




[!TIP]
PGvector 是 PostgreSQL 的开源扩展,支持存储和搜索机器学习生成的扩展
实战代码可见:https://github.com/GTyingzi/spring-ai-tutorial 下的 vector/vector-pgvector 模块
Docker 启动 pgvector
推荐使用 ankane/pgvector 提供的官方支持镜像,它已经内置了 pgvector 扩展
docker pull ankane/pgvector:latest
启动容器
docker run -d \
--name pgvector-db \
-e POSTGRESPASSWORD=yingzipassword \
-e POSTGRESUSER=yingziuser \
-e POSTGRESDB=yingzidb \
-p 5432:5432 \
ankane/pgvector:latest
- name:容器名称
- POSTGRESPASSWORD:数据库密码
- POSTGRESUSER:数据库用户
- POSTGRESDB:初始化数据库名
- p:映射主机端口到容器 PostgreSQL 端口
虽然镜像已包含 pgvector,但仍需在目标数据库中创建 pgvector 扩展:
docker exec -it pgvector-db psql -U yingziuser -d yingzidb
在 PostgreSQL 命令行中执行
CREATE EXTENSION IF NOT EXISTS vector;
校验示例
CREATE TABLE items (
id bigserial PRIMARY KEY,
embedding vector(3) -- 3维向量,可根据需要调整维度
);
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
-- 查询最相似的向量
SELECT * FROM items ORDER BY embedding <-> '[1,2,3]' LIMIT 5;
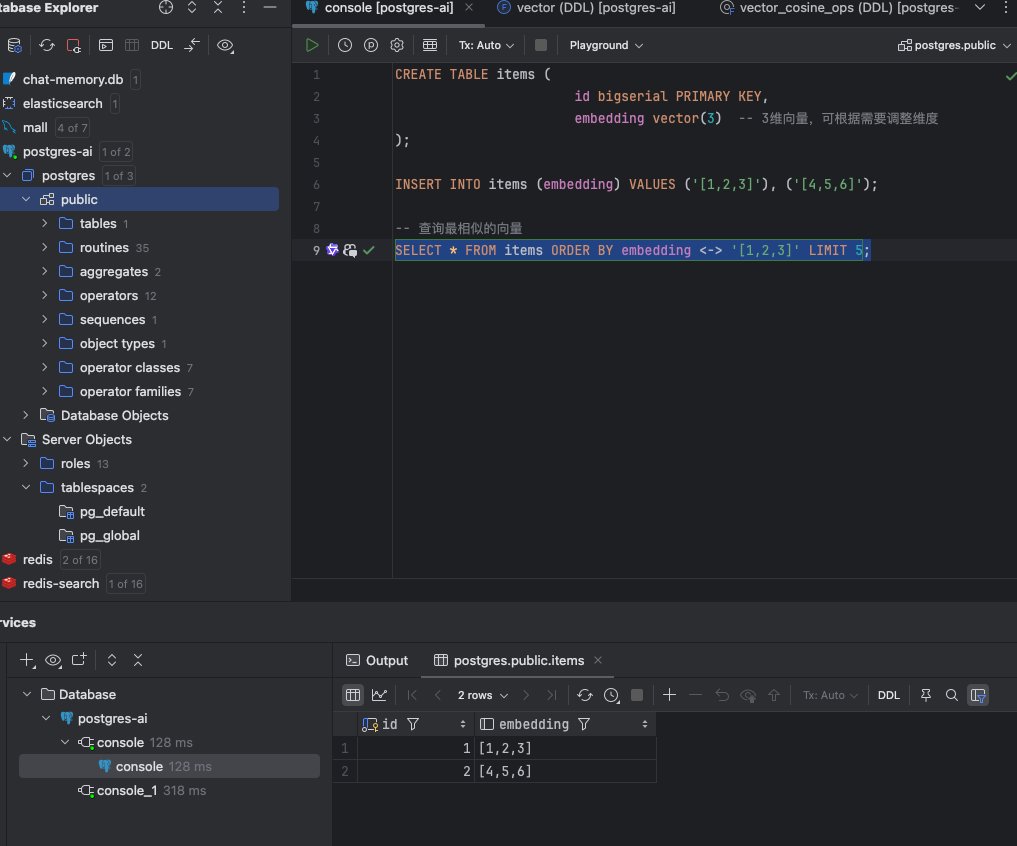
Spring AI 连接 PGvector
pom 依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
</dependencies>
application.yml
server:
port: 8080
spring:
application:
name: vector-pgvector
ai:
openai:
api-key: ${DASHSCOPEAPIKEY}
base-url: https://dashscope.aliyuncs.com/compatible-mode
embedding:
options:
model: text-embedding-v1
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINEDISTANCE
dimensions: 1536
max-document-batch-size: 10000 # Optional: Maximum number of documents per batch
---
spring:
datasource:
url: jdbc:postgresql://localhost:5432/yingzidb
username: yingziuser
password: yingzipassword
PgvectorConfig
package com.spring.ai.tutorial.vector.config;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
/**
* @author yingzi
* @since 2025/9/3
*/
@Configuration
public class PgvectorConfig {
@Value("${spring.ai.vectorstore.pgvector.index-type}")
private PgVectorStore.PgIndexType indexType;
@Value("${spring.ai.vectorstore.pgvector.distance-type}")
private PgVectorStore.PgDistanceType distanceType;
@Value("${spring.ai.vectorstore.pgvector.dimensions}")
private int dimensions;
@Value("${spring.ai.vectorstore.pgvector.max-document-batch-size}")
private int maxDocumentBatchSize;
@Bean("pgVectorStore")
public PgVectorStore vectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel embeddingModel) {
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.dimensions(dimensions) // Optional: defaults to model dimensions or 1536
.distanceType(distanceType) // Optional: defaults to COSINEDISTANCE
.indexType(indexType) // Optional: defaults to HNSW
.initializeSchema(true) // Optional: defaults to false
.schemaName("public") // Optional: defaults to "public"
.vectorTableName("vectorstore") // Optional: defaults to "vectorstore"
.maxDocumentBatchSize(maxDocumentBatchSize) // Optional: defaults to 10000
.build();
}
}
PgvectorController
package com.spring.ai.tutorial.vector.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author yingzi
* @since 2025/9/3
*/
@RestController
@RequestMapping("/vector/pgvector")
public class PgvectorController {
private static final Logger logger = LoggerFactory.getLogger(PgvectorController.class);
private final PgVectorStore pgVectorStore;
@Autowired
public PgvectorController(@Qualifier("pgVectorStore") PgVectorStore vectorStore) {
this.pgVectorStore = vectorStore;
}
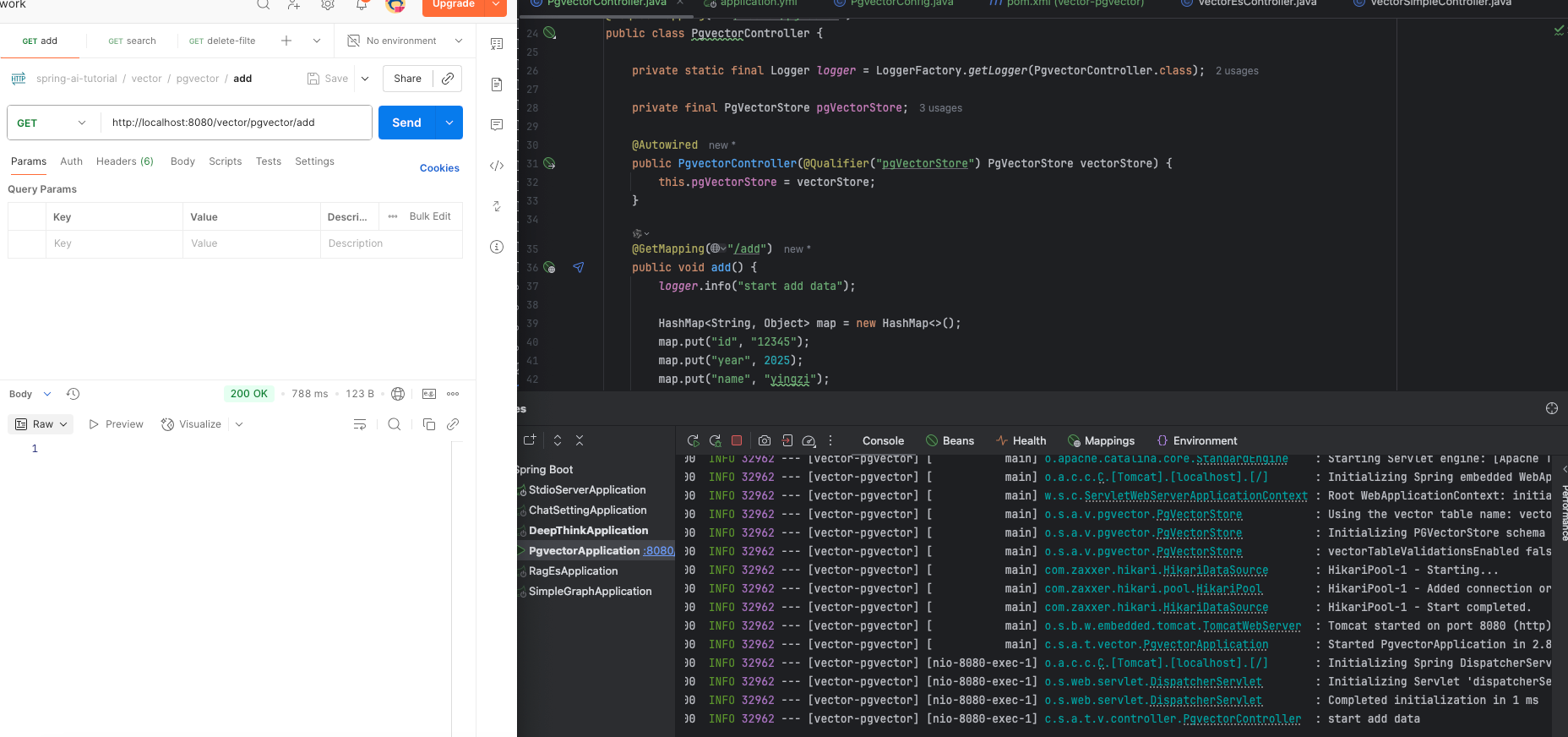
@GetMapping("/add")
public void add() {
logger.info("start add data");
HashMap<String, Object> map = new HashMap<>();
map.put("id", "12345");
map.put("year", 2025);
map.put("name", "yingzi");
List<Document> documents = List.of(
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("year", 2024)),
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", map));
pgVectorStore.add(documents);
}
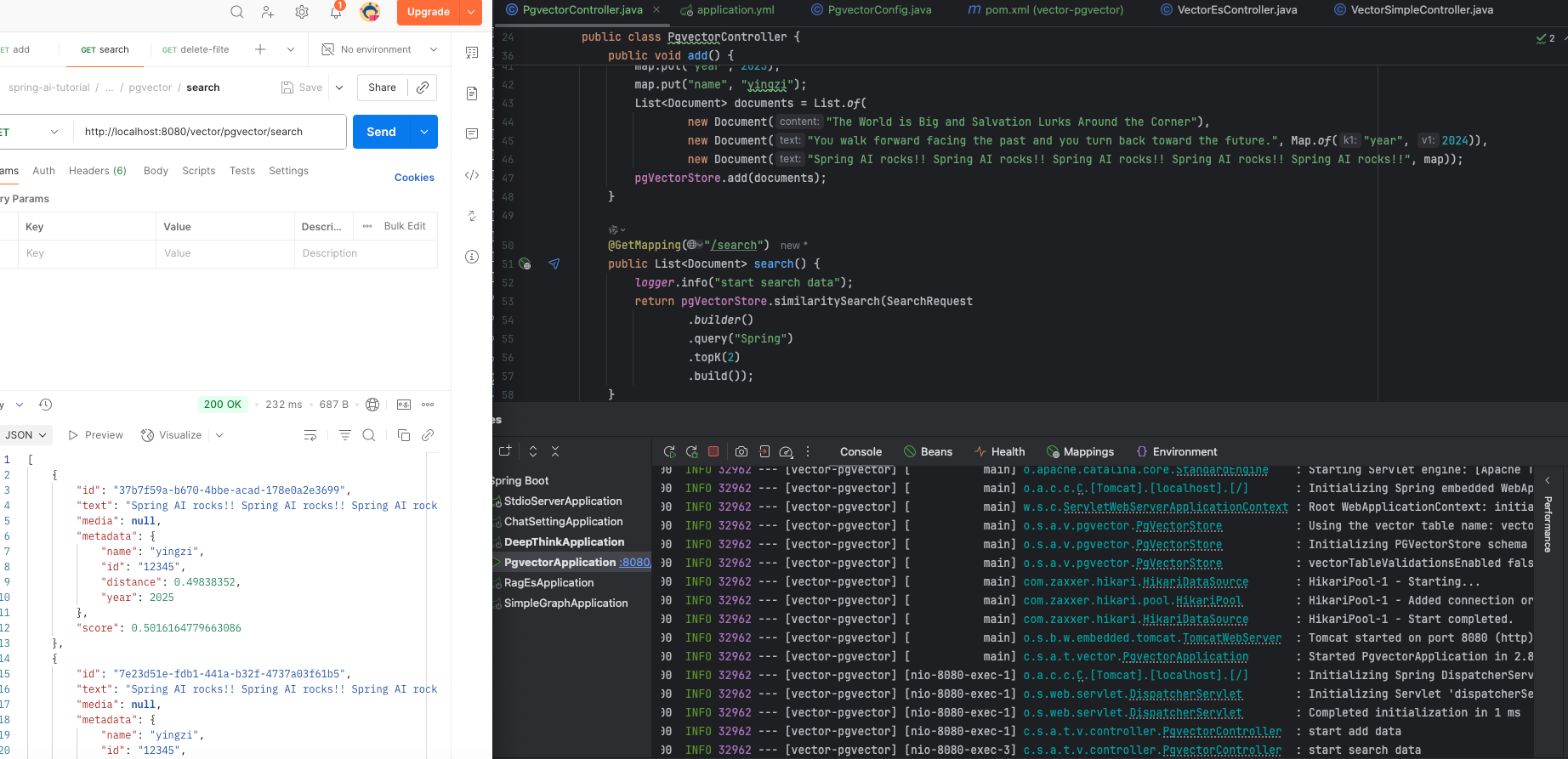
@GetMapping("/search")
public List<Document> search() {
logger.info("start search data");
return pgVectorStore.similaritySearch(SearchRequest
.builder()
.query("Spring")
.topK(2)
.build());
}
}
效果如下
导入数据
查询数据
往期资料

Spring AI + Spring Ai Aliabba系统化学习资料
本教程将采用2025年5月20日正式的GA版,给出如下内容
- 核心功能模块的快速上手教程
- 核心功能模块的源码级解读
- Spring ai alibaba增强的快速上手教程 + 源码级解读
版本:
- JDK21
- SpringBoot3.4.5
- SpringAI 1.0.1
- SpringAI Alibaba 1.0.3+
免费渠道:
- 为Spring Ai Alibaba开源社区解决解决有效的issue or 提供有价值的PR,可免费获取上述教程
- 往届微信推文
收费服务:收费69.9元
- 飞书在线云文档
- Spring AI会员群教程代码答疑
学习交流圈
你好,我是影子,曾先后在🐻、新能源、老铁就职,兼任Spring AI Alibaba开源社区的Committer。目前新建了一个交流群,一个人走得快,一群人走得远,另外,本人长期维护一套飞书云文档笔记,涵盖后端、大数据系统化的面试资料,可私信免费获取




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









