




研究背景
现有机器人政策学习大多依赖大规模带动作标注的数据,不仅数据获取成本高,还难以跨不同载体(如不同机械臂、甚至人类动作)和环境迁移,在实际场景中泛化能力有限。
而以松灵PiPER机械臂为载体的UniVLA框架,通过 “任务中心潜在动作” 学习方案,打破了这一限制 —— 它无需依赖动作标签,能从机器人演示、人类视频等多源数据中提取通用动作知识,最终在实际部署中实现高效任务执行,解决了传统方法在跨载体、跨环境适配及数据依赖上的核心问题。
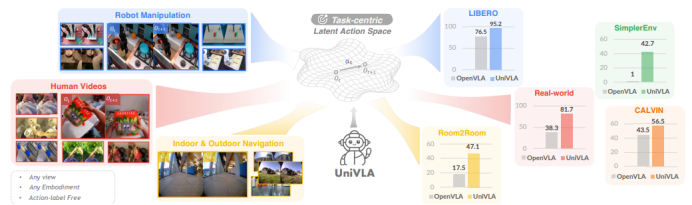
UniVLA,这是一个统一的视觉语言行动(VLA)框架,可实现跨不同领域的策略学习 环境。通过以无监督的方式推导以任务为中心的潜在动作,UniVLA可以利用来自任意 没有动作标签的具身和视角。在从视频进行大规模预训练后,UniVLA通过学习最少的动作解码,开发出一种跨具身的通用策略,该策略可以轻松部署到各种机器人上 成本。与OpenVLA [39]相比,UniVLA在多个操作和导航任务上均有一致的改进。
核心方法
UniVLA 框架通过三步实现高效政策学习,为 PiPER 机械臂的精准操作提供支撑:
任务中心潜在动作学习:从视频中提取与任务相关的动作表示。利用DINOv2 提取图像特征,结合语言指令分离 “任务相关” 和 “任务无关” 动态(如排除相机抖动、无关物体移动等干扰),通过 VQ-VAE 将动作量化为离散 tokens。
下一个潜在动作预测:基于视觉观察和语言指令,训练自回归模型预测潜在动作序列,具备跨载体的规划能力。
潜在动作解码:将潜在动作转化为机械臂可执行的控制信号,通过轻量级解码器和LoRA 参数高效微调,快速适配 PiPER 机械臂的控制需求。
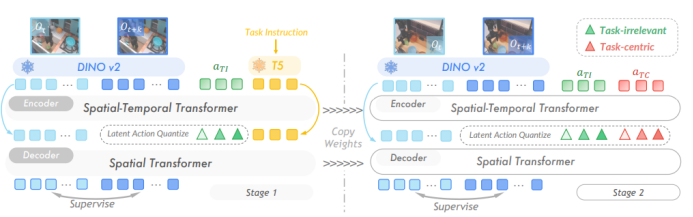
图2:以任务为中心的潜在动作学习。提出了一个两阶段训练框架,旨在将以任务为中心的视觉动态和变化与无关因素分离开来。在第一阶段,从预训练的T5文本编码器,导出的任务指令嵌入被用作编码器和解码器的输入。这些嵌入提供与任务相关的语义信息,以提高预测准确性。在第二阶段,引入了一组新的潜在动作,专门设计用于取代语言的作用,并从视频帧的DINOv2编码特征中捕捉以任务为中心的动态。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









