刚性物体操作:
动态环境特性:多关节物体自身属于动态系统,其真实关节属性(旋转中心、摩擦力、刚度)需物理接触后才能确定,外观相同的物体可能存在显著物理差异。
仿真到现实(Sim-to-Real)鸿沟:传统方法依赖视觉(RGBD / 点云)作为核心输入,易受仿真与现实视觉差异、操作中部件遮挡影响,导致泛化能力差。
动作柔顺性不足:若机器人动作无法适配物体关节运动,易产生过大力矩,导致设备损坏或任务失败。
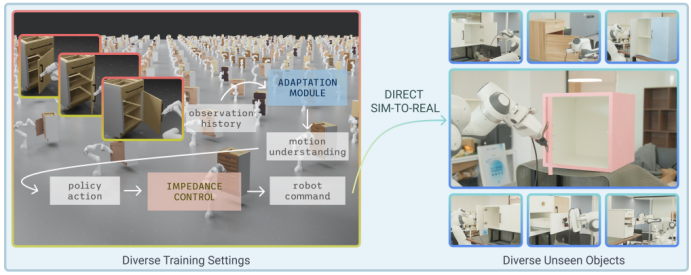
图 1:研究人员训练了一个强化学习策略,用于在模拟环境中打开门和抽屉,该策略会根据通过利用历史观测数据(左图)来处理物体。研究人员直接应用这一策略,在现实世界中达到了80%的关节极限 采用闭环可变阻抗控制,仅使用一帧首帧RGBD图像(右图),成功率达到84%。
针对以上问题,北京大学研究团队以固定基座Franka 机器人为操作载体,提出 “强化学习(RL)+ 运动自适应 + 变阻抗控制” 的一体化方案,核心思路是 “少依赖视觉、多利用历史交互感知”,实现多关节物体的端到端操作
Franka学习新策略
研究中的核心方法
1. 基于观测历史的在线策略蒸馏
设计自适应模块(时序架构),从过去10 组 “观测 - 动作对” 提取物体运动信息;搭配特权观测编码器(浅层 MLP),在仿真中学习物体真实物理属性,通过联合训练减少 Sim-to-Real gap,仅用首帧视觉提取初始抓取姿态,降低视觉依赖。
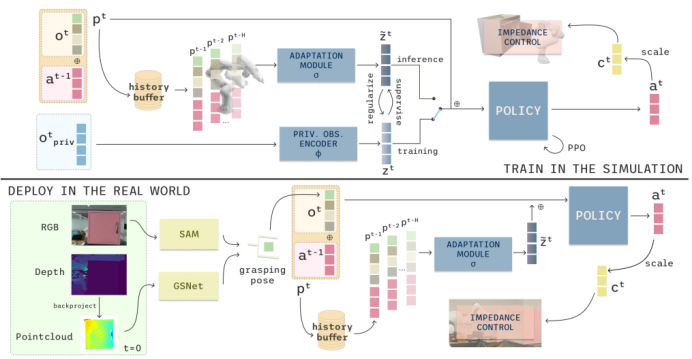
图2:在模拟中,研究人员训练一个特权观测编码器来生成潜在表示z,并同时训练一个自适应模块0,以便从H=10个先前的(o',d'1)对中推断出这个表示z。然后,将潜在表示z与期望的抓取姿态p'机器人本体感受g、机器人-物体距离8'和分类物体参数连接起来,形成策略输入。在现实世界中,研究人员以端到端的方式使用自适应模块o展开训练好的策略,执行到达、抓取和操作。研究人员利用在第一帧捕获的一幅RGBD图像,通过现成的视觉模块提取期望的抓取姿态p。
2. 阶段条件奖励与域随机化
奖励系统含任务感知(强制“先抓取后操作” 逻辑)与运动感知(优化动作柔顺性)两类奖励;
域随机化覆盖物体物理属性(摩擦力、刚度、质量)与姿态(位置、抓取姿态),提升策略鲁棒性。
3. 变阻抗控制
基于“质量 - 弹簧 - 阻尼” 模型,RL 策略学习笛卡尔阻抗控制器刚度参数,通过公式缩放确保稳定性;结合临界阻尼条件推断阻尼矩阵,平衡轨迹跟踪与物体关节运动容忍度,避免过大力矩。
缩放公式
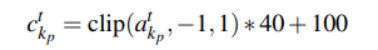
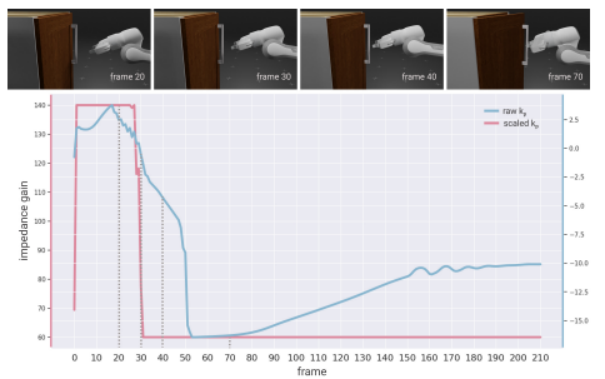
图3.研究人员学习到的控制器增益即使在没有直接增益奖励的情况下也能主动适应操作阶段:在到达时更硬,在打开时更软。
实验配置
1. 核心硬件
-
机械臂:固定基座Franka 机器人(仿真与现实一致,采用真实运动学逆解配置);
-
相机:Franka 搭载 RealSense D415 相机,仅首帧采集 RGBD 图像。
2. 仿真与数据工具
-
模拟器:IsaacGym;
-
数据集:PartNet-Mobility(346 个多关节 3D 模型,含门、抽屉);
-
视觉模块:Segment Anything(SAM)提取可操作部件点云,GSNet 预测抓取姿态。
实验设计与验证
实验设计围绕“泛化能力验证”“模块有效性验证”“Sim-to-Real 迁移验证” 三大目标展开,逻辑分层清晰:
1. 任务设计
聚焦多关节物体核心操作场景,定义两类高难度任务(区分“基础版” 与 “进阶版”,提升现实意义):
-
开门任务(OpenDoor/OpenDoor+):门初始关闭,需打开至最大开合角度的 15%(基础)/80%(进阶),要求夹爪全程抓牢把手,禁止 “侧面开门” 等作弊行为。
-
开抽屉任务(OpenDrawer/OpenDrawer+):抽屉初始关闭,需拉开至最大长度的 20%(基础)/80%(进阶),同样要求全程抓牢把手。

图4:我们在现实世界中对我们的策略进行了广泛评估,使用了各种未见过的物体,这些物体在外观、尺寸上各不相同 铰链方向和铰链刚度。我们在合理的工作空间中展示了我们的性能,物体朝前 或绕z轴稍微倾斜。
2. 基线对比验证
选取5类代表性基线方法,覆盖 “开环 / 闭环”“视觉依赖程度” 等维度,验证所提方案的优越性:
-
闭环方法:PPO(纯RL无优化)、PartManip(视觉驱动RL,点云输入)、RGBManip(单目视觉闭环,多视角感知)。
-
开环方法:Where2Act(视觉可用性预测,开环执行轨迹)、GAPartNet(跨类别视觉分割 + 启发式操作)。

表1:消融研究与现实世界性能
3. 模块有效性验证(消融实验)
通过4 组消融实验,孤立验证核心模块的必要性:
-
无策略蒸馏:移除自适应模块与特权观测编码器,仅用当前时刻观测训练。
-
无变阻抗控制:替换为传统笛卡尔位置控制。
-
无正则化:移除运动感知奖励。
-
无随机化:关闭所有物理与姿态随机化设置。
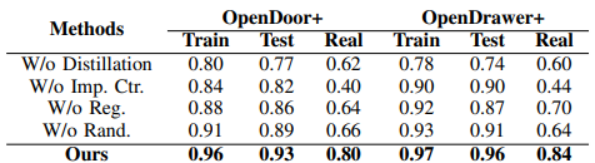
表2:消融研究与现实世界性能
关键成果与突破
1. 突破视觉依赖瓶颈
提出“首帧视觉 + 历史交互感知” 范式,解决传统视觉依赖导致的泛化差、遮挡失效问题,为复杂场景机器人操作提供新路径。
2. 重构柔顺控制体系
首次将变阻抗控制与RL 深度融合,使机器人动作自适应物体物理差异,解决刚性操作易损坏设备痛点,支撑接触密集型任务安全落地。
3. 简化落地流程
通过“域随机化 + 阶段奖励” 实现 “仿真端到端训练→现实直接迁移”,降低 RL 策略在工业机器人的部署门槛,推动通用机器人操作走向实际场景。
4. 拓展RL应用边界
基于观测历史建模动态环境的方法,可迁移至移动机器人交互、柔性物体操作等场景,为RL解决非结构化动态环境问题提供通用思路。
结语
本研究以Franka 机器人为载体,通过 “少看多感” 思路融合 RL、运动自适应与变阻抗控制,解决多关节物体操作的核心痛点,重构机器人操作策略设计逻辑。其技术方案为工业、家用场景通用物体操作提供落地路径,也为后续 RL 结合多模态感知(触觉、力觉)缩小 Sim-to-Real gap 提供启示,助力通用机器人规模化应用。
项目详情:https://watch-less-feel-more.github.io/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









