




1 深度学习基础
1.1 深度学习模型训练流程

1.2 深度学习模型基础知识
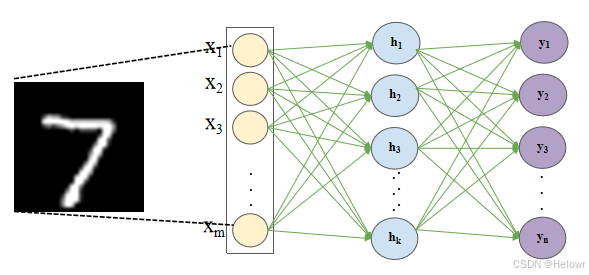
1 全连接
2 卷积
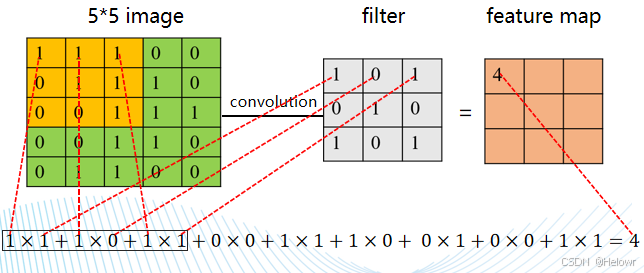
1.图像卷积计算
卷积核中的各参数与图像矩阵相应位置的数值相乘后再求和
它从图像的左上角开始,每次从左到右移动一个像素列,直到滤镜的边缘到达图像的边缘。
卷积会产生边界效应。特征图输入尺寸的减小称为边界效应
填充:在图像边缘添加像素。
通过在图像框架之外启动过滤器,它为图像边界上的像素提供了更多与过滤器交互的机会,为过滤器检测到特征提供了更多机会,进而提供了输出与输入图像具有相同形状的特征图。
步幅:对输入图像应用滤波器之间的移动量。二维的默认步幅或步幅为 (1,1)
步幅可以更改,这会影响滤波器如何应用于图像,进而影响生成的特征图的大小。
例如,步幅可以更改为(2,2)。这具有以下效果:在创建特征图时,过滤器的每次水平移动将过滤器向右移动两个像素,过滤器的每次垂直移动将过滤器向下移动两个像素。
输入信号的通道数 in_channels
如果是彩色的,即RGB类型,这时候通道数固定为3,如果是灰色的,通道数为1。
卷积产生的通道数 out_channels
取决于过滤器的数量
对于第二层或者更多层的卷积,此时的 in_channels 就是上一层的out_channels
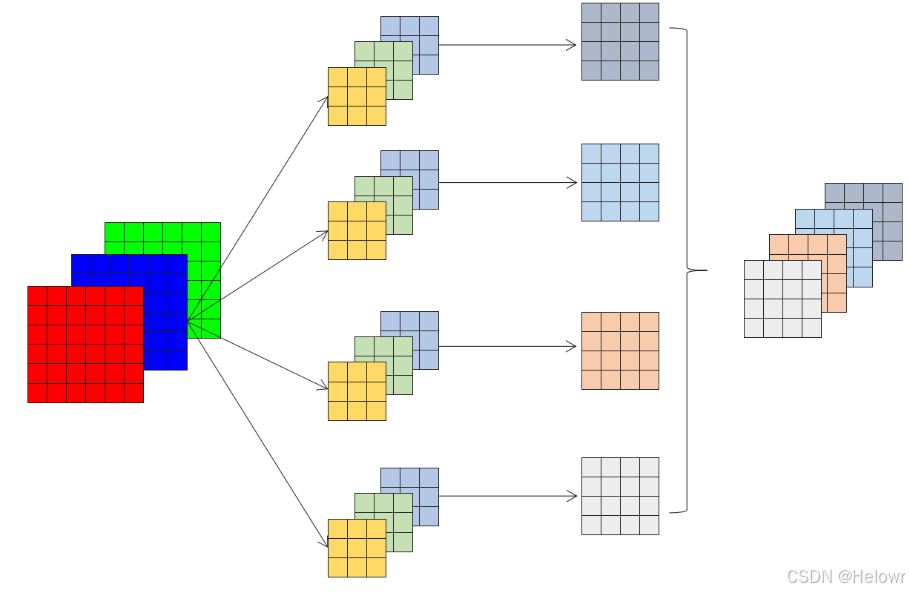
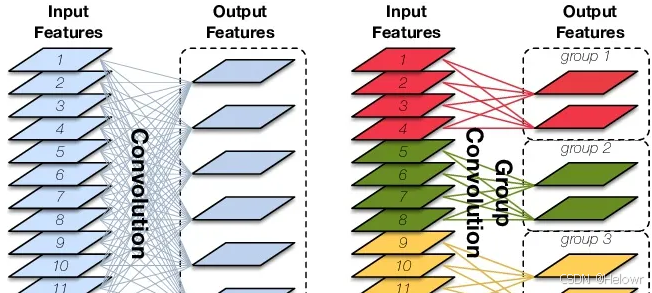
2.分组卷积
groups (int, 可选): 作用是将输入的通道与输出的通道进行分组。默认情况下,值为1,这意味着所有的输入通道和输出通道都是全连接的。如果将值设置为大于1,那么输入的通道将被分成相应的组数,每组有相同数量的通道。同样,输出的通道也将被分成相应的组数,每组有相同数量的通道。在这种情况下,每个组的通道之间是全连接的,但不同组之间的通道是不连接的。
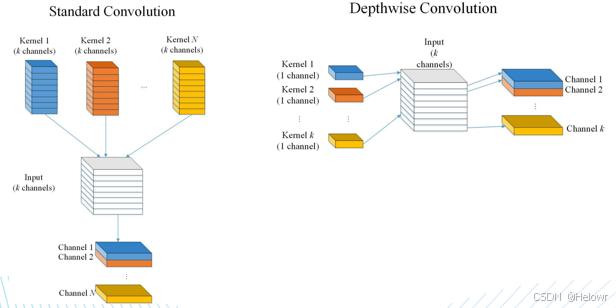
3.深度可分离卷积
(1) Depthwise Convolution
Depthwise Convolution中对每个通道只使用一个卷积核,所以单个通道在卷积操作之后的输出通道数也为1。那么如果输入feature map的通道数为K时(如图所示),对K个通道分别单独使用一个卷积核之后便得到K个通道为1的feature map。再将这K个feature map按顺序拼接便得到一个通道为K的输出feature map。
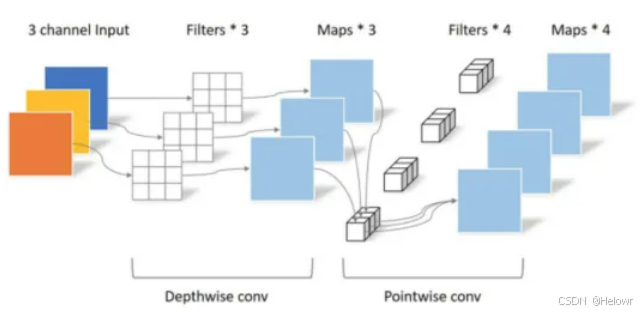
(2) Pointwise Convolution
实际为1×1卷积。
在DSC中它起两方面的作用:
第一个作用是让DSC能够自由改变输出通道的数量;
第二个作用是对Depthwise Convolution输出的feature map进行通道融合。
4.转置卷积与反卷积
将一些低分辨率的图片转换为高分辨率的图片,对于这种上采样(up-sampling)操作,目前有着一些插值方法进行处理。比如最近邻插值,双线性插值,双立方插值。但是如果我们想要我们的网络可以学习到最好的上采样的方法,我们这个时候就可以采用转置卷积。这个方法不会使用预先定义的插值方法,它具有可以学习的参数。

5.3D卷积
Conv2d的输入tensor维度(N,C,H,W),其中N为baitch_size, C为通道数,H为特征图高度,W为特征图宽度
3D卷积加入了一个深度(时间)维度,Conv3d 输入的 tensor 维度应该是 [N, C ,D, H, W],其中D为视频帧数。
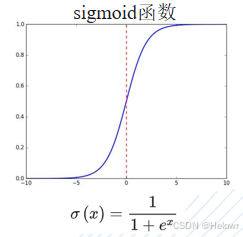
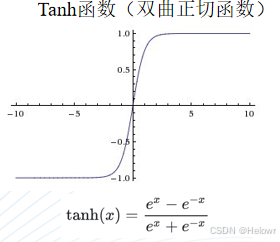
3 激活函数

4 池化
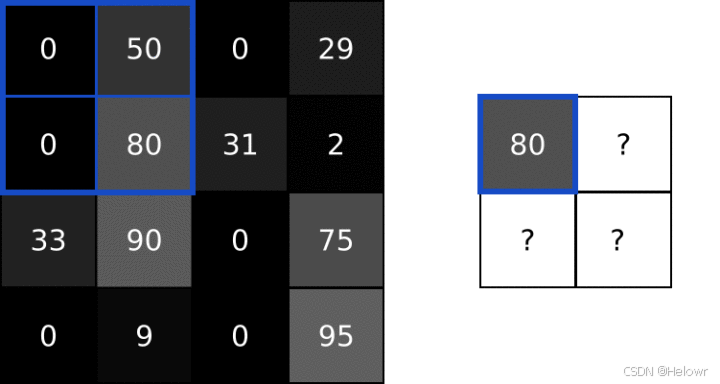
池化是卷积神经网络中的一种下采样操作。它通过定义一个空间邻域(通常为矩形区域),并对该邻域内的特征进行统计处理(如取最大值、平均值等),从而生成新的特征图。
特征降维,特征提取,防止过拟合。
池化操作通常紧随卷积层之后。池化操作在降低特征图空间大小的同时,保持了特征的空间层次结构,有助于减少计算量并提高模型的泛化能力。
2 TensorBoard可视化
2.1 TensorBoard介绍
终端启动命令tensorboard --logdir=./log
TensorBoard: 是TensorFlow中强大的可视化工具,支持显示标量、图像、文本、音频、视频和Embedding等多种数据可视化。可以帮助开发者方便的理解、调试、优化TensorFlow 程序。其在PyTorch中也能使用。

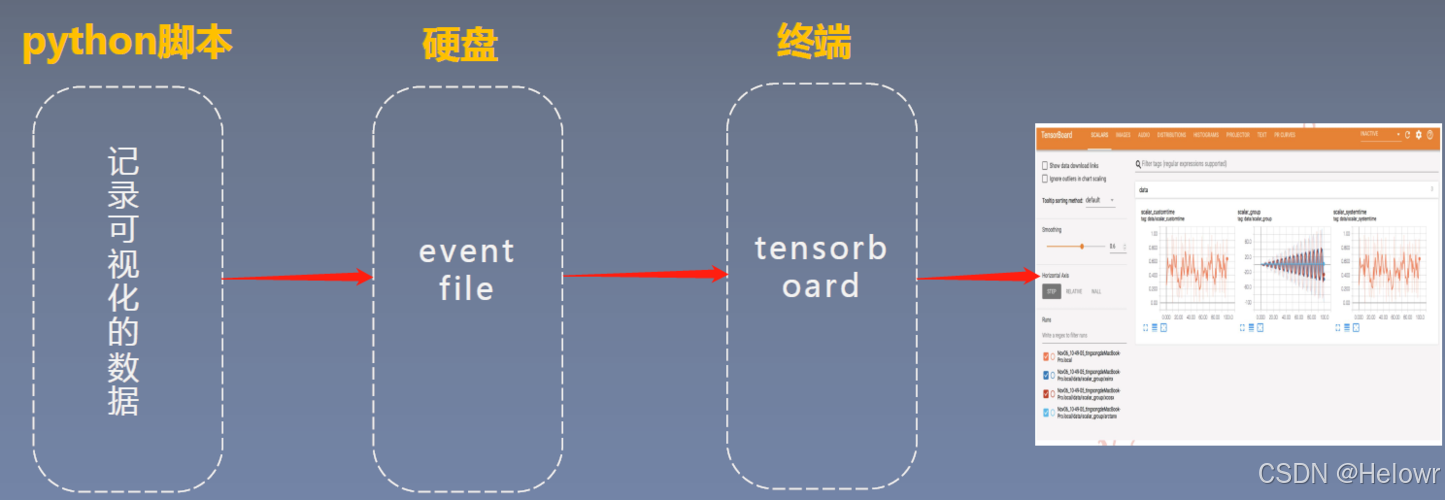
(1)TensorBoard原理-Python脚本
1.导入tensorboard并创建SummaryWriter实例
from torch.utils.tensorboard import SummaryWriter
if __name __=="__main__":
writer = SummaryWriter(log_dir='./log’)
2.调用Python API记录要可视化的数据
(2) TensorBoard原理-写入event文件

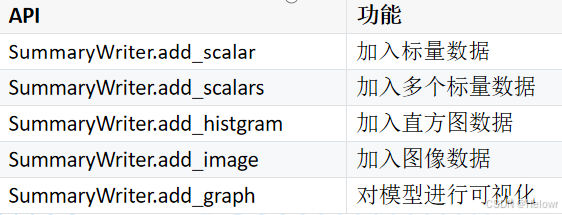
2.2 TensorBoard--标量数据可视化(损失函数值,评估指标)
损失函数值、准确度、精确度、召回率、F1Score、mAP
加入标量数据:add_scalar(tag, scalar_value, global_step=None, walltime=None)

加入多个标量数据:add_scalars (tag, dict, global_step=None, walltime=None)

2.3 TensorBoard—数据分布可视化
权重、激活值
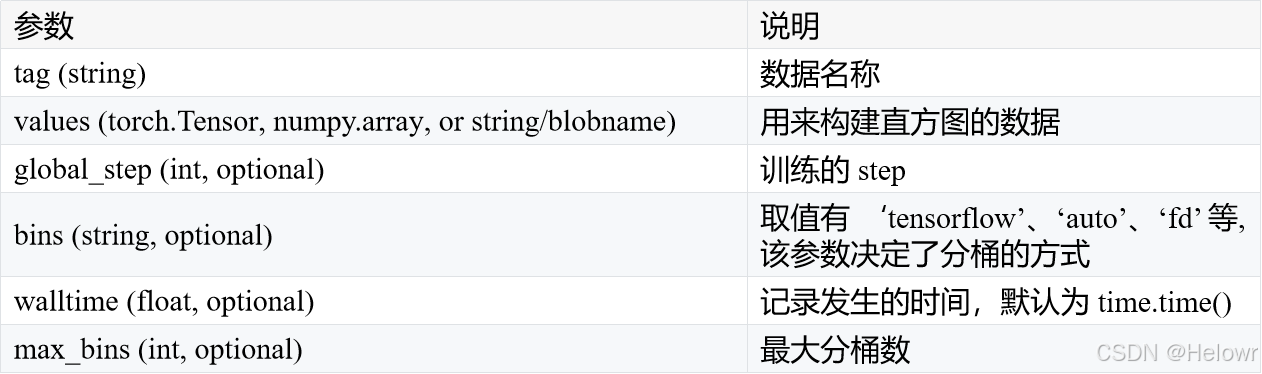
add_histogram (tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
2.4 TensorBoard—特征图的可视化
add_image(tag, img_tensor, global_step, dataformat)

2.5 TensorBoard—模型可视化
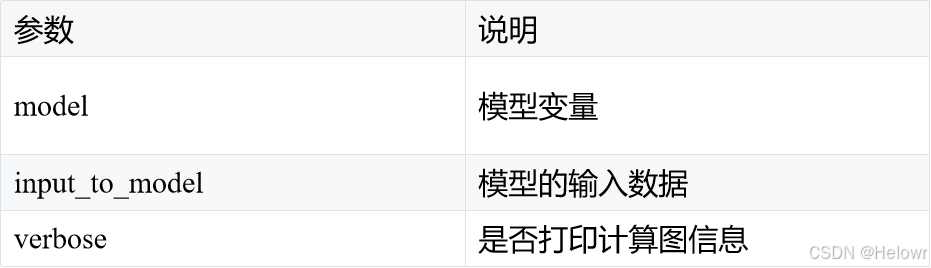
add_graph(model, input_to_model, verbose)
3 模型优化
3.1 数据增强
torchvision.transforms: 是一个包含丰富的数据变换类,有很大一部分可以用于实现数据预处理(Data Preprocessing)和数据增强(Data Argumentation)
输入
PIL Image: transforms.Resize Pytoch
Tensor: transforms.Normalize
因此,在使用transforms之前我们在使用之前最好是先使用transforms.ToTensor()将输入的数据先转换成Tensor对象
(1)基础图像增强
1.几何操作:改变像素的位置(旋转,平移,错切)
transforms.RandomAffine(degrees=0,
translate=(0.1, 0.2) ,
shear=30)

2.非几何操作:改变图像的视觉特性
翻转(水平,垂直),裁剪,噪声注入,颜色空间,改变图像的亮度 对比度和色调,图像锐化和模糊
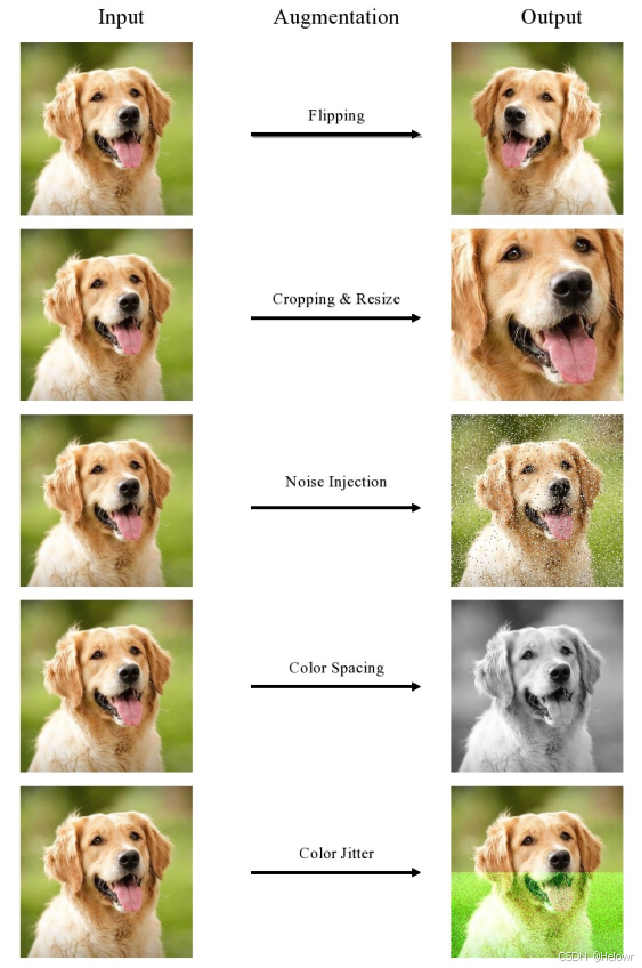
3.图像擦除
1:Cutout(p=1, scale=(0.02, 0.4), ratio=(0.4, 1)),# 该操作前不要transforms.ToTensor()
transforms.ToTensor(),
2:transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3)) # 这个一定要注意使用该操作之前一定要加transforms.ToTensor(),

3:Hide-and-Seek
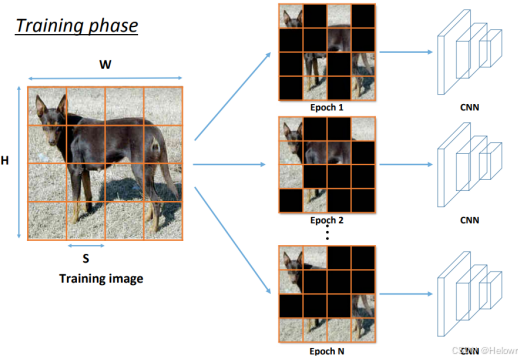
4:GridMask

(2)高阶图像增强
1.单张图像
1.局部增强(local Augment)
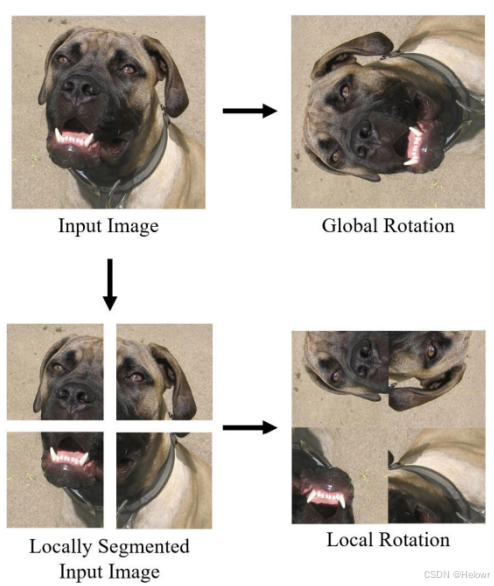
2.自增强(Self Augmentation)
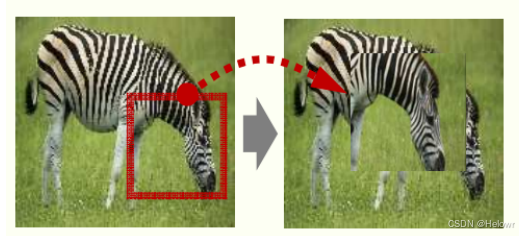
3.SalfMix
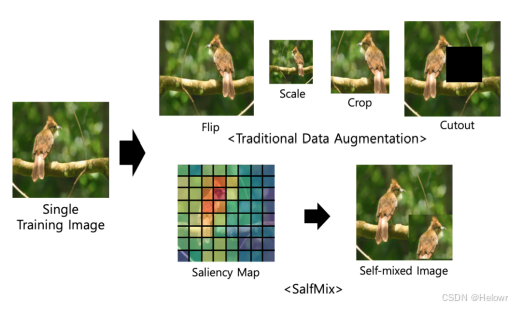
2.多张图像
1.Mixup
2.CutMix

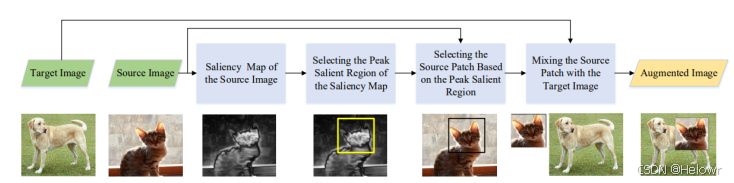
3.SailiencyMix
3.2 标准化 (Batch Normalization, BN)
1 批标准化

2 层标准化
LN是在每个样本上对每个特征进行标准化。它计算每个特征在样本上的均值和方差,并将数据进行标准化。与BN不同,LN不依赖于批次的大小,适用于各种场景。

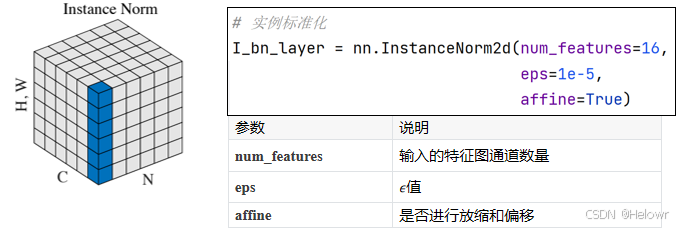
3 实例标准化
实例标准化(Instance Normalization,IN):IN是在每个样本上对每个通道进行标准化。它计算每个通道在样本上的均值和方差,并将数据进行标准化。IN常用于图像生成任务,如图像风格转换和图像生成模型。
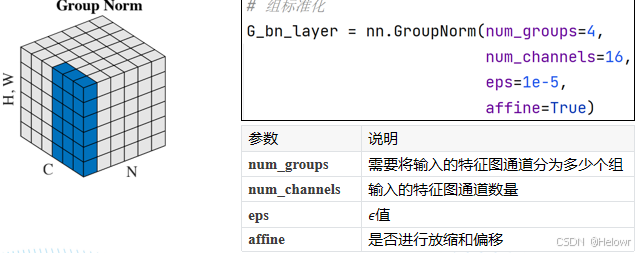
4 分组标准化
组标准化(Group Normalization,GN):GN是在每个样本上对每个通道组进行标准化。通道组是将通道分成多个组,每个组包含一部分通道。GN计算每个通道组在样本上的均值和方差,并将数据进行标准化。
3.3 正则化
偏差(Bias):预测值和真实值之间的误差
方差(Variance):预测值之间的离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。
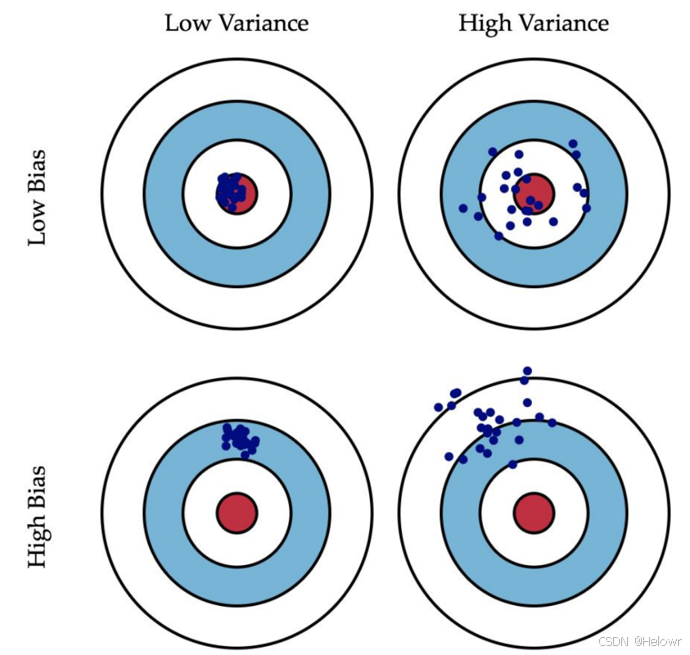
训练集的错误率较小,而验证集/测试集的错误率较大,说明模型存在较大方差,可能出现了过拟合
训练集和测试集的错误率都较大,且两者相近,说明模型存在较大偏差,可能出现了欠拟合 训练集和测试集的错误率都较小,且两者相近,说明方差和偏差都较小,这个模型效果比较好。
高方差,有以下几种方式:
获取更多的数据,使得训练能够包含所有可能出现的情况
正则化(Regularization)L1与L2正则化
寻找更合适的网络结构
3.4 Dropout
Dropout方法是Hinton等人在2012年推出的,为了防止训练阶段的过拟合,随机去掉神经元。在一个密集的(或全连接的)网络中,对于每一层,我们给出了一个dropout的概率p。在每次迭代中,每个神经元被去掉的概率为p。
一般是在最后的全连接层出现
3.5 优化函数
待优化参数记为w,损失函数loss,学习率lr,每次迭代一个batch, t表示当前batch迭代的总次数。
过程:

1.优化函数-SGD(Stochastic Gradient Descent)
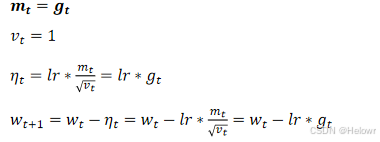
2.优化函数-SGDM(Stochastic Gradient Descent with Momentum)在SGD的基础之上一阶动量考虑了第t-1次迭代的结果mt=gt
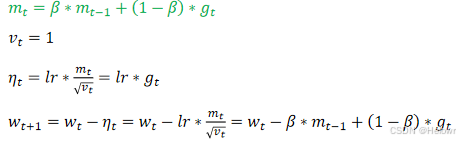
3.优化函数- Adagrad(在SGD的基础上增加二阶动量)
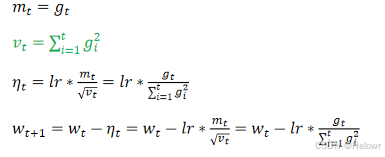
4.优化函数- RMSProp,在SGD的基础上增加了二阶动量,且二阶动量考虑了第t次和第t-1次的结果mt=gt
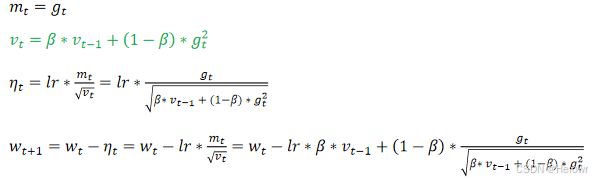
5.优化函数- - Adam(同时结合SGDM一阶动量和RMSProp二阶动量)



















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









