 多机环境下MPI并行编程实验报告
多机环境下MPI并行编程实验报告





实验目的
- 学习编制多进程并行程序实现如下功能:
- 创建多进程,输出进程号和进程数。
- 运行多进程并行例子程序。
- 编程实现大规模矩阵的并行计算。
实验过程及结果分析
实验环境
- 操作系统:Ubuntu 20.04
- 开发工具:GCC 9.3.0、OpenMPI 4.0.3
实验步骤
多主机无密码登录配置
-
在任意一台主机上生成RSA密钥对:
ssh-keygen -t rsa -C "Kevin"
该命令将在用户主目录下的 ~/.ssh/ 目录中生成id_rsa和id_rsa.pub两个文件。
-
将生成的公钥内容追加至同目录下的
authorized_keys文件中,授权本主机信任该密钥登录:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys此时,将该
authorized_keys文件拷贝到其他主机,以建立互信。 -
为便于多主机通信与配置,使用以下命令将三台主机分别命名为
master、slave1和slave2:sudo vim /etc/hostname -
编辑
/etc/hosts文件,添加各主机的IP与主机名映射,例如:192.168.1.100 master 192.168.1.101 slave1 192.168.1.102 slave2 -
重启三台主机,而后使用
ssh [username]命令测试主机间的无密码登录是否生效。
安装MPI环境
-
在三台主机上分别执行以下命令安装MPI环境:
sudo apt install openmpi-bin libopenmpi-dev -
验证安装是否成功:
mpicc --version mpirun --version
 |
| 图 1 安装成功后会显示版本信息 |
配置NFS共享目录
在多主机运行MPI程序时,所有节点需要访问相同的可执行文件和输入输出路径。如果每台主机都独立保存一份代码和数据,会导致维护成本较高且容易出错。因此,此次实验使用NFS(网络文件系统)在master节点上创建共享目录,并将其挂载到所有计算节点,从而确保各节点读取到的是同一份程序和数据。
具体步骤如下:
-
在
master节点上配置NFS服务:-
安装NFS服务端:
sudo apt install nfs-kernel-server -
创建共享目录并设置权限:
sudo mkdir -p /home/ubuntu/shared sudo chown -R ubuntu:ubuntu /home/ubuntu/shared -
在
/etc/exports文件中添加:/home/ubuntu/shared *(rw,sync,no_subtree_check) -
重启NFS服务使配置生效:
sudo exportfs -a sudo systemctl restart nfs-kernel-server
-
-
在
slave1和slave2节点上挂载共享目录:-
安装NFS客户端:
sudo apt install nfs-common -
创建本地挂载点:
sudo mkdir -p /home/ubuntu/shared -
挂载共享目录:
sudo mount master:/home/ubuntu/shared /home/ubuntu/shared
-
挂载完成后,从节点可直接访问/home/ubuntu/shared目录,并与master节点保持实时同步。
MPI程序测试
单主机多进程测试
在master节点上编译运行下面的MPI程序,验证并行能力,如果主机的核心数不够,可添加 --oversubscribe 参数从而允许多个进程共享核心。
#include <mpi.h>
#include <stdio.h>
int main(int argc, char **argv)
{
MPI_Init(&argc, &argv);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
printf("Hello from rank %d out of %d processors\n", world_rank, world_size);
MPI_Finalize();
return 0;
}
运行结果:
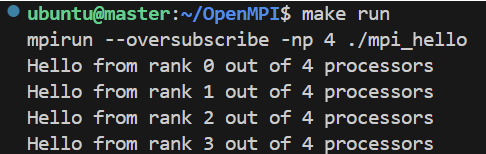 |
| 图 2 单主机多进程测试结果 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6506
6506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











