




一、环境信息
1、参看如下:
二、测试使用
1、引入依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>2、创建PgVectorStore
@Bean("pgVectorStore")
public PgVectorStore pgVectorStore(JdbcTemplate jdbcTemplate) {
DashScopeEmbeddingModel model = new DashScopeEmbeddingModel(new DashScopeApi(apiKey));
return PgVectorStore.builder(jdbcTemplate, model)
.dimensions(dimensions) // Optional: defaults to model dimensions or 1536
.distanceType(distanceType) // Optional: defaults to COSINEDISTANCE
.indexType(indexType) // Optional: defaults to HNSW
.initializeSchema(false) // Optional: defaults to false
.schemaName("public") // Optional: defaults to "public"
.vectorTableName("vector_store") // Optional: defaults to "vectorstore"
.maxDocumentBatchSize(maxDocumentBatchSize) // Optional: defaults to 10000
.build();
}spring:
application:
name: SpringAIProjet
ai:
dashscope:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: XXX
chat:
options:
model: qwen-plus
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 1536
max-document-batch-size: 10000
datasource:
url: jdbc:postgresql://pgm-2zeb9148645sl4.pg.rds.aliyuncs.com:5432/spring_ai
username: XXX
password: XXX3、建表语句如下
create database spring_ai;
/**
vector:向量数据库扩展,提供向量数据类型及相似度计算函数(如vector_cosine_ops)。
hstore:键值对存储扩展,用于灵活存储元数据(如metadata字段)。
uuid-ossp:UUID生成扩展,提供uuid_generate_v4()函数,用于生成全局唯一ID(id字段默认值)。
*/
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE IF NOT EXISTS vector_store (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
content text,
metadata json,
embedding vector(384)
);
ALTER TABLE vector_store
ALTER COLUMN embedding TYPE vector(1536);
CREATE INDEX ON vector_store USING HNSW (embedding vector_cosine_ops);
4、测试文件:springai.txt
SpringAI 是 Spring 官方推出的 AI 应用开发框架,通过提供统一的 API 抽象简化 AI 模型(如大语言模型、嵌入模型)与 Spring 生态的集成,支持多类 AI 服务(OpenAI、Azure OpenAI、Hugging Face 等)和向量存储(Redis、Milvus 等),让开发者聚焦业务逻辑。其核心组件按功能可分为数据处理、模型交互、向量存储、工具集成等维度,各组件分工明确以支撑 AI 应用开发全流程:
一、数据处理组件
数据是 AI 应用的基石,SpringAI 提供工具帮助开发者处理和准备数据,核心逻辑包括:
数据预处理:对原始数据进行清洗、格式转换、特征提取等操作,为后续 AI 模型训练或推理提供合规输入。
数据存储与管理:整合向量存储(如 Redis、Milvus)等技术,实现嵌入向量的存储与相似性检索(核心用于 RAG 场景),确保数据高效存取与检索。
二、模型交互组件
模型交互是 AI 应用的核心环节,SpringAI 通过统一接口屏蔽不同厂商(OpenAI、Anthropic 等)的差异,核心功能包括:
模型抽象:将大语言模型、嵌入模型等抽象为统一接口,开发者无需关注底层实现细节,直接调用接口即可完成模型调用。
提示与响应管理:支持提示文本(Prompt Text)和系统消息(System Message)的动态生成与管理,同时处理模型返回的响应(包含生成文本、元数据等),确保交互流程标准化。
三、向量存储组件
向量存储是 RAG(Retrieval Augmented Generation)场景的核心,SpringAI 提供工具支持向量存储的存储、检索、管理全流程:
存储:将文本的嵌入向量存储到 Redis、Milvus 等存储系统,为后续检索提供数据基础。
检索:基于向量相似性算法(如余弦相似度)快速定位与输入文本最相关的向量,支撑 RAG 场景下的知识检索。
管理:提供向量存储的生命周期管理(如创建、更新、删除),确保存储系统的高效与稳定。
四、工具集成组件
工具集成是 AI 应用扩展能力的关键,SpringAI 支持函数调用(Function Calling)等机制,核心逻辑包括:
工具注册:开发者可注册外部工具(如数据库查询、API 调用),让模型根据问题自动调用工具获取信息。
调用机制:通过统一接口调用注册工具,模型可基于问题自动触发工具执行,实现“AI + 工具”的协同工作流。
五、环境与生态组件
SpringAI 基于 Spring Boot 构建,通过Starters 引入依赖简化环境搭建,核心优势包括:
依赖管理:通过 Maven/Gradle 的 Starters 依赖,快速引入 SpringAI 及其生态组件,避免版本兼容性问题。
生态整合:无缝集成 Spring Boot、Spring Web、Spring Data 等现有 Spring 组件,开发者可复用 Spring 生态的开发经验,快速构建 AI 驱动的应用。
六、其他组件(如评估器 - 优化器)
部分组件(如评估器 - 优化器)聚焦模型评估与优化,核心逻辑包括:
评估:对模型生成内容的准确性和相关性进行评估,为优化提供数据依据。
优化:基于评估结果调整模型参数或流程,持续提升 AI 应用的性能与效果。
SpringAI 的组件设计遵循“简化开发、聚焦业务”的理念,通过各组件的分工协作,帮助开发者高效构建 AI 驱动的应用,同时保障技术栈的稳定性与可扩展性。5、读取文件测试
package org.spring.springaiprojet.controller;
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingModel;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.core.io.ClassPathResource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.List;
@RestController
@RequestMapping("/ai/")
public class AiVectorController {
@Autowired
private VectorStore vectorStore;
@Qualifier("pgVectorStore")
@Autowired
private VectorStore pgVectorStore;
@RequestMapping("/qwen/vector/api")
public String vector(String message) throws IOException {
StringBuilder text = new StringBuilder();
ClassLoader classLoader = getClass().getClassLoader();
InputStream inputStream = classLoader.getResourceAsStream("springai.txt");
try (BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream))){
String line;
while ((line = reader.readLine()) != null){
text.append(line);
}
}
List<Document> list = Arrays.stream(text.toString().split("。")).map(Document::new).toList();
// 存储向量,内部会自动向量化
// pgVectorStore.add(list);
// 相似性检索,基于similaritySearch实现
// List<Document> documentList = .similaritySearch("文本");
// SearchRequest request= SearchRequest.builder().query("文本")
// .topK(10)
// .similarityThreshold(0.5).build();
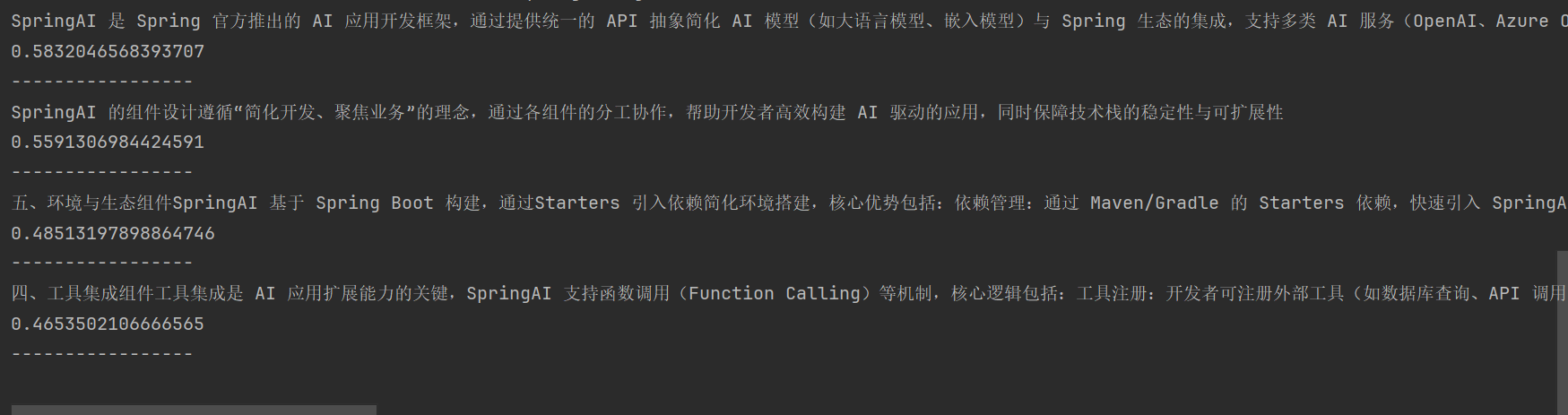
List<Document> documentList = pgVectorStore.similaritySearch(message);
for(Document document : documentList){
System.out.println(document.getText());
System.out.println(document.getScore());
System.out.println("-----------------");
}
return "success";
}6、测试写入向量
GET http://localhost:8088/boot/ai/qwen/vector/api?message=SpringAI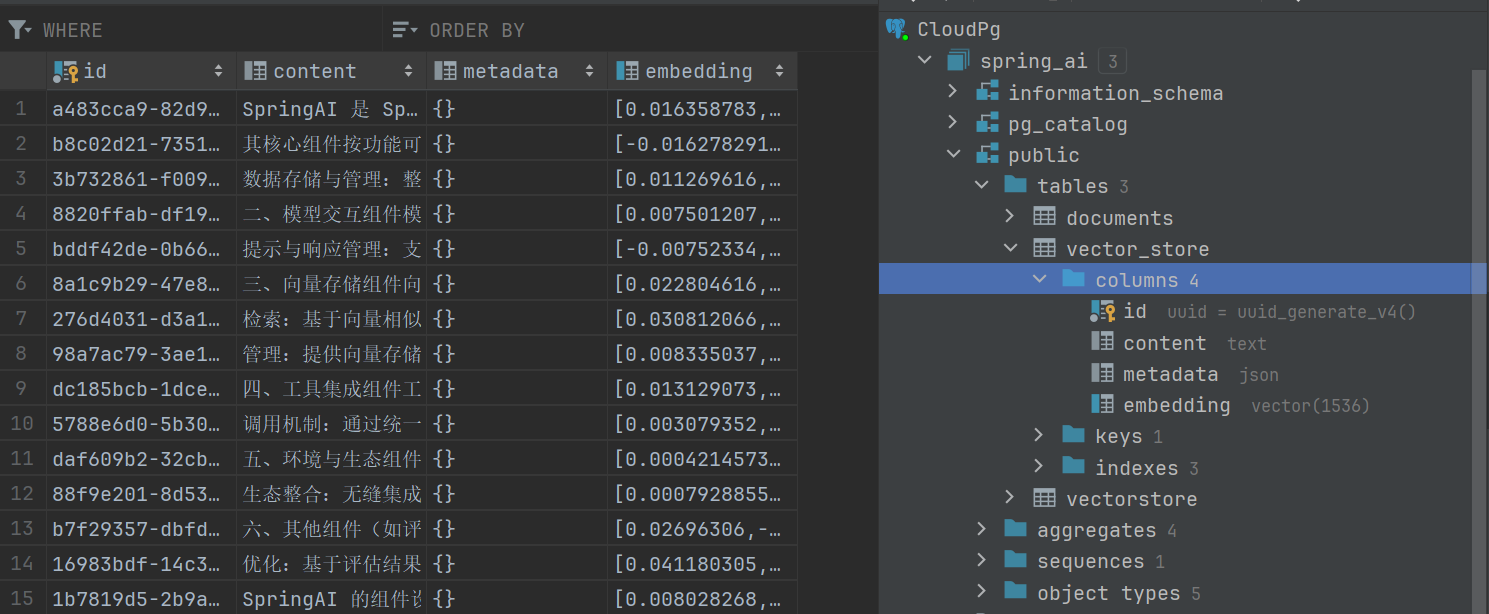


















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











