




自监督学习(Self-Supervised Learning, SSL)是一种机器学习方法,它通过利用未标注的数据自动生成标签来训练模型。与传统的监督学习需要大量标注数据不同,自监督学习通过从数据本身中提取结构化的知识,消除了对人工标注数据的依赖。通过这一过程,模型能够学习到有用的特征表示,通常可以用于图像分类、语音识别、自然语言处理等各种任务。
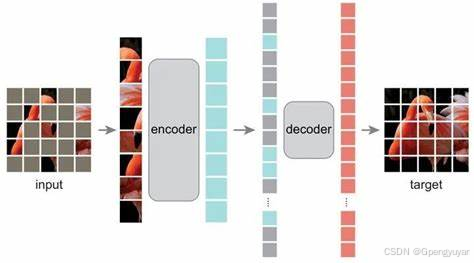
自监督学习的基本思想:
自监督学习的核心是“自我生成标签”。它并不是依赖人工标注数据集,而是通过设计特定的任务,强迫模型从未标注的数据中自己构造目标(标签)进行训练。这些任务通过数据变换、遮挡、预测等方式,使模型能够从数据本身学习出深层的结构和规律。
自监督学习的核心流程:
-
构造伪标签:自监督学习的第一步是从数据本身生成伪标签。伪标签并非人工提供的标签,而是通过对数据进行某些变换或遮挡,构造出需要预测的目标。例如,在图像中遮挡掉一部分区域,让模型预测该区域内容,或在文本中遮挡一个单词,预测这个单词是什么。
-
设计预任务(Pretext Tasks):预任务是自监督学习中的关键。它通过设计一种任务,让模型通过输入数据学习有意义的特征。常见的预任务有图像重建、预测图像变
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









