




1. 引言
最近两年随着LLM爆发式的发展,以LLM为主体框架的模型逐渐渗透到CV、语音、智驾等多领域,并成为各领域的顶流,效果纷纷超越了一些传统的模型。本人最近在系统梳理多模态的技术栈,梳理的路线也是主要沿着基于LLM的多模态技术进行学习。整理过程中,试了一些模型效果,结果被Qwen2.5-VL的效果惊艳到了,索性就想沿着Qwen-VL系列缕清楚整体技术脉络。
在梳理Qwen-VL系列前,我们先以更通用的视角简单了解下基于LLM的多模态模型的设计框架,方便我们先了解下业界通用的做法,也了解一些基本的概念。下图总结了多模态大语言模型的通用模型框架和每个模块的一些实现方法。
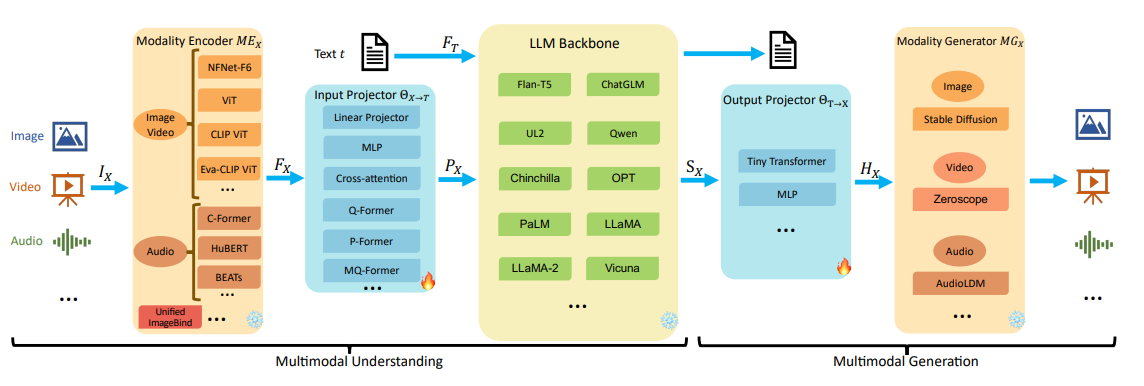
模态编码器(Modality Encoder):将多模态的数据编码成向量空间特征,该模块通常是单独进行预训练的,典型的方法有基于CNN的ResNET,基于Transformer的ViT等。
输入投影层(Input Projector):将模态编码器的输出映射到LLM的输入特征空间的适配层,一般模型结构比较简单,不同的多模态模型一般是随机初始化该模块的参数做冷启训练。典型的网络层:MLP,Cross-Attention等
LLM主干网络(LLM Backbone):LLM是经过预训练的模型,一般还要串联多个模块继续做Post-Pretrain和微调,使得模型能识别多模态的特殊token和多模态的特征输入。
输出投影层(Output Projector):将LLM生成的数据,映射成Modality Generator 可理解的特征空间,一般是简单的Transformer层或MLP层。
模态生成器(Modality Generator):多模态的生成器,最终输出多模态的结果如图像、语音、视频等。模型基本都是基于LDM(Latent Diffusion Models)的衍生模型,如图片领域的Stable Diffusion方法。
一般这五个模块中,模态编码器,LLM和模态生成器可以是基于大规模样本Pretrain好的模型,然后通过两个投影层,将各个模块串接起来。模型训练一般是通过预训练阶段充分训练Projector层,再按需精细化微调各模块,最终达到理想的端到端的模型效果。
在多模态场景,通常包括两类任务:理解任务 和 生成任务。对应的模型分别是多模态理解模型和多模态生成模型
- 多模态理解模型: 主要包括前三个模块(模态编码器,输入投影层,LLM主干网络),即模型接受多模态数据输入,以文本形式输出。
- 多模态生成模型:包括全部5个模块,即多模态数据输入,多模态数据输出,多模态生成模型通常要更复杂,也能难建模。
以上介绍完了通用的MM-LLM的框架。本文梳理的Qwen-VL模型是一系列视觉+文本多模态理解模型,即LVLM(Large-scale Vision-Language Model),主要处理文本和视觉特征,输入Text、Image、Video,输出Text。
目前Qwen共发布3个版本,分别为:Qwen-VL,Qwen2-VL,Qwen2.5-VL,共有7个不同尺寸的模型,如下表:
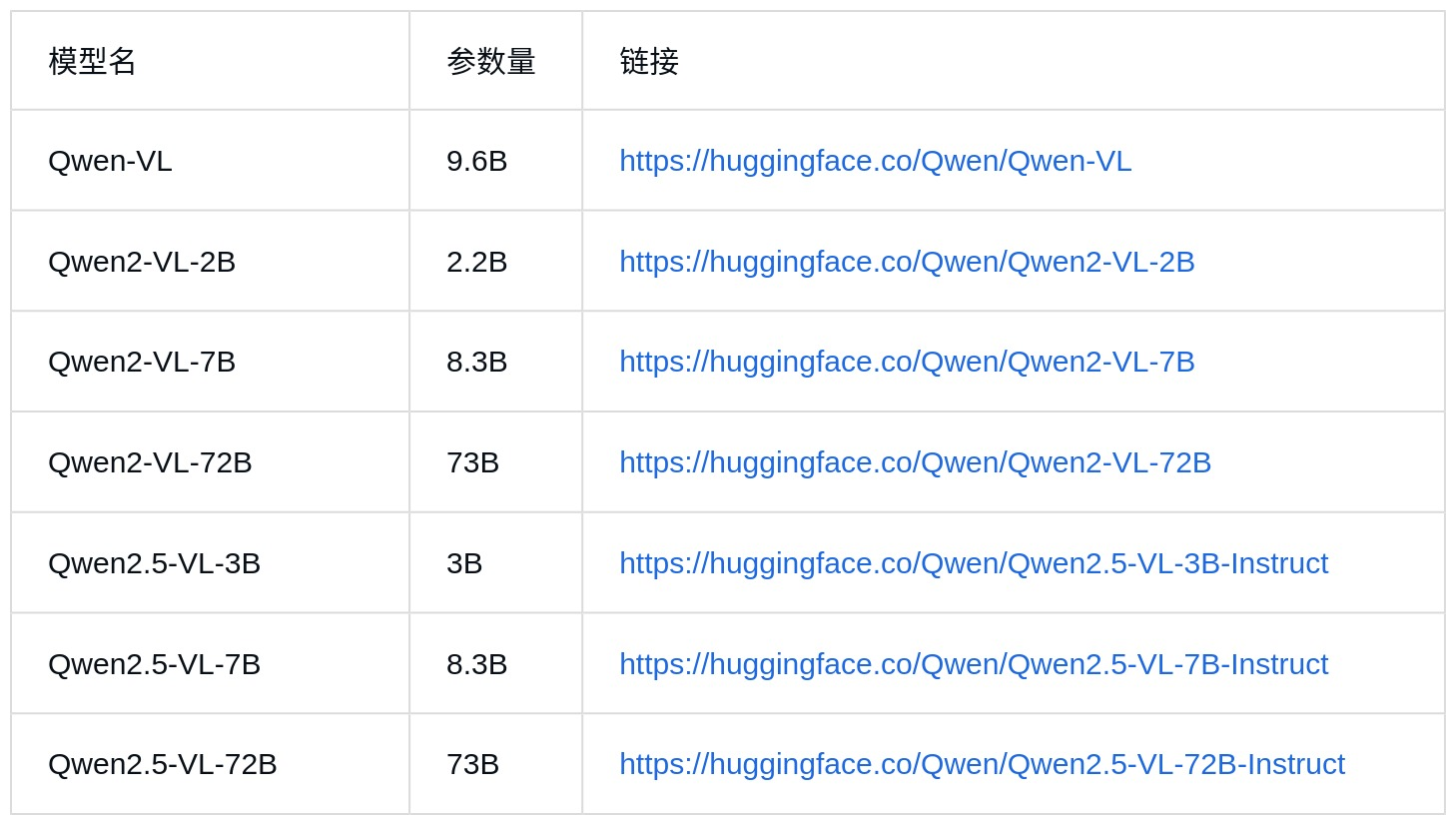 注: 上表只列出了几个主要的版本,并没有列出一些衍生版本的模型,Qwen发布的模型还包括:量化、指令微调等模型版本
注: 上表只列出了几个主要的版本,并没有列出一些衍生版本的模型,Qwen发布的模型还包括:量化、指令微调等模型版本
下面我们来详细看看QwenVL系列模型都做了哪些工作。
2. Qwen-VL
Qwen-VL 是以Qwen-7B Base为主干模型,通过引入视觉感知器(Visual receptor)来增强视觉特征的感知能力。视觉感知器包括一个跟语言模型对齐视觉编码器(visual encoder)和一个位置感知的适配器(position- aware adapter)。套用上面的通用多模态框架,Qwen-VL包括了典型的前3个模块:
- 模态编码器(Modality Encoder) : 视觉编码器(visual encoder),只用来编码图片视觉特征
- 输入投影层(Input Projector):位置感知的适配器(position-aware adapter)
- LLM主干网络(LLM Backbone): Qwen-7B Base 模型
下面我们分别来看看Qwen-VL的两个核心模块:视觉编码器、感知位置的适配器。接着描述一些规范化样本处理过程,最后描述下模型的训练过程。
2.1 视觉编码器(Visual Encoder)
Qwen-VL的视觉编码器使用的是ViT架构(Vision Transformer),ViT的网络设置和初始化参数使用了OpenCLIP预训练好的ViT-bigG模型。OpenCLIP是laion.ai组织的一个开源项目,是对OpenAI’s的CLIP(Contrastive Language-image Pre-training)的开源实现。laion.ai发布了一系列基于CLIP框架训练的不同size模型,同时他也为CV领域贡献了大量的开源数据,ViT-bigG是经过了2B的训练数据训出来的ViT模型。
Qwen-VL使用的ViT(ViT-bigG)是基于CLIP框架训练的,CLIP是通过Contrastive Learning的方式来学习Vision和文本的表征。如下图所示:模型训练采用了对比损失函数,通过最大化正例Pair的相似度,同时最小化负例Pair的相似度来训练模型。通过这种方式,能学习到视觉特征和文本特征的对齐关系。最后将训练好的Image Encoder模型(即ViT)参数保存下来,以供其他下游任务热启使用。
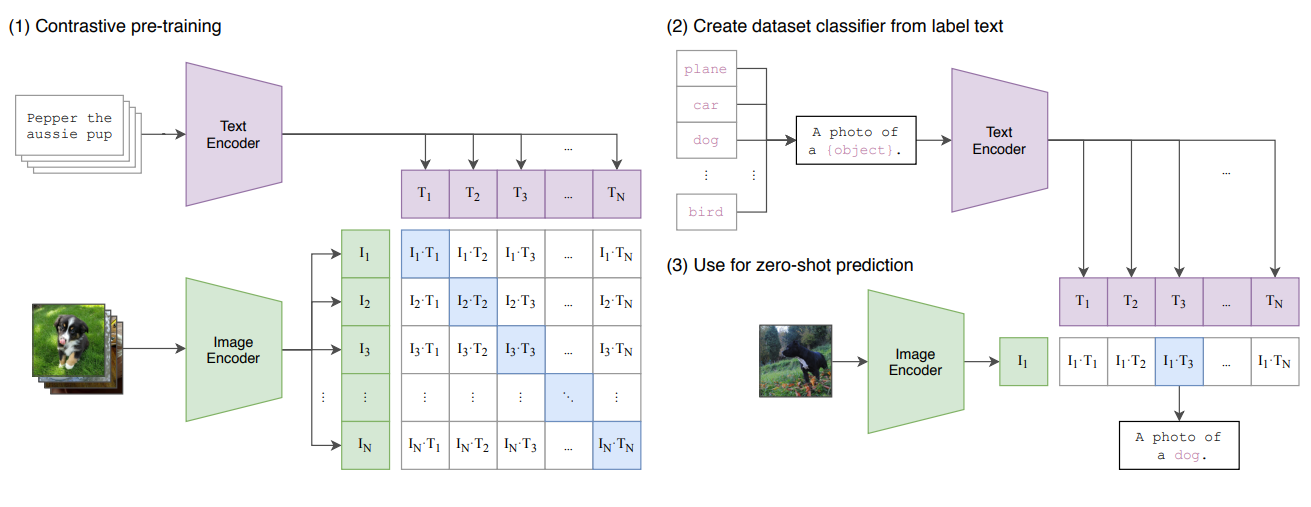
CLIP的训练过程:模型的输入是图片和文字的配对,图片输入到图片的encoder得到一些特征,文本输入到文本的encoder得到一些特征,每个traning batch里有n个图片-文本对,就能得到n个图片的特征和n个文本的特征,然后在这些特征上做对比学习,对比学习非常灵活,就需要正样本和负样本的定义,其它都是正常套路(不懂对比学习),配对的图片-文本对就是正样本,描述的是同一个东西,特征矩阵里对角线上的都是正样本,矩阵中非对角线上的元素都是负样本,有了正负样本,模型就可以通过对比学习的方式去训练了,不需要任何手工标注。这种无监督的训练方式,是需要大量的训练数据的。
CLIP的推理过程:预训练之后只能得到文本和图片的特征,是没有分类头的,作者提出一种利用自然语言的方法,prompt template。比如对于ImageNet的类别,首先把它变成"A photo of a {object}" 这样一个句子,ImageNet有1000个类,就生成1000个句子,然后这1000个句子通过之前预训练好的文本的encoder能得到1000个文本特征。直接用类别单词去抽取文本特征也可以,但是模型预训练的时候和图片配对的都是句子,推理的时候用单词效果会下降。把需要分类的图片送入图片的encoder得到特征,拿图片的特征和1000个文本特征算余弦相似性,选最相似的那个文本特征对应的句子,从而完成了分类任务。不局限于这1000个类别,任何类别都可以。彻底摆脱了categorical label的限制,训练和推理的时候都不需要提前定义好的标签列表了。
CLIP的详细讲解可参考 :CLIP原理解读
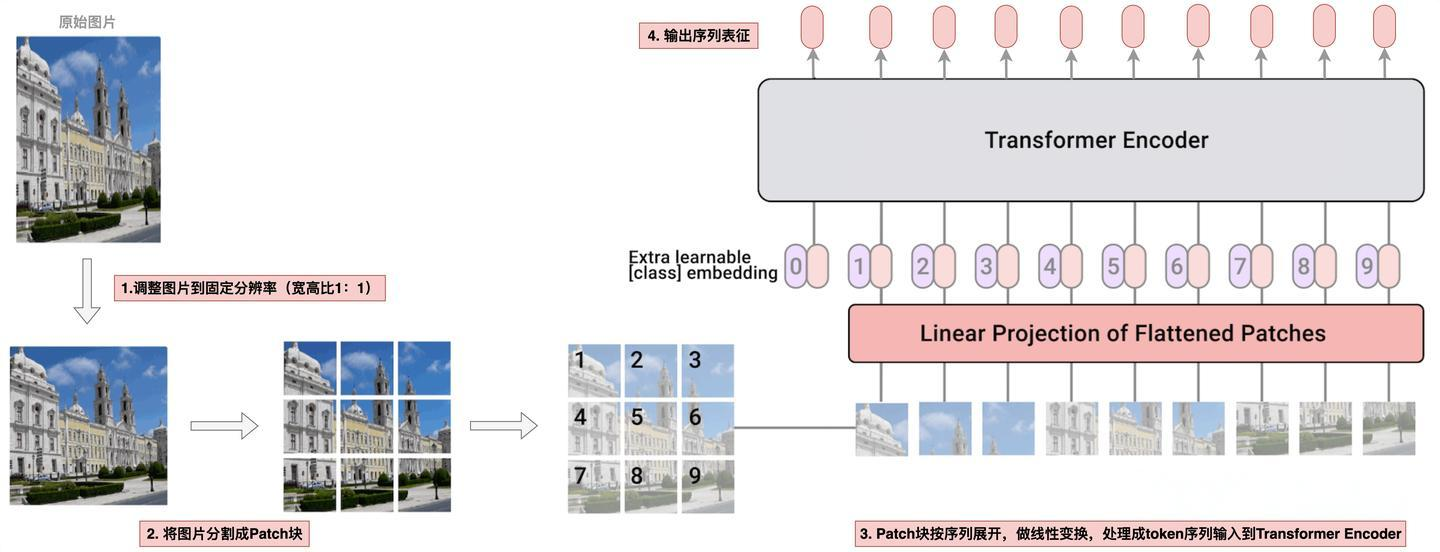
在Qwen-VL中采用的是标准的ViT框架,ViT的原理比较简单:将图片分割成多个图像块(Patch),然后针对每个Patch通过一系列线性映射,转化成token,再将所有token拼接成序列,最终将一张图片从 (H,W,C)格式转换成 (S,H) 格式的序列特征。其中 H :高, W :宽, C : 通道数, S : 序列长度, H :特征维度。在标准的ViT实现上,输入图片会先被调整成长宽比 1:1 的正方形,然后再分割成固定的图像块。
因此这种标准的ViT框架的设计,只能接收固定分辨率的图片,同时Patch的大小也是模型在训练期间使用的一个固定size。ViT处理过程下图所示:
2.2 输入投影层:感知位置的视觉-语言适配器(Position-aware Vision-Language Adapter )
经过上述ViT处理后,对于 448×448 分辨率的图像,生成一个[1024, 1664]的序列,也就是向量维度为1664的长度为1024的序列。为了压缩视觉token的输入长度,Qwen-VL引入了一个Adapter来压缩图像特征。这个Adaper就是一个随机初始化的单层Cross-Attention模块。该模块使用一组可学习的query向量,将来自ViT的图像特征作为Key向量。通过Cross-Attention操作后将视觉特征序列压缩到固定的256长度。
为了清晰理解这块, 我们还是用图来描述下,如下图所示:

此外,考虑到位置信息对于精细图像理解的重要性,Qwen-VL将二维绝对位置编码(三角位置编码)整合到Cross-Attention的 q, k中,以减少压缩过程中可能丢失的位置细节。随后将长度为256的压缩图像特征序列输入到大型语言模型中。
2.3 输入和输出
对于输入LLM前的特征序列,为了区分图片和文本的输入信息,对图片的feature使用了特殊的token包裹,图像特征的开始和结束用 和 token圈定,来明确标识图像特征的起止位置。同时为了做grounding任务,对图像中bounding box 统一用一个"左上-右下"坐标框格式表示:" (X1,Y1),(X2,Y2) " ,坐标值统一做归一化处理,规范化到 (0,1000) 区间。并用 、 特殊token圈定。 对于描述bounding box的文本,也用 、 两个特殊的token圈定起来。下面图是一条典型的grounding 任务的样本实例:

2.4 训练过程
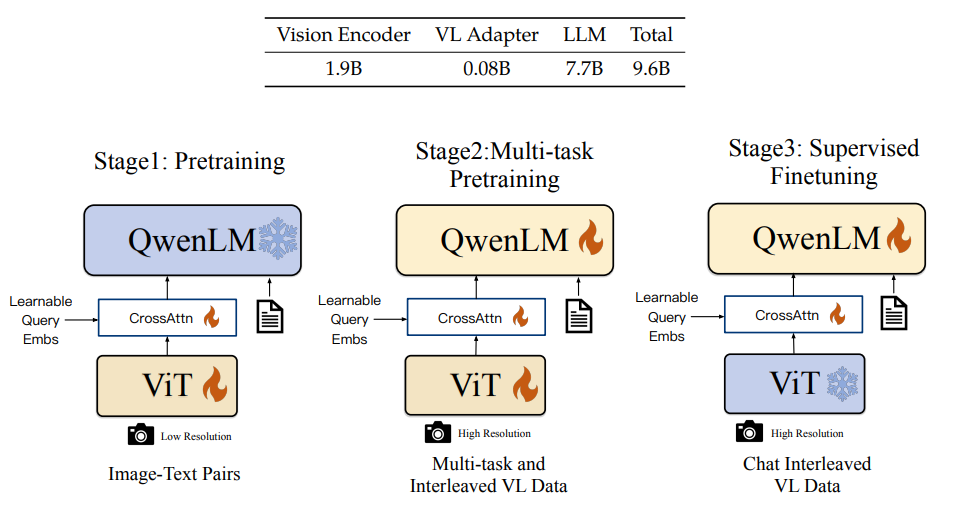
Qwen-VL共分成3个训练阶段,包括两个预训练阶段和一个SFT阶段。
第一阶段:单任务大规模预训练(Pre-training ),主要使用大量网上抓取和内部的图文pair数据做预训练,训练数据有1.4B,英文数据占比77.3%,中文占比22.7%,训练数据的图片统一处理成224×224 的尺寸。该阶段LLM模型参数是frozen的,ViT和Cross-Attention层的参数是激活更新的,这个阶段主要通过大规模数据训练模型的vision模态对齐语言模型的能力。
第二阶段:多任务预训练(Multi-task Pre-training),这个阶段使用了更高分辨率、更高质量的数据,同时引入图文混排的数据。该阶段是个多任务的预训练阶段,包括7个任务,其中有6个Vision任务(包括Captioning ,VQA,grounding等)和1个文本生成任务,这个阶段模型是全参数激活的。该阶段之所以引入文本生成任务,主要是为了保证模型的通用文本处理能力。该阶段的训练数据,Vision数据的分辨率从 224×224 提升到 448×448 ,数据做了精选处理,包括多模态数据69M和 文本数据7.8M。第二阶段的数据量比第一阶段少了2个量级。该阶段训练完成后,最终产出了Qwen-VL base模型。
第三阶段: 指令微调(Supervised Fine-tuning),主要提升模型的指令遵循能力和对话能力。在这个阶段作者对数据做了些数据增强,通过人工标注、模型生成和策略拼接等方式构造多模态的多轮会话数据。该阶段指令集数据共收集了350K。
上面完整描述了Qwen-VL的核心工作,具体做法没有什么大的创新,数据规模和数据多样性上也没有明显的优势,所以Qwen-VL的模型效果基本就是中规中矩,没有太强的表现。下面我们再来看看Qwen2-VL的工作~
3. Qwen2-VL
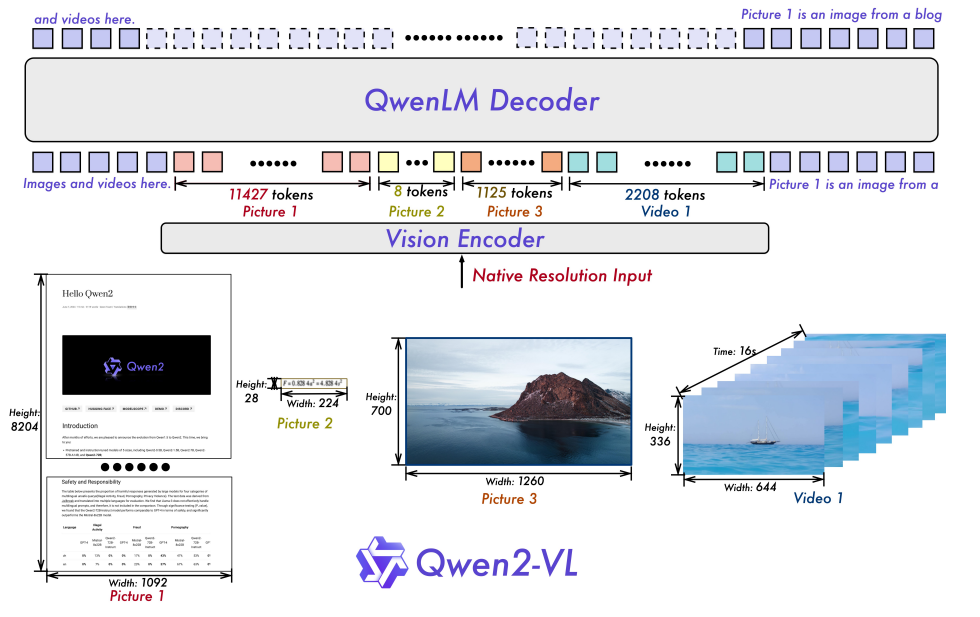
相对于Qwen-VL,Qwen2-VL整体模型架构做的比较大的升级,首先从模型命名上可知,主体模型从Qwen升级到了Qwen2。并且发布了三个size的模型,分别是Qwen2-VL-2B,Qwen2-VL-7B,Qwen2-VL-72B。
除了主干模型的升级,论文中还提到了一些重要的升级点,总结如下:
- 采用原生动态分辨率:单一分辨率 -> 任意分辨率, Qwen-VL模型输入只接受单一分辨率的图片,Qwen2-VL可输入不同分辨率的图像,避免了Vision数据适配单一分辨率而导致的失真问题;
- Vision Encoder位置编码:绝对位置编码 -> 相对位置编码,从二维三角位置编码升级到二维RoPE位置编码,RoPE对长序列有更好的泛化能力,有利于提升对长序列Vision特征的建模能力;
- LLM主体模型位置编码:1D->3D RoPE,引入多模态旋转位置编码技术(M-RoPE),刻画多模态(时序、高、宽)三维数据。进一步提升对时空数据的建模能力;
- 统一多模态数据: 单图片 -> 统一图片和视频,统一框架处理图片和视频数据,进一步提升对真实世界认知和理解能力;
- 训练数据: 1.4B -> 1.4T,数据量提升了3个量级,同时数据覆盖了多领域任务。
3.1 原生动态分辨率(Naive Dynamic Resolution)
Qwen-VL使用的视觉编码器是标准的ViT,这要求输入的图片要统一处理成单一的、固定的分辨率,才能feed到模型进行处理。一般标准的预训练好的ViT,通常是将图片处理成正方形(长:宽=1:1)。这样处理后通常图片会失真,导致模型理解上有信息损失或引入一些误导。
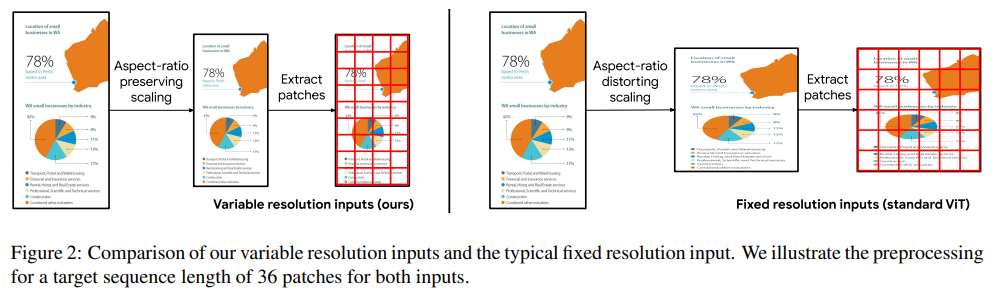
右侧是传统的ViT对输入的处理(也是Qwen-VL采用的方法),对于一些宽高比差距较大的图片,处理后通常会造成图片扭曲,而Qwen2-VL实现的原生动态分辨率方法则会保留原始图片的宽高比,将图片resize到适当的大小,图片像素满足 [min_pixel, max_pixel] 区间,再对图片做Patch处理,将每个图片处理成变长的Vision token序列,再输入给LLM模型。目前看上述的方法是比标准的ViT更合理的,因为它保留了图片的原始分辨率。
那么原生动态分辨率方法具体是怎么实现的呢? **核心方法是采用了NaViT的Patch n’ Pack技术,把不同图像的多个patch打包到一个序列,能保留不同图片的可变分辨率。同时在一个次序列计算中同时可处理多个图像,提升了模型计算的吞吐,在性能上始终优于传统的ViT。**其性能提升主要来源于Pack处理后,一个序列包括多个图片能同时计算,使得在固定计算预算下,动态分辨率方法能训练更多样本,从而带来更好的性能。
ViT引入2D-RoPE位置编码:在Qwen2-VL系列的ViT网络中,并没有沿用Qwen-VL的2D绝对位置编码,而是引入了2D-RoPE相对位置编码。之所以引入2D-RoPE,我个人理解主要考虑Qwen2-VL系列处理的图片Patch是变长的,对于超长的一些位置,如果采用绝对位置编码,由于数据稀疏性, 并不能得到充分训练。但RoPE本身是具有一定的外推性,对长序列建模有更好的泛化能力。
3.2 输入投影层:压缩Vision token + MLP Adapte
Qwen-VL在输入投影层做了Vision token的压缩处理,是采用了Cross-Attention的架构,通过一个组可学习的Query向量来压缩原始的特征序列。那么Qwen2-VL为什么没有继续沿用Cross-Attention的架构?
这里主要是因为Cross-Attention架构适合处理固定长度的 k, v ,当 k, v 长短不一时,是不适合做Attention计算的。而Qwen2-VL通过原生动态分辨率方法处理的每个图片的token序列恰恰是变长的,无法使用Cross-Attention架构做特征压缩处理。
Qwen2-VL采用了一种更简单的压缩方法:对空间位置临近的patch 特征做拼接,再经过2层MLP线性变换,这样将原来长度为 n的序列,可压缩到 n/4 ,最终将压缩后的特征序列输入给LLM模型。处理过程如图所示:
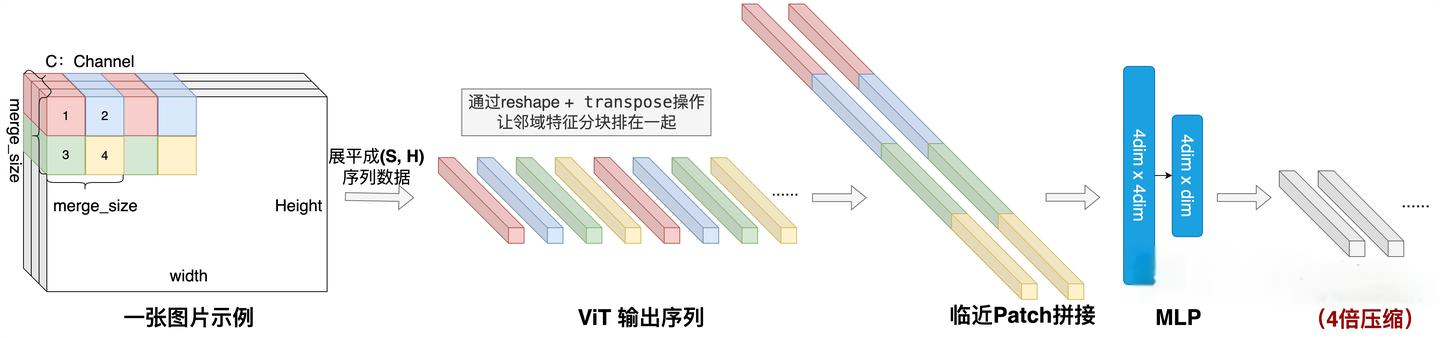
为了区分Vision token和文本token,Qwen2-VL也引入了两个特殊的token <|vision_start|> 和 <|vision_end|> 来标识Vision token。

3.3 Multimodal Rotary Position Embedding (M-RoPE)
Qwen2-VL模型输入增加了视频模态,视频可以看做是在图片二维空间上,增加了时序维度,是三维时空分布的数据: (Temporal, Height, Width),M-RoPE将位置编码信息从1维扩展到了3维,这样就能清晰刻画视频模态数据时空位置信息。对于文本(一维)和图像(二维)的数据如何统一表示成3维的位置ID呢?处理也比较简单直接:
- 文本:因为文本是一维空间序列,三个维度的值保持一致,也就退化成1D-RoPE。
- 图像:图像只有宽高两个维度,所以对于一张图片,时序维度T的位置始终保持固定。
对于混合多模态数据,每个模态的起始position ID是前面模态三维位置ID中取最大的ID并加1得到。
有了三维的位置,最终怎么映射成3D-RoPE,映射方式类似与2D-RoPE,针对一个位置(x,y,z) ,对维度为 d 的输入向量分成三份,前一份向量用 x 的一维RoPE矩阵( Rx )处理,中间一份向量用 y 的一维RoPE矩阵( Ry )处理,最后一份向量用 z 的一维RoPE矩阵( Rz )处理,然后再将三份处理后的结果拼接在一起,就做完了3维的RoPE处理。M-RoPE处理流程,如图所示:

3.4 统一的图像和视频理解框架
Qwen2-VL统一了视频和图像的理解框架,能混合输入图像和视频数据进行理解。为了保证图片和视频的处理一致,对视频和图像分别做如下处理:
视频处理:以每秒两帧的速率对视频进行采样,最终可采样偶数个帧序列。对于长视频为了平衡序列长度和计算效率,通过动态调整每一帧的分辨率,将视频总token限制在16K以内。
图像处理:对图像做复制操作,使得单一图片,变成一个时序为2的帧序列。
使用3D的卷积对帧序列做特征抽取,如图所示,每两张图片为一组进行卷积操作抽取特征。这样通过将卷积核扩充了时序维度,可以进一步压缩序列长度,因此也能进一步提升模型处理更多帧的能力。
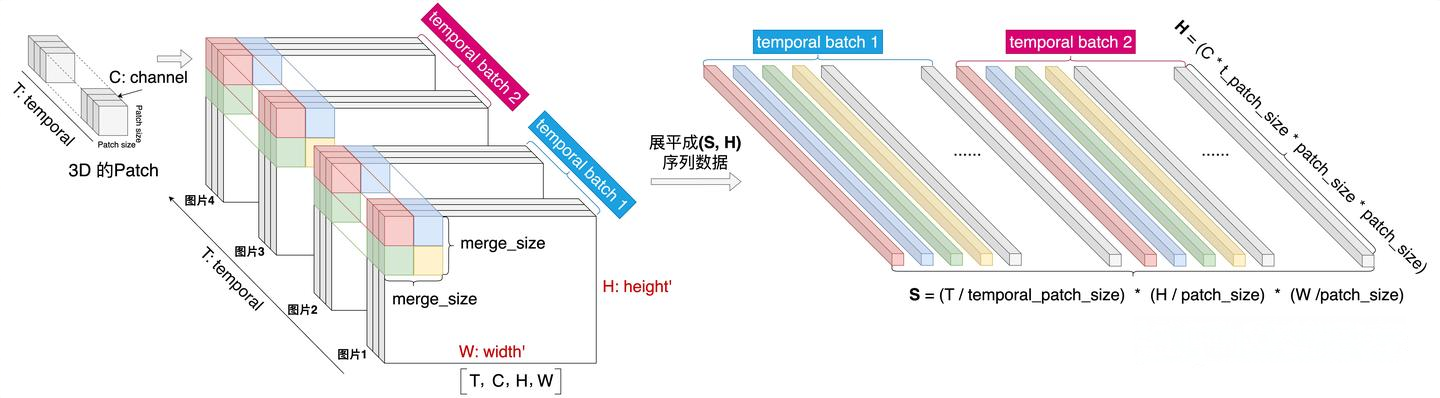
3.5 模型训练
Qwen2-VL采用了与Qwen-VL一致的三阶段训练方式。Qwen2-VL在训练数据上相比Qwen-VL做了大量的有价值的工作。
数据来源除了获取开源数据、经过清洗的网页数据,还做的大量数据合成的工作。数据涉及多种场景,包括图像-文本对,OCR数据,视觉问答数据,视频对话数据等多样化数据。
此外Qwen2-VL数据规模大幅提升,Qwen-VL整体训练样本1.4B左右,Qwen2-VL直接翻了3个量级达到了1.4T。通过大幅提升样本规模和样本多样性,使得Qwen2-VL的模型效果在多任务的评估中保持领先,也碾压了GPT-4o的效果。
4. Qwen2.5-VL
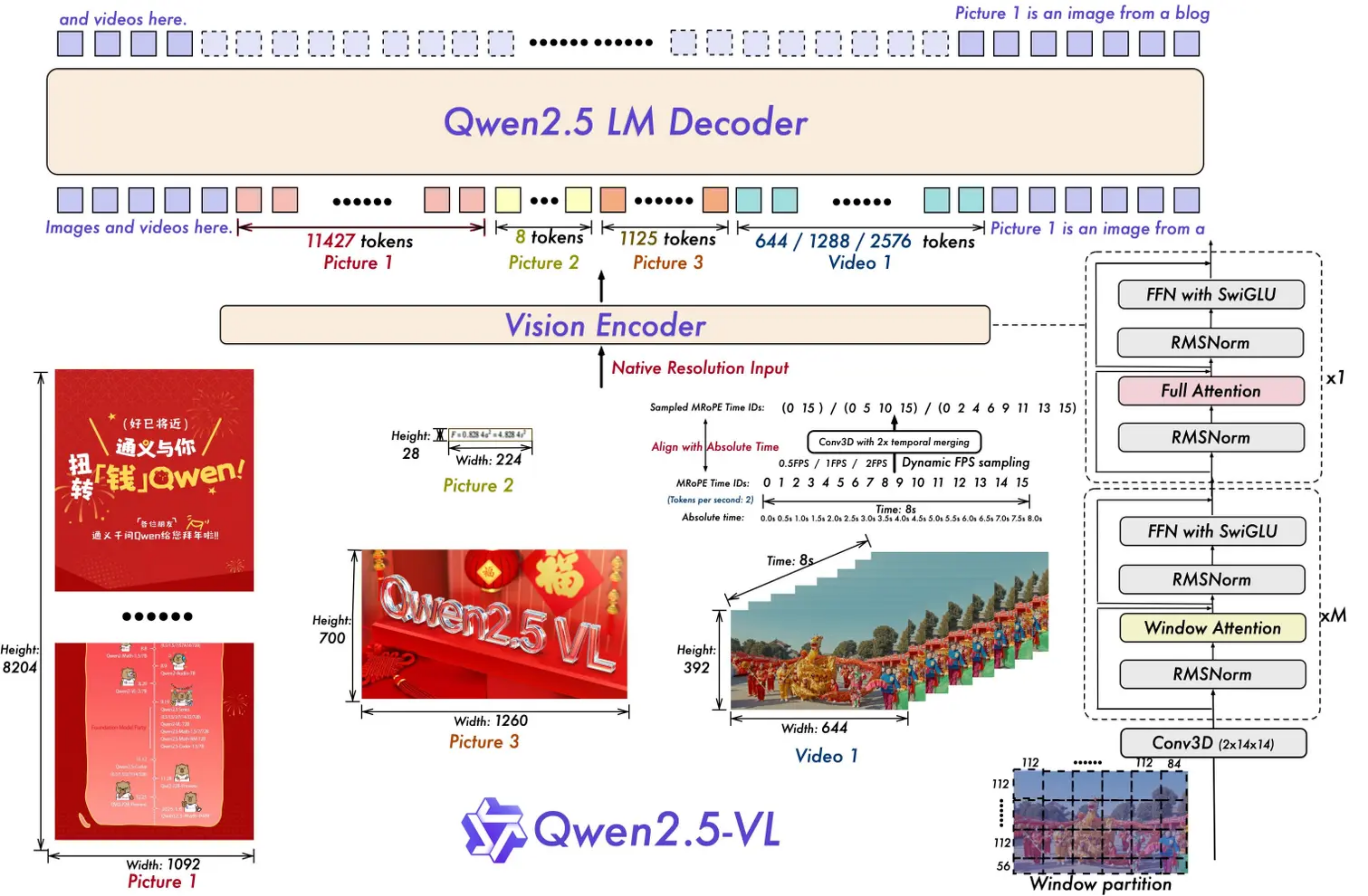
4.1 提升时间和空间的感知能力
空间感知能力: 我们在Qwen-VL中讨论过,在做一些grounding任务时,会将box的坐标点做 (0,1000) 的规范化处理,在2.5版本中,不进行坐标归一化,而是使用实际的像素点来表示坐标,这样能是模型学习到图像的真实尺寸信息。
时间感知能力:我们在Qwen2-VL的中讨论过,引入了一个M-RoPE三维的位置编码,在做时序维度的位置编码处理时,跟空间维度的位置编码是一致的:对于一个模态的起始位置的position ID,是相对于前面模态三维ID中最大的ID再加1得到。这对于时序维度的ID处理其实是不合理的,视频的时间是有绝对含义的,所以2.5对时间维度的位置ID,采用了绝对位置编码。同时也引入了动态帧的技术,每秒随机动态采集帧序列,使得模型能够通过不同时间ID的间隔,来学习时间的节奏。
4.2 更简洁高效的视觉编码器
- 从头训练了一个原生动态分辨率的 ViT。
- 引入了窗口注意力机制,有效减少了 ViT 端的计算负担。在 ViT 设置中,只有四层是全注意力层,其余层使用窗口注意力。最大窗口大小为 8×8,小于 8×8 的区域不需要填充,而是保持原始尺度,确保模型保持原生分辨率。
- 简化整体网络结构,ViT 架构与采用了 RMSNorm 和 SwiGLU 结构。
下一期:视觉-语言大模型VLM实践——保姆级教程
如果喜欢,欢迎关注作者的微信公众号:AIWorkshopLab



















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











