




 VisualChatGPT是一个集成系统,它接收用户对图像的复杂语言指令,如生成红花并转化为卡通风格。系统通过深度估计模型获取图像信息,然后使用深度到图像模型生成新图像,再利用风格迁移模型VFM将其转换成卡通。交互管理器协调ChatGPT与多个视觉基础模型的交互,确保理解并执行用户的指令。整个过程涉及图像处理、语言理解和模型迭代反馈,直至满足用户需求。
VisualChatGPT是一个集成系统,它接收用户对图像的复杂语言指令,如生成红花并转化为卡通风格。系统通过深度估计模型获取图像信息,然后使用深度到图像模型生成新图像,再利用风格迁移模型VFM将其转换成卡通。交互管理器协调ChatGPT与多个视觉基础模型的交互,确保理解并执行用户的指令。整个过程涉及图像处理、语言理解和模型迭代反馈,直至满足用户需求。
论文:https://arxiv.org/abs/2303.04671
代码:https://github.com/microsoft/TaskMatrix
一. 整体框架
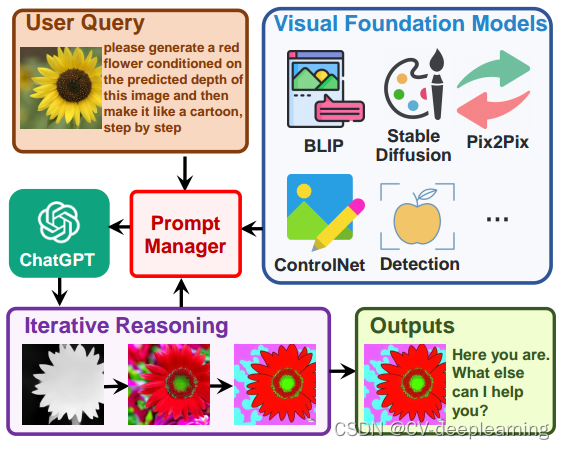
如图所示,用户上传一张黄花的图像并输入一个复杂的语言指令“请根据该图像的预测深度生成一朵红花,然后逐步使其像卡通一样”。
在交互管理器的帮助下,Visual ChatGPT 开始了相关视觉基础模型的执行链。 在示例条件下,它首先应用深度估计模型来检测深度信息,然后利用深度到图像模型生成带有深度信息的红色花朵图形,最后利用基于稳定扩散模型的风格迁移VFM来改变这个形象的风格变成了卡通。
在上述管道中,交互管理器作为ChatGPT的调度器,提供视觉格式类型并记录信息转换过程。
最后,当Visual ChatGPT从交互管理器获得“卡通”提示时,它将结束执行管道并显示最终结果。
整个系统流程是
- 明确告诉 ChatGPT 每个 VFM 的能力并指定输入输出格式;
2)将不同的视觉信息,例如pngimages,深度图像和mask矩阵,转换为语言格式以帮助ChatGPT理解; - 处理不同视觉基础模型的历史、优先级和冲突。
在交互管理器的帮助下,ChatGPT可以利用这些VFMs并以迭代的方式接收他们的反馈,直到它满足用户的要求或达到结束条件。
二. 流程示例
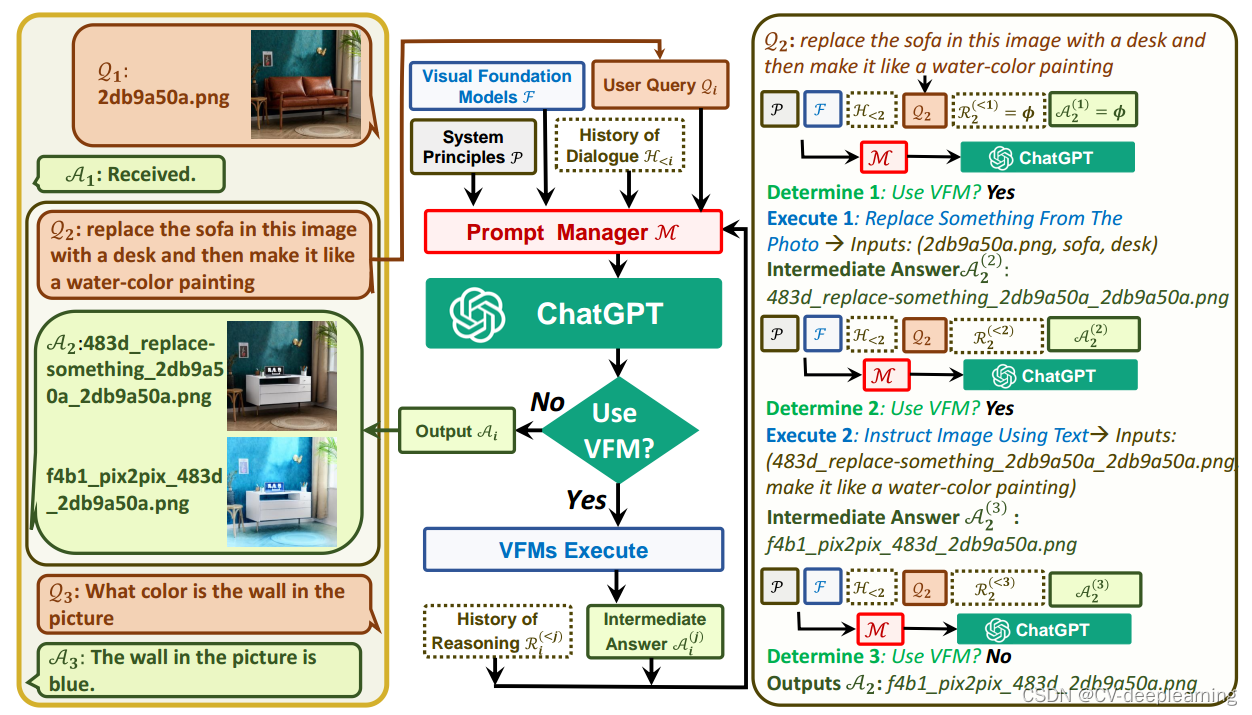
上图是Visual ChatGPT的框架图,左边展示了3轮对话;中间部分展示了Visual ChatGPT如何迭代地调用Visual Foundation Models并提供答案;右侧展示了QA的详细流程。




















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











