



关注、星标公众号,精彩内容每日送达
来源:网络素材一、前言
本文将介绍Vivado进行综合,以及布局布线的内部流程,熟悉该流程后结合Settings中对应的配置选项,对于时序收敛调试将更具有针对性。
二、Implementation(实现)
实现流程由一系列的子流程组成,包括:Design Initialization设计初始化、Opt Design设计优化、Power Opt Design功率优化【可选项】、Place Design布局、Post-Place Power Opt Design布局后期设计功率优化【可选项】、Post-Place Phys Opt Design布局后期设计物理优化【可选】、Route Design布线、Post-Route Phys Opt Design布线后期设计物理优化【可选项】、Write Bitstream写入比特流、Write Device Image写入器件备份文件。
下面将重点介绍和布局布线相关的流程,其他简略带过。
Opt Design:对逻辑设计进行优化,使其与器件匹配
Power Opt Design: 对设计的单元进行优化从而降低功耗
Place Design:将设计布局到器件上
Post-Place Power Opt Design:在布局后进行进一步的优化来降低功耗
Post-Place Phys Opt Design:对时序违例的路径进行优化
Route Design:对于布局后的设计进行布线
Post-Route Phys Opt Design:通过实际的布线延时值进行逻辑,布局,布线优化
Write Bitstream :生成器件配置的比特流
Write Device Image:生成器件备份文件
三、布局布线
3.1 Placement(布局)
布局通俗理解就是布局器会将来自网表的单元布局到芯片的确定位置,可细分为7个子流程。
3.1.1 设计布局优化
布局优化对象主要是时序违例路径较大的单元,线长较大的部分以及通过监控引脚密度来提前进行布局分散从而避免后期布线拥塞
3.1.2 设计规则检查
开始布局前,会先进行设计规则检测DRC,DRC有两类,一类是用户在report_drc中设置的规则,另一类是软件自定义的规则,如存储器IP单元没有进行位置约束或者是IO banks和IO标准冲突
3.1.3 布局时钟单元和I/O
完成DRC后,布局器会优先布局时钟单元和I/O单元。时钟和I/O一般是同时进行布局的,因为在指定器件中,布局规则中二者关联性很强。对于Ultrascale/Ultrascale+系列的器件,布局器也布局时钟轨道,对时钟预布线。如果触发器会合并进入到I/O逻辑单元,也在这阶段进行布局,否则布局失败时,会有严重告警打印。
在这一阶段,布局器要完成的布局对象有I/O端口和与之关联的逻辑,全局时钟缓冲器,时钟管理单元(MMCMS和PLL),GT单元。同时,布局器也要考虑设置的位置约束属性和区域约束属性。
当时钟或I/O布局失败时,布局报告会打印相关错误,对错误进行简单描述。通常,布局失败的原因有以下几点
a. 因为约束冲突导致的时钟树问题
b.过于复杂的时钟树问题
c.RAM和DSP 布局与其他约束冲突
d.资源不足
f.违反了I/O bank的一些规则
3.1.4 全局布局,详细布局和后期布局优化
完成时钟和I/O布局后,依次是全局布局,详细布局,后期布局优化。
3.1.4.1 全局布局
全局布局分为布局资源规划(floorplanning)和物理综合。布局资源在I/O和时钟布局后被分成很多小的相关联的逻辑,Pblock约束是需要考虑的,是硬性要求。
在布局资源规划后是物理综合,在基于布局资源规划基础上,布局器将对网表运行不同的物理优化策略进行设计的初始化布局。例如,基于复制的扇出,复制的驱动源将和load放一起,因为初始位置是确定的。优化也会考虑内部的参数设置以及时序相关的。只有时序有所改善,优化才会真正进行。
在物理综合阶段,下图是优化概要示例。
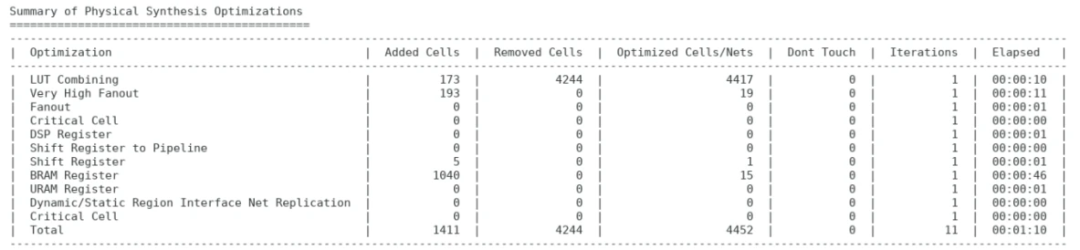
LUT的分解与重组: 如果LUTs有SOFT_HLUTNM属性并且LUT分解和重组能改善时序,布局器将进行该操作
基于属性的重定时:用户可以通过设置一个属性在寄存器或LUT上实行重定时,对于时序起点和终点有足够距离的关键路径来说作用较明显。在PSIP有两个控制重定时的属性:PSIP_RETIMING_BACKWARD,PSIP_RETIMING_FORWARD,值都设置为true时表示执行后向重定时和前向重定时。
同时,在以下场景下设置重定时属性将不会起作用
a.移动的逻辑经过了一些大块单元,如BRAM,URAM,DSP
b. pack到了I/O上的寄存器
c.路径的起点与终点时钟不同
d.路径上含有时序例化的设置
e.含有阻止优化的属性,如DONT_TOUCH等
高扇出优化:高扇出通过复制寄存器来驱动高扇出nets(扇出大于1000,slack值小于2ns)
关键单元优化:在失败路径上通过复制单元来进行优化,如果已布局的单元的load距离太远,该单元将会被赋值然后放置到距离load更近的位置。通常在一些块状RAM,URAM,大量的DSP布局较为分散时,该优化使用较多
扇出优化:对于设置了MAX_FANOUT的nets,当nets的实际扇出数量大于设置的MAX_FANOUT时,将会进行优化。用户可以通过添加FORCE_MAX_FANOUT到该nets上,从而强制对驱动该nets的寄存器或LUT进行复制,并且此处提到的load都是实际物理连接的loads,不是逻辑loads。
DSP寄存器优化:DSP寄存器优化是指将寄存器从DSP中移出到逻辑组中,或者从逻辑单元移入到DSP中,从而改善关键路径的时延
移位寄存器流水线优化:操作是将有固定长度的移位寄存器改成动态调整寄存器流水线,然后再布局流水线流水线来改善时序,动态的SRLs不支持该优化
移位寄存器优化:该优化是针对在移位寄存器单元和其他逻辑单元间存在时序违例的路径
块状RAM寄存器优化:块状RAM寄存器优化是指将寄存器从块状RAM中移出到逻辑组中,或者从逻辑单元移入到块状RAM中,从而改善关键路径的时延
动态/静态区域接口网线复制:在DFX流程中,将静态设计复制到可重配的模块便捷路径上
等价驱动源重布线优化:将逻辑上相等的驱动源进行load的重新分配,减少布线的重复,也能为驱动源和负载提供更优的位置。这个可以减少资源使用和布线拥塞
3.1.4.2 详细布局
通过详细布局,可以让设计从初始化的全局布局成为全部布局。通常是先对大块单元,如多列的URAM,块状RAM,DSP块组布局,然后是LUTRAM组,用户在XDC中定义的更小一些的大块。逻辑单元布局时是不断迭代,以保证线长,时序最优,不拥塞。在CLBs的LUT-FF对和CLB中的寄存器必须共用普通的控制集
3.1.4.3 后期布局优化
在所有的逻辑单元位置都确定后,后期布局优化将进行改善时序和拥塞的最后一步,包括改善关键路径的布局,BUFG复制,可选的BUFG插入。在BUFG复制阶段,BUFG驱动的nets跨多个SLRs时,每个SLRs都会分配一个BUFG。在布局或布线冲突,以及有阻止复制或时钟降级的约束时,该优化将不会进行。
在BUFG插入阶段,布局器将高扇出的net布线到全局布线路径上,从而释放普通布线资源,驱动控制信号的高扇出nets如果slack值大于1ns将会优化。
3.2 Routing(布线)
在完成布局后,布线器将会进行布线。布线器提供了2个布线选项,对整个设计布线或对单个的引脚或nets布线。当对整个设计布线时,流程是时序驱动的,在时序约束的基础上,使用自动的时序计算规则。当对单个nets或引脚布线时,有迭代布线和自动延时两种模式。
布线的子流程包括:设计规则检查DRC,布线优先级。
3.2.1 设计规则检查
设计规则检查主要有两类检查,第一类是用户从report_drc中设置的规则,第二类是vivado软件内部的检查规则
3.2.2 布线优先级
布线器首先布线全局资源,如时钟,复位,I/O和其他降级的资源。在布线器内部有默认的优先级,然后根据时序重要性对数据信号布线。
(全文完)

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索



















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









