





大家好,欢迎阅读这份《智能体(AI+Agent)开发指南》!
在大模型和智能体快速发展的今天,很多朋友希望学习如何从零开始搭建一个属于自己的智能体。本教程的特点是 完全基于国产大模型与火山推理引擎实现,不用翻墙即可上手,非常适合国内开发者快速实践。
通过循序渐进的讲解,你将学会从 环境配置、基础构建、进阶功能到实际案例 的完整流程,逐步掌握智能体开发的核心技能。无论你是初学者还是有经验的工程师,相信这份教程都能为你带来启发。
理论:索引增强生成(RAG)
一. 火山引擎Embedding替换OpenAIEmbeddings指南
创建了一个自定义的VolcanoEmbeddings类,可以无缝替换OpenAIEmbeddings
import requests
import numpy as np
from typing import List, Union
from langchain.embeddings.base import Embeddings
class VolcanoEmbeddings(Embeddings):
"""火山引擎文本嵌入类,可以替代OpenAIEmbeddings"""
def __init__(self, api_key: str = None, model_name: str = "doubao-embedding-text-240715"):
"""
初始化火山引擎嵌入
Args:
api_key: 火山引擎API密钥
model_name: 模型名称
"""
self.base_url = 'https://ark.cn-beijing.volces.com/api/v3'
self.api_key = your_api_key
self.model_name = model_name
def _make_request(self, texts: List[str]) -> List[List[float]]:
"""
发送请求到火山引擎API
Args:
texts: 文本列表
Returns:
向量列表
"""
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {self.api_key}'
}
data = {
"encoding_format": "float",
"input": texts,
"model": self.model_name
}
try:
response = requests.post(
f"{self.base_url}/embeddings",
headers=headers,
json=data,
timeout=30
)
if response.status_code == 200:
result = response.json()
embeddings = []
for item in result['data']:
embeddings.append(item['embedding'])
return embeddings
else:
raise Exception(f"API请求失败: {response.status_code} - {response.text}")
except Exception as e:
raise Exception(f"请求异常: {e}")
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""
为文档列表生成嵌入向量
Args:
texts: 文本列表
Returns:
向量列表
"""
return self._make_request(texts)
def embed_query(self, text: str) -> List[float]:
"""
为单个查询文本生成嵌入向量
Args:
text: 查询文本
Returns:
向量
"""
embeddings = self._make_request([text])
return embeddings[0]
def similarity_search_with_score(self, query: str, documents: List[str], k: int = 4) -> List[tuple]:
"""
自定义相似度搜索,返回标准化的相似度分数
Args:
query: 查询文本
documents: 文档列表
k: 返回结果数量
Returns:
文档和相似度分数的元组列表
"""
# 获取查询向量
query_vector = self.embed_query(query)
# 获取文档向量
doc_vectors = self.embed_documents(documents)
# 计算相似度分数
similarities = []
for i, doc_vector in enumerate(doc_vectors):
# 计算余弦相似度
similarity = np.dot(query_vector, doc_vector) / (np.linalg.norm(query_vector) * np.linalg.norm(doc_vector))
similarities.append((similarity, i))
# 按相似度排序(降序)
similarities.sort(reverse=True)
# 返回前k个结果
results = []
for similarity, idx in similarities[:k]:
results.append((documents[idx], similarity))
return results
# 使用示例
def demo_volcano_embeddings():
"""演示如何使用火山引擎嵌入"""
print("=== 火山引擎嵌入演示 ===")
# 创建嵌入实例
embeddings = VolcanoEmbeddings()
# 测试文档嵌入
documents = [
"人工智能是计算机科学的一个分支",
"机器学习是AI的重要技术",
"深度学习是机器学习的一个子领域"
]
print("正在生成文档嵌入...")
doc_embeddings = embeddings.embed_documents(documents)
print(f"✅ 生成了 {len(doc_embeddings)} 个文档向量")
print(f"每个向量维度: {len(doc_embeddings[0])}")
# 测试查询嵌入
query = "什么是机器学习?"
print(f"\n正在生成查询嵌入: '{query}'")
query_embedding = embeddings.embed_query(query)
print(f"✅ 查询向量维度: {len(query_embedding)}")
# 计算相似度
print("\n计算查询与文档的相似度:")
for i, doc in enumerate(documents):
similarity = calculate_cosine_similarity(query_embedding, doc_embeddings[i])
print(f" '{query}' vs '{doc}': {similarity:.4f}")
return embeddings
def calculate_cosine_similarity(vec1: List[float], vec2: List[float]) -> float:
"""计算余弦相似度"""
vec1 = np.array(vec1)
vec2 = np.array(vec2)
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
if norm1 > 0 and norm2 > 0:
return dot_product / (norm1 * norm2)
else:
return 0.0
if __name__ == "__main__":
demo_volcano_embeddings()
原始代码
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)
替换后的代码
from volcano_embeddings import VolcanoEmbeddings
embeddings = VolcanoEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)
二. 搭建一个文档问答系统
1. 调用火山引擎的示例
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.schema import Document
from volcano_embeddings import VolcanoEmbeddings
def create_rag_with_volcano():
"""使用火山引擎embedding创建RAG系统"""
print("=== 使用火山引擎Embedding的RAG示例 ===")
# 1. 准备文档数据
documents = [
"人工智能(AI)是计算机科学的一个分支,旨在创建能够执行通常需要人类智能的任务的系统。",
"机器学习是AI的一个子领域,它使计算机能够在没有明确编程的情况下学习和改进。",
"深度学习是机器学习的一个分支,使用神经网络来模拟人脑的学习过程。",
"自然语言处理(NLP)是AI的一个分支,专注于计算机理解和生成人类语言的能力。",
"计算机视觉是AI的一个领域,使计算机能够从图像和视频中获取信息。",
"神经网络和深度学习。"
]
# 2. 创建Document对象
docs = [Document(page_content=text, metadata={"source": f"doc_{i}"})
for i, text in enumerate(documents)]
print(f"✅ 准备了 {len(docs)} 个文档")
# 3. 文本分割
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="。"
)
chunks = text_splitter.split_documents(docs)
print(f"✅ 分割成 {len(chunks)} 个文本块")
# 4. 使用火山引擎embedding替代OpenAIEmbeddings
print("\n正在使用火山引擎生成嵌入向量...")
embeddings = VolcanoEmbeddings()
# 5. 创建向量数据库
print("正在创建向量数据库...")
vectorstore = Chroma.from_documents(chunks, embeddings)
print(f"✅ 向量数据库创建成功: {vectorstore}")
print(f"向量数据库中的文档数量: {vectorstore._collection.count()}")
# 6. 测试检索功能
print("\n=== 测试检索功能 ===")
test_queries = [
"什么是机器学习?",
"深度学习有什么特点?",
"计算机视觉是什么?"
]
for query in test_queries:
print(f"\n查询: '{query}'")
# 检索相似文档
results = vectorstore.similarity_search(query, k=2)
print("检索结果:")
for i, result in enumerate(results, 1):
print(f" {i}. {result.page_content}")
print(f" 元数据: {result.metadata}")
return vectorstore
def similarity_search_demo(vectorstore):
"""演示相似度搜索"""
print("\n=== 相似度搜索演示 ===")
query = "神经网络和深度学习"
# 使用相似度搜索
results = vectorstore.similarity_search_with_score(query, k=2)
print(f"查询: '{query}'")
print("搜索结果:")
for i, (doc, score) in enumerate(results,2):
print(f" {i}. 相似度: {score:.4f}")
print(f" 内容: {doc.page_content}")
print(f" 元数据: {doc.metadata}")
print()
if __name__ == "__main__":
# 创建RAG系统
vectorstore = create_rag_with_volcano()
# 演示相似度搜索
similarity_search_demo(vectorstore)
2. 完成一个简单的文档问答系统
import warnings
import logging
from langchain_community.document_loaders import PyPDFLoader
from volcano_embeddings import VolcanoEmbeddings
from langchain_chroma import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
# 忽略PDF解析警告
warnings.filterwarnings("ignore", category=UserWarning)
logging.getLogger("pypdf").setLevel(logging.ERROR)
class RAGSystem:
def __init__(self, pdf_path, api_key, base_url, model_name):
self.pdf_path = pdf_path
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.llm = None
self.vectorstore = None
self.qa_chain = None
def initialize_llm(self):
"""初始化大语言模型"""
self.llm = ChatOpenAI(
api_key=self.api_key,
base_url=self.base_url,
model_name=self.model_name,
temperature=0.7,
max_tokens=2000,
timeout=30,
max_retries=3,
)
def load_and_process_documents(self):
"""加载和处理PDF文档"""
try:
loader = PyPDFLoader(self.pdf_path)
docs = loader.load()
print(f"✅ 成功加载PDF文档,共 {len(docs)} 页")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=20
)
chunks = text_splitter.split_documents(docs)
print(f"✅ 文档分割完成,共生成 {len(chunks)} 个文本块")
return chunks
except Exception as e:
print(f"❌ 文档处理失败: {e}")
return None
def create_vectorstore(self, chunks):
"""创建向量数据库"""
try:
embeddings = VolcanoEmbeddings()
self.vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings
)
print("✅ 向量数据库创建成功")
return True
except Exception as e:
print(f"❌ 向量数据库创建失败: {e}")
return False
def setup_qa_chain(self):
"""设置问答链"""
try:
retriever = self.vectorstore.as_retriever()
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=retriever
)
print("✅ 问答系统初始化成功")
return True
except Exception as e:
print(f"❌ 问答系统初始化失败: {e}")
return False
def initialize(self):
"""初始化整个RAG系统"""
print("🚀 正在初始化RAG系统...")
self.initialize_llm()
chunks = self.load_and_process_documents()
if chunks is None:
return False
if not self.create_vectorstore(chunks):
return False
if not self.setup_qa_chain():
return False
print("🎉 RAG系统初始化完成!")
return True
def ask_question(self, question):
"""提问并获取答案"""
try:
result = self.qa_chain.invoke(question)
return result
except Exception as e:
return f"❌ 回答问题失败: {e}"
def run_interactive(self):
"""运行交互式问答"""
print("\n" + "="*50)
print("🤖 RAG问答系统已启动")
print("💡 输入 'quit' 或 'exit' 退出系统")
print("="*50)
while True:
try:
question = input("\n❓ 请输入问题: ").strip()
if question.lower() in ['quit', 'exit', '退出']:
print("👋 感谢使用,再见!")
break
if not question:
print("⚠️ 请输入有效问题")
continue
print("🔍 正在搜索答案...")
result = self.ask_question(question)
print(f"\n💬 答案: {result}")
except KeyboardInterrupt:
print("\n👋 用户中断,退出系统")
break
except Exception as e:
print(f"❌ 系统错误: {e}")
def main():
"""主函数"""
# 配置参数
config = {
'pdf_path': "./3551-2024.pdf",
'api_key': 'your_api_key',
'base_url': 'https://ark.cn-beijing.volces.com/api/v3',
'model_name': 'doubao-1-5-pro-32k-250115'
}
# 创建RAG系统
rag_system = RAGSystem(**config)
# 初始化系统
if rag_system.initialize():
# 运行交互式问答
rag_system.run_interactive()
else:
print("❌ RAG系统初始化失败,请检查配置和文件")
if __name__ == "__main__":
main()
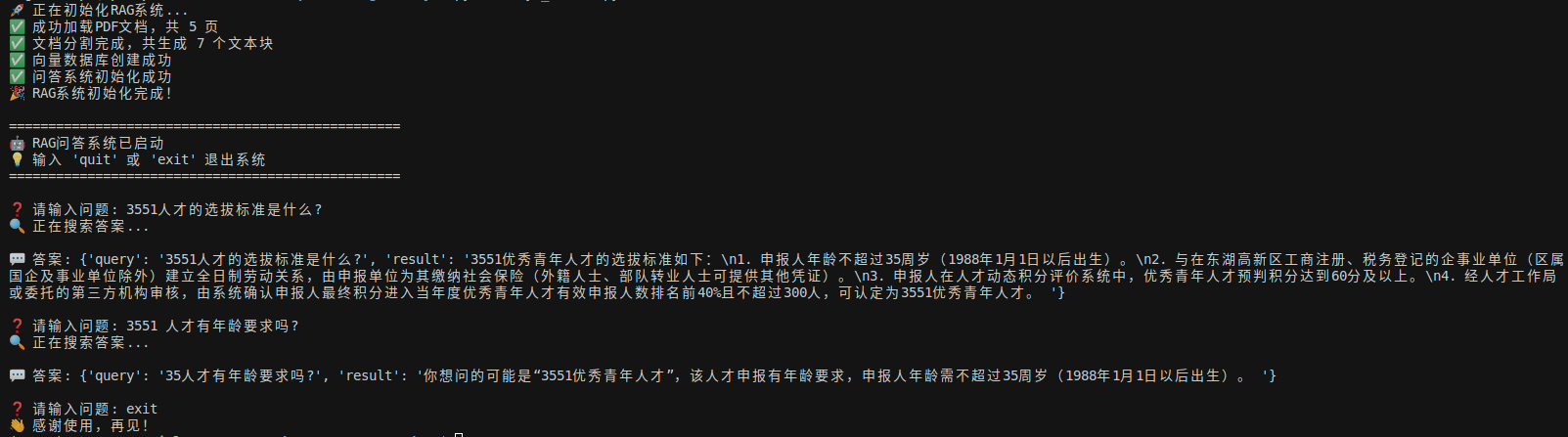
3. 效果演示
欢迎关注微信公众号:AIWorkshopLab,自动获取完整教程:智能体(AI+Agent)开发指南.pdf。



















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











