



文章来源于百家号:GPU服务器厂家
随着Deepseek的火爆,英伟达的5090、4090、A100、A800、H100、H800、H200、H20等显卡越来越紧张,这些显卡在配置服务器的时候有什么区别?该如何选择?以下是基于最新行业数据与多源信息整合的英伟达显卡(包括RTX 5090、4090、A100、A800、H100、H800、H200、H20)在服务器配置中的深度对比分析,涵盖核心参数、应用场景及市场现状。
一、显卡核心参数与架构对比
1. 消费级显卡:RTX 4090/5090
RTX 4090
架构: Ada Lovelace
CUDA核心: 16384个,支持第三代光追核心与DLSS 3
显存: 24GB GDDR6X,带宽1 TB/s
功耗: 450W,单槽散热设计
适用场景: 实时渲染、云游戏(4K 120FPS)、轻量级AI推理(需优化显存管理)

RTX 5090
架构: Blackwell(4nm工艺)
CUDA核心: 预计超20000个,支持DLSS 4多帧生成技术
显存: 32GB GDDR7,带宽1.5 TB/s
优势: 4K 240FPS全光追游戏、AI推理效率提升50%以上
2. 数据中心级显卡:A系列与H系列
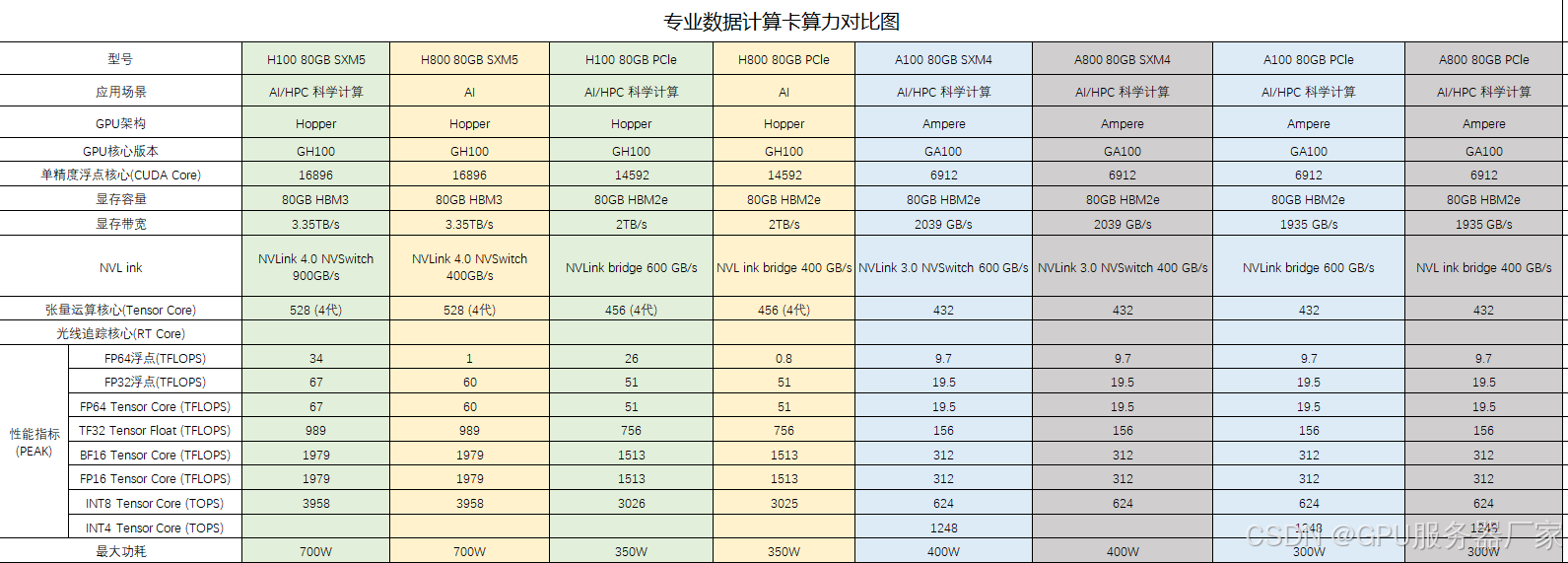
A100/A800
架构: Ampere
CUDA核心: 6912个(A100)
显存: A100提供40GB/80GB HBM2e(带宽1.6/2.0 TB/s),A800参数相同但互联带宽受限
NVLink: A100支持600GB/s,A800降至400GB/s
FP64性能: 19.5 TFLOPS(A100),适合科学计算

H100/H800/H200
架构: Hopper(H100/H800)、Hopper升级版(H200)
CUDA核心: H100达18432个,H200核心数未公布但显存升级至141GB HBM3e
显存带宽: H100为3 TB/s,H200提升至4.8 TB/s
FP8支持: H100/H800支持第四代Tensor Core,FP8计算效率是A100的6倍
互联限制: H800的NVLink带宽为H100的50%(450GB/s vs 900GB/s)

H20(中国特供版)
架构: Hopper阉割版
显存: 96GB HBM3,带宽3 TB/s
性能: 推理性能约为H100的30%,训练性能受限

二、性能与应用场景适配分析
1. AI训练与推理
千亿参数模型(如GPT-4):
首选: H200(141GB HBM3e显存,支持单卡大模型加载)
次选: H100(80GB显存,需多卡并行)
优势: H200的Transformer引擎可加速LLM推理速度2倍以上
百亿参数级模型(如BERT-Large):
性价比方案: A100(80GB版)+ NVLink全互联,多卡训练效率比A800高25%
限制: A800因带宽限制,多卡扩展性差,仅适合小规模集群

2. 高性能计算(HPC)
科学模拟(气候建模、分子动力学):
推荐: A100(FP64双精度性能19.5 TFLOPS)
对比: H100的FP64性能为HPC场景优化不足,但FP16/FP8混合精度性能领先
基因测序与药物研发:
多实例GPU(MIG): A100支持将单卡分割为7个独立实例,提升任务并行度
3. 图形渲染与云服务
实时渲染农场:
消费级方案: RTX 5090(DLSS 4技术降低服务器负载,支持8K实时渲染)
企业级方案: H200(支持多路4K流媒体编码,功耗比优化30%)
云游戏与虚拟桌面(VDI):
主流选择: RTX 4090(单卡支持50+用户并发,NVENC编码效率提升40%)

三、市场策略与采购考量
1. 供应与价格动态
国际供应链风险:
A100/H100因出口管制在中国市场稀缺,现货溢价达50%-100%
H800/A800交货周期6-12个月,需提前锁定订单
2. 能效与运维成本
功耗对比:
H100(700W)较A100(400W)性能提升3倍,但单位算力功耗降低15%
RTX 4090(450W)能效比优于旧款Tesla V100(250W)
散热设计:
数据中心级显卡(如H200)支持液冷方案,可降低PUE至1.1以下

四、选型决策树与总结
1. 预算充足且无出口限制:
超大规模训练: H200 > H100
混合负载HPC: A100(FP64优势)
2. 受限市场(如中国):
大模型推理: H800(显存容量妥协,但带宽受限)
中型训练集群: A800 + 优化互联拓扑
3. 边缘计算与实时响应:
低延迟推理: H200(141GB显存支持本地化模型部署)
轻量级AI: RTX 4090(低成本入门方案)
4. 长期运维视角:
能效优先: H100(4nm工艺,TCO更低)
扩展性需求: 选择支持NVLink全互联的型号(避免PCIe瓶颈)

五、未来趋势与风险提示
技术迭代: 2025年Blackwell架构RTX 5090可能冲击中端AI推理市场
政策风险: 美国或进一步限制A800/H800规格,需关注供应链备选方案
生态兼容性: 国产GPU需解决CUDA生态迁移成本,短期内难以替代英伟达
通过上述分析,用户可结合性能需求、预算及政策限制,制定最优显卡配置策略。建议定期评估硬件升级路径与国产替代进展,以应对快速变化的技术与市场环境。

















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









